[논문 Review] VGGNet
VGGNet이 제안한 깊은 CNN 구조가 이미지 분류 성능에 어떻게 기여하는지 정리했습니다.
들어가며
이번 논문 리뷰는 VGGNet의 기반이 된 논문인 Very Deep Convolutional Networks for Large-Scale Image Recognition 논문을 읽고 요약 정리했습니다. 이 논문은 Oxford의 Visual Geometry Group에서 제안한 CNN 구조로, 깊이가 깊을수록 성능이 좋아진다는 점을 정량적으로 입증한 고전적 연구입니다.
핵심 키워드
- Deep Convolutional Network: 여러 개의 convolution layer를 쌓은 깊은 구조의 신경망
- Receptive Field: 한 뉴런이 입력 이미지에서 영향을 받는 영역
- 3x3 Convolution: 작은 커널을 반복적으로 적용하여 receptive field를 점진적으로 확장
- VGGNet: 깊이가 16~19층에 이르는 대표적인 CNN 구조
- ImageNet: 대규모 이미지 데이터셋, 모델 성능을 평가하기 위한 벤치마크
- Localization / Classification: 객체 인식의 두 가지 핵심 과제
I. Introduction
본 논문은 Convolutional Neural Network(CNN) 구조에서 깊이(depth)가 이미지 인식 성능에 어떤 영향을 미치는지를 실험적으로 분석한다. 특히, 작은 3x3 필터를 반복적으로 적용하여 깊은 구조의 네트워크를 구성하는 것이 기존 모델보다 훨씬 뛰어난 성능을 낼 수 있음을 강조한다.
기존의 CNN 모델들은 보통 크고 복잡한 필터를 사용하는 얕은(shallow) 구조에 머물러 있었다. 그러나 이 논문에서는 작고 단순한 필터(3x3)를 반복적으로 쌓아 네트워크의 깊이를 16~19층까지 증가시키는 접근을 제안한다.
(이러한 구조를 통해 다음과 같은 이점을 확인)
- 더 깊은 네트워크일수록 더 높은 정확도를 달성할 수 있음
- 모델 구조를 단순화하고도 성능은 유지 혹은 개선
- ImageNet 대회에서 Classification 2위, Localization 1위의 성과를 거둠
VGGNet은 이후 등장한 다양한 CNN 모델(AlexNet, ResNet 등)의 구조적 기반이 되었으며,
지금까지도 이미지 인식, 전이학습, 백본 네트워크 등 다양한 분야에서 활용되고 있다.
II. ConvNet Configurations
이번 섹션에서는 VGGNet의 구조 설계 원칙과 네트워크 깊이에 따른 성능 향상에 대해 설명한다.
2-1 Architecture
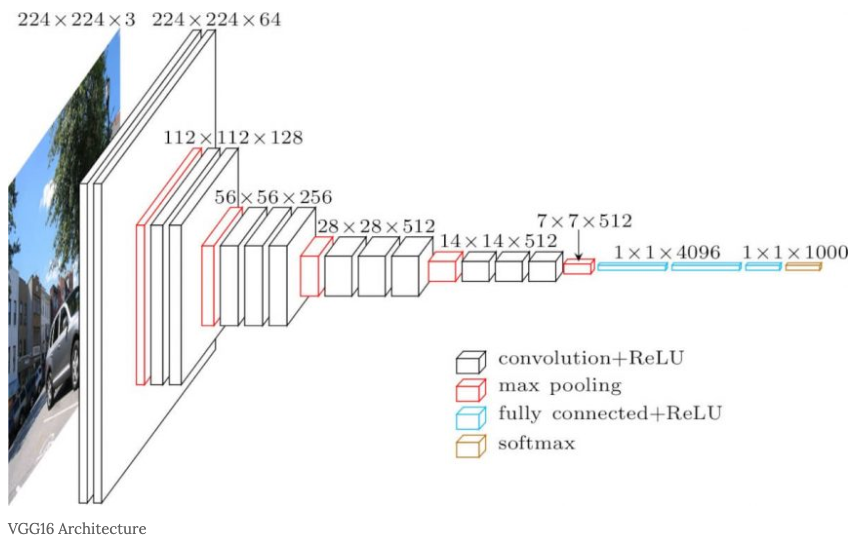
VGGNet은 224×224 크기의 RGB 이미지를 입력으로 사용하며, 학습 전에 각 픽셀에서 훈련 세트의 평균 RGB 값을 빼는 전처리만 수행하며 전체 모델은 다음과 같은 특징을 가진다.
