[논문 Review] LeNet-5
LeNet-5 기법을 활용한 패턴 및 문서 인식 방법을 정리했습니다.

들어가며
이번 포스팅에서는 LeNet-5라고 알려져 있는 Gradient-Based Learning Applied to Document Recognition 논문을 읽고 요약 정리했습니다.
핵심 키워드
- Neural Networks : 인간의 뇌 구조를 모방한 연산 시스템, 입력,출력을 연결하는 신경망 구조를 학습에 활용
- OCR : 이미지나 문서 내의 문자 데이터를 인식하고 디지털 텍스트로 변환하는 기술
- Document Recognition : 문서 내의 텍스트, 구조, 레이아웃 등을 인식하여 이해하는 기술
- Machine Learning : 데이터를 이용해 기계가 스스로 패턴을 학습하고 예측하거나 분류하는 기술
- Backpropagation: 신경망 학습을 위해 오차를 거꾸로 전파하는 역전파 알고리즘을 의미
- Gradient-Based Learning : 손실 함수의 기울기를 계산해 모델의 파라미터를 업데이트하는 학습 방법
- Convolutional Neural Networks (CNN) : 이미지나 영상 데이터에 특화된 신경망 구조
- Graph Transformer Networks (GTN) : 복잡한 모듈 간의 관계를 그래프 구조로 모델링
- Finite State Transducers (FST) : 입력을 받아 상태를 전이시키고 출력을 생성하는 계산 모델
I. Introduction
본 논문은 전통적인 패턴 인식 시스템이 가지는 한계점을 지적하며, 사람이 설계하는 feature engineering 대신, 자동화된 학습(automatic feature learning) 을 통해 문제를 해결할 수 있음을 강조한다.
초기 패턴 인식은 수작업 feature extractor 와 일반화 가능한 classifier의 조합으로 구성되었다. 그러나 feature extractor의 설계는 과업별로 많은 시간, 노력을 요구하며, 설계자의 경험에 따라 성능이 좌우되는 문제가 있다.
논문에서는 두 가지 문제를 중심으로 접근하며 내용은 아래와 같다.
- Character recognition: 개별 문자를 인식하는 과제, 픽셀 수준에서 직접 학습하는 CNN 구조가 적합함을 설명
- Document understanding: 문장, 문서를 해석하는 과제, 통합된 모델인 GTN 를 통해 접근할 필요성을 제시
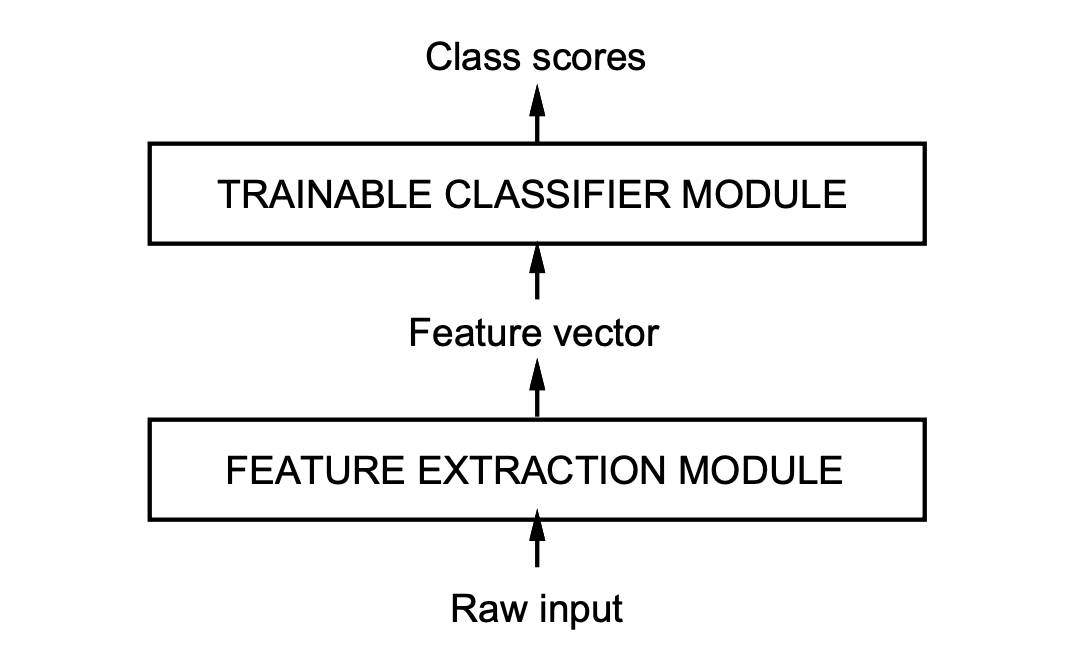 Feature Extraction Module과 Classifier Module의 조합
Feature Extraction Module과 Classifier Module의 조합
전통적 접근 방식의 한계와 변화
전통적인 feature engineering 방식은 문제마다 새로운 feature를 설계해야 했고, 이로 인해 높은 개발 비용과 제한된 확장성을 초래하였다. 특히 feature extractor의 성능이 인식 시스템 전체의 성능을 결정짓는 경우가 많아, 설계자의 역량에 과도하게 의존하는 문제가 존재, 이러한 한계를 극복할 수 있었던 배경은 다음과 같은 기술적 변화 때문이다.