- 3×3 Convolution 필터를 반복적으로 사용해 receptive field를 점진적으로 확장
- 3×3을 두 번 → 5×5와 같은 효과
- 3×3을 세 번 → 7×7과 같은 효과
- Stride는 1, padding은 1로 설정 → feature map의 해상도 유지
- Max Pooling은 일부 Convolution 층 다음에 적용되며, 2×2 window, stride=2
- Fully Connected Layer는 3개로 구성됨
- 첫 두 FC: 4096 노드
- 마지막 FC: 1000 노드 (ImageNet 클래스 수)
- 최종적으로 softmax로 분류
모든 hidden layer에는 ReLU 활성화 함수가 사용되며, 대부분의 모델에서는 LRN은 사용되지 않는다.
2-2 Configurations
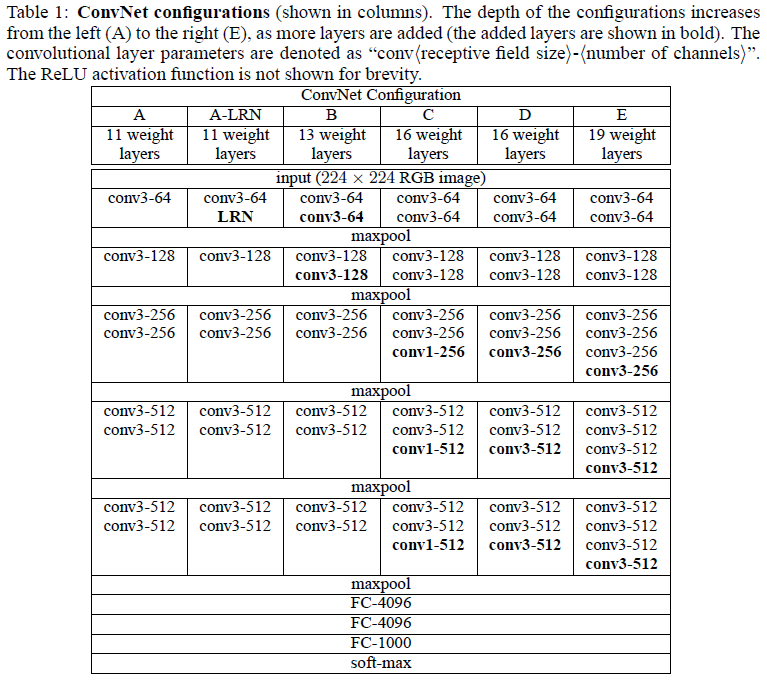
논문에서는 A~E까지 총 6가지 모델 구성을 실험했으며, 깊이에 따라 다음과 같이 구성된다.
- A: 11개 weight layer (8 conv + 3 FC)
- B: A에 LRN 추가
- C: 13개 weight layer
- D: 16개 weight layer (가장 널리 사용된 구성)
- E: 19개 weight layer

위 표에서는 parameter의 수를 나타내고 있으며 Network가 깊어진데 반해, parameter의 수는 크게 증가하지 않은 것을 확인 할 수 있다. 또한, Convolution layer의 채널 수는 처음 64에서 시작해 max-pooling을 지나며 128, 256, 512로 2배씩 증가한다.
2-3 Discussion
기존 ConvNet(Krizhevsky 등)의 구조와는 다음과 같은 차별점이 있다.
- 작은 필터 (3×3)를 여러 번 사용해 같은 receptive field를 구성하면서 계층을 깊게 구성
- 비선형성(ReLU)을 더 많이 적용할 수 있어 더 복잡한 함수 근사 가능
- 파라미터 수 감소: 예를 들어 7×7 필터는 49C² 파라미터가 필요하지만, 3개의 3×3 필터는 27C²만 사용
또한 일부 모델에서는 1×1 Convolution도 사용되는데, 이는 channel 간의 선형 결합을 수행하고 비선형성을 추가하는 데 유용하다.
III. Classification Framework
본 섹션에서는 VGGNet 모델의 학습 및 테스트 방법, 그리고 구현 세부사항에 대해 다룬다.
3-1 Training
VGGNet의 학습 전략은 전반적으로 AlexNet의 방식을 따르며, 다음과 같은 설정으로 진행되었다.
- Optimizer: SGD (Stochastic Gradient Descent)
- Batch size: 256
- Momentum: 0.9
- Weight decay: 5 × 10⁻⁴
- Dropout: 첫 번째와 두 번째 Fully Connected Layer에 적용 (비율: 0.5)
- Initial learning rate: 0.01 → validation accuracy가 개선되지 않으면 10배씩 감소
- Epochs: 총 74 (약 370K iterations)
학습 초기에는 깊지 않은 구조 A 모델을 무작위 초기화로 먼저 학습시킨 후,
나머지 더 깊은 구조(B~E)는 일부 레이어를 사전 학습된 가중치로 초기화해 안정적인 학습을 유도했다.
학습 데이터에는 random cropping, horizontal flipping, RGB color 등의 Data augmentation이 적용되었다.
3-2 Testing
테스트 단계에서는 다음과 같은 절차로 분류를 수행한다.
- 입력 이미지 리사이즈
- 입력 이미지는 비율을 유지한 채로, 테스트 해상도 Q로 isotropic rescaling됨
- 학습 시 사용된 해상도 S와는 다를 수 있음
- Fully-Connected → Convolution 변환
- 기존 FC layer를 convolution layer로 변환하여 dense하게 전체 이미지에 적용 가능
- 첫 번째 FC → 7×7 conv. layer
- 나머지 두 FC → 1×1 conv. layer
- 기존 FC layer를 convolution layer로 변환하여 dense하게 전체 이미지에 적용 가능
- 전체 이미지에 적용
- 변환된 fully-convolutional network는 crop 없이 전체 이미지에 적용됨
- Class Score Map 생성 및 처리
- 이미지의 공간 정보를 반영한 class score map이 생성됨
- 해당 score map은 sum pooling 방식으로 공간적으로 평균 처리되어 고정된 크기의 class score 벡터로 변환됨
- Test-Time Augmentation (TTA)
- 테스트 이미지에 좌우 반전(horizontal flip)을 적용한 결과도 모델에 입력
- 원본과 반전 이미지의 softmax 출력을 평균 내어 최종 결과 도출
이 방식은 crop을 여러 번 뽑아 테스트하는 방식보다 효율적이며 더 넓은 context를 반영할 수 있다는 장점이 있다.
3-3 Implementation Details
- C++ 기반 프레임워크
- VGGNet의 구현은 C++ 기반 Caffe 오픈소스 프레임워크를 기반으로 하되,
- 다중 GPU 학습 및 전체 이미지에 대한 multi-scale 학습/평가를 위해 여러 가지 수정 사항이 추가됐다고 한다.
- 멀티 GPU 학습 방식
- 각 mini-batch를 여러 개의 GPU에 나누어 병렬로 처리
- 각 GPU에서 계산된 gradient는 평균을 내어 최종 gradient로 사용
- gradient 계산은 동기식(synchronous) 으로 이루어져, 결과는 단일 GPU에서 학습한 것과 동일
- 성능 개선
- Krizhevsky(2014) 방식처럼 모델/데이터 병렬화 구조는 사용하지 않았지만,
- 단순한 데이터 병렬 방식만으로도 4 GPU 시스템에서 약 3.75배 속도 향상
- 하드웨어: NVIDIA Titan Black GPU 4장 구성
- 학습 시간: 아키텍처에 따라 2~3주 소요
IV. Classification Experiments
본 섹션에서는 VGGNet 아키텍처가 ILSVRC-2012 데이터셋에서 달성한 이미지 분류 성능을 제시한다.
4-1 Single Scale Evaluation
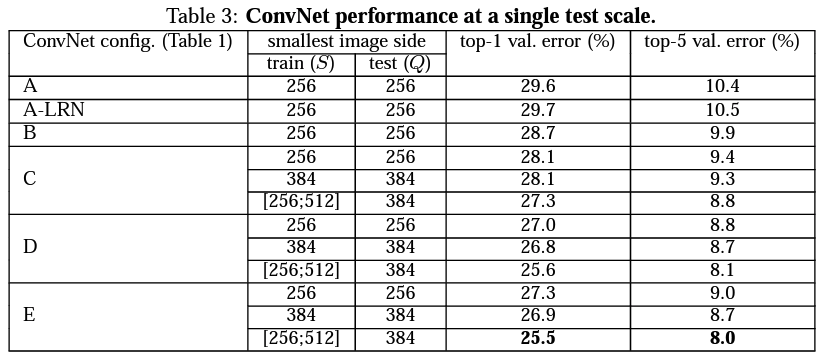
- 단일 스케일 평가 결과, ConvNet 깊이가 깊을수록 성능이 향상됨 (A: 11층 → E: 19층)
- 3×3 필터를 반복적으로 사용한 구조는 1×1 또는 5×5 필터보다 더 나은 성능을 보임
- LRN(Local Response Normalization)은 성능 향상에 기여하지 않아 사용하지 않음
- 스케일 지터링(S ∈ [256, 512]) 기반 학습은 고정 스케일(S=256 또는 384)보다 더 우수한 결과를 달성함
4-2 Multi-Scale Evaluation
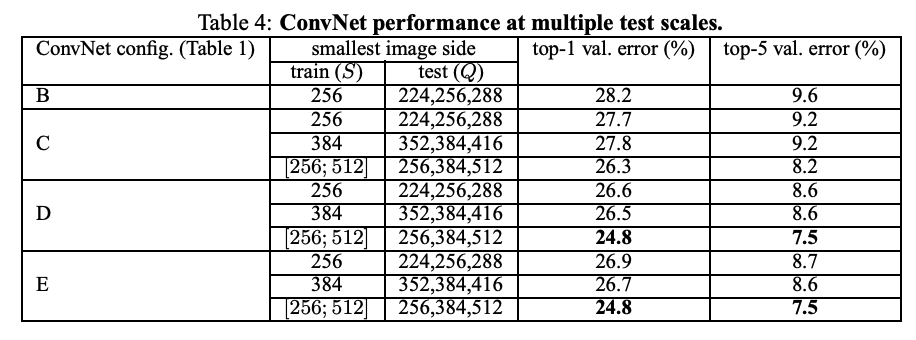
- 테스트 시 다양한 크기(Q)로 이미지를 리사이즈하여 평가
- 각 크기별 softmax 출력을 평균하여 최종 예측 생성
설정 기준
- 고정 스케일 학습 모델:
Q = {S-32, S, S+32} - 지터링 학습 모델 (
S ∈ [256, 512]):Q = {256, 384, 512}
결론
- 테스트 단계에서도 스케일 지터링을 적용하면 정확도 상승
- 깊은 네트워크(D, E)가 더 좋은 성능
- 단일 스케일보다 멀티 스케일 평가가 더 효과적
4-3 Multi-Crop Evaluation
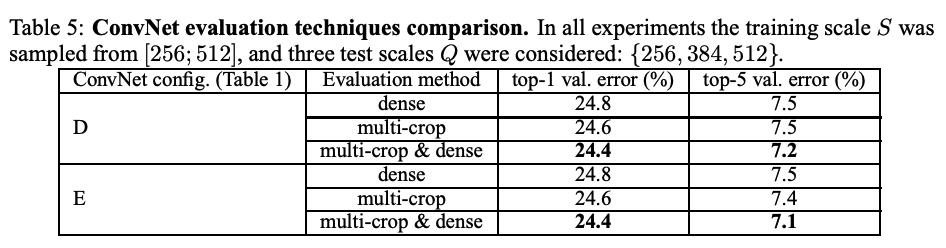
- 여러 개의 이미지 crop을 모델에 입력하여 예측 결과를 평균
- softmax 출력 평균을 통해 최종 결과 도출
결론
- Multi-Crop 평가가 Dense보다 우수
- 두 방법의 결합이 가장 높은 정확도
- 서로 다른 경계 조건 처리 방식 → 보완적인 효과
4-4 ConvNet Fusion

이번에는 개별 ConvNet 모델의 성능을 평가한 후, 여러 모델의 softmax 출력을 평균하는 방식으로 앙상블 적용
모델 간 보완성(complementarity) 을 활용하여 성능을 향상시켰다고 한다.
- ILSVRC 제출 당시 구성된 앙상블 모델
- 단일 스케일 모델 + multi-scale 모델 D (FC layer만 fine-tuning)
- 총 7개 모델 앙상블, Test Top-5 Error: 7.3%
- 제출 이후 추가 실험
- Multi-scale 모델 D + E 앙상블
- Dense evaluation 시: 7.0%
- Dense + Multi-crop 평가 병합 시: 6.8%
- 참고: 단일 최고 성능 모델 (E) → 7.1%
- Multi-scale 모델 D + E 앙상블
4-5 Comparison with the State of the Art
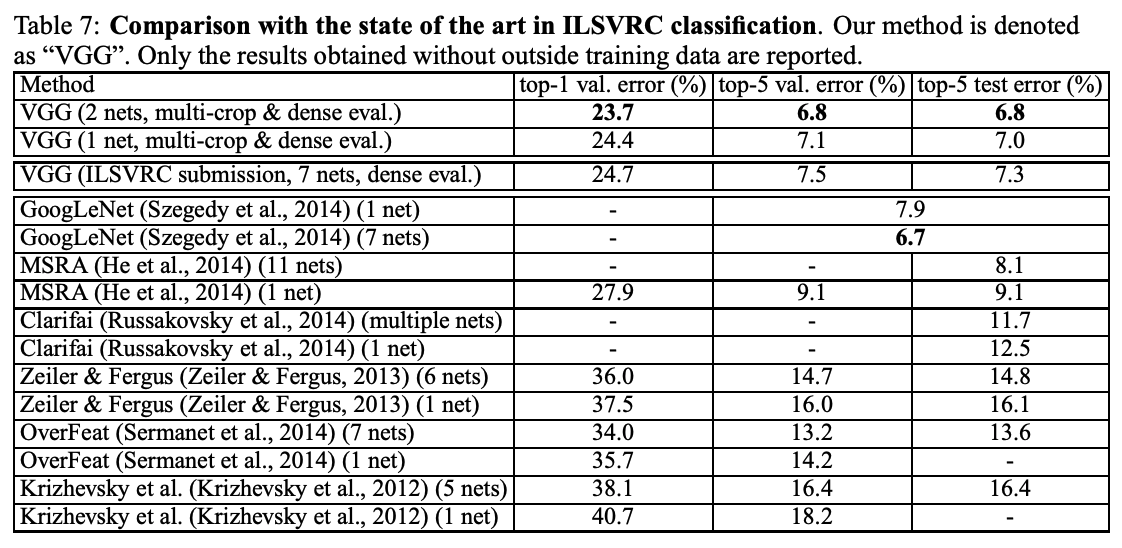
본 논문에서는 제안한 VGGNet 모델을 기존 대표 모델들과 비교 평가했다.
- ILSVRC-2014 분류 태스크 기준
- VGG팀: 2위, 7.3% (7개 모델 앙상블 기준)
- 이후 2개 모델 앙상블로 6.8%까지 오류율 감소
- 다른 모델과 비교
- GoogLeNet: 6.7% (다수 모델 조합)
- Clarifai (ILSVRC 2013 우승):
- 외부 데이터 사용 시: 11.2%
- 미사용 시: 11.7%
- 단일 모델 기준
- VGGNet이 단일 GoogLeNet보다 0.9% 낮은 오류율 (7.0%)
- 기존 ConvNet 구조에서 깊이만 증가시켜 성능 대폭 향상
요약
본 논문은 CNN 구조에서 depth 가 이미지 분류 성능에 미치는 영향을 분석한다. 전체 구조는 작은 크기의 3×3 필터를 반복적으로 쌓는 방식으로 구성되며, 깊은 네트워크일수록 더 좋은 성능을 나타낸다. (최대 19층) ILSVRC-2014 기준, VGGNet은 단일 모델 기준 최고 성능 (Top-5 Error: 7.0%) 을 기록
학습 전략: scale jittering, data augmentation, dropout, SGD 등 적용
평가 기법: Dense evaluation, Multi-crop, Multi-scale, 앙상블 등 활용하여 다양한 실험으로 성능 개선
핵심 결론: 단순히 필터 크기를 키우는 것보다, 작은 필터를 깊게 쌓는 것이 더 효과적이다.
Code 구현
아래는 논문에서 제안한 VGG 구조를 기반으로, VGG-16 전체 네트워크를 PyTorch로 구현한 코드입니다.
전체 코드는 GitHub 링크에서 확인할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
class VGG16(nn.Module):
def __init__(self, num_classes=10):
super(VGG16, self).__init__()
# VGG 핵심 아이디어: 여러 개의 작은 3x3 Conv 층을 반복적으로 쌓아 깊이 증가
self.features = nn.Sequential(
# Block 1
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block 2
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block 3
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block 4
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block 5
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# Fully Connected Layers (논문 기준 4096 → 4096 → class 수)
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1) # Flatten
x = self.classifier(x)
return x