컴퓨터 성능의 향상
고성능 하드웨어의 발전으로 복잡한 모델을 brute-force 방식으로 학습하는 것이 가능해졌다.대규모 데이터의 등장
다양한 실제 데이터를 활용하여, feature를 수작업으로 설계하지 않고도 자동으로 특징을 학습할 수 있게 되었다.효과적인 학습 알고리즘의 개발
Backpropagation 알고리즘을 이용해 다층 신경망을 학습시킬 수 있게 되면서, 고차원 데이터에 대한 패턴 인식이 현실화되었다.
본 논문은 이러한 기술적 변화를, 사람이 설계한 feature extractor에 의존하지 않고 데이터로부터 자동으로 특징을 학습하는 신경망 기반 시스템을 제안한다. 이를 통해 기존 패턴 인식 시스템이 가진 구조적 한계를 극복하고자 한다.
II. Convolutional Neural Networks for Isolated Character Recognition
본 섹션에서는 손글씨 인식 문제를 해결하기 위해 제안된 Convolutional Neural Network (CNN) 구조와, 이를 대표하는 모델인 LeNet-5의 구조를 다룬다.
기존의 패턴 인식 시스템은 수작업 feature extractor와 trainable classifier의 조합으로 이루어졌지만,
이 접근 방식은 다음과 같은 한계를 지녔다.
- 입력 이미지가 고해상도일 경우, feature extractor를 설계하고 학습하는 데 필요한 파라미터 수가 급격히 증가
- 입력 데이터에 약간의 변형(shift, scale, distortion)만 있어도 인식 성능이 급격히 저하
- Fully-connected network는 입력의 공간적 구조를 고려 ❌, 인접한 픽셀 간 관계를 학습하기 어렵다.
이러한 한계를 극복하기 위해 제안된 것이 바로 Convolutional Neural Network (CNN) 이다.
A. Convolutional Networks
CNN은 다음 세 가지 핵심 아이디어를 기반으로 설계되었다.
Local Receptive Fields
각 뉴런은 입력 이미지의 일부분만을 바라본다. 이를 통해 국소적(local) 특징을 추출할 수 있으며,
엣지(edge), 코너(corner) 등 저수준(low-level) 패턴을 감지할 수 있다.Shared Weights
동일한 feature를 이미지 전체에 적용할 수 있도록 가중치를 공유한다.
이 방법은 모델의 파라미터 수를 크게 줄여주고, 입력 데이터의 shift나 distortion에 대한 강인성을 높인다.Subsampling (Pooling)
feature map의 해상도를 조금씩 줄여서, 특징의 위치에 대한 민감도를 낮추고 모델의 일반화 성능을 높인다.
이러한 구조 덕분에 CNN은 입력 데이터의 구조를 효율적으로 학습할 수 있으며, 입력에 약간의 변형이 생기더라도 높은 인식 성능을 유지할 수 있다.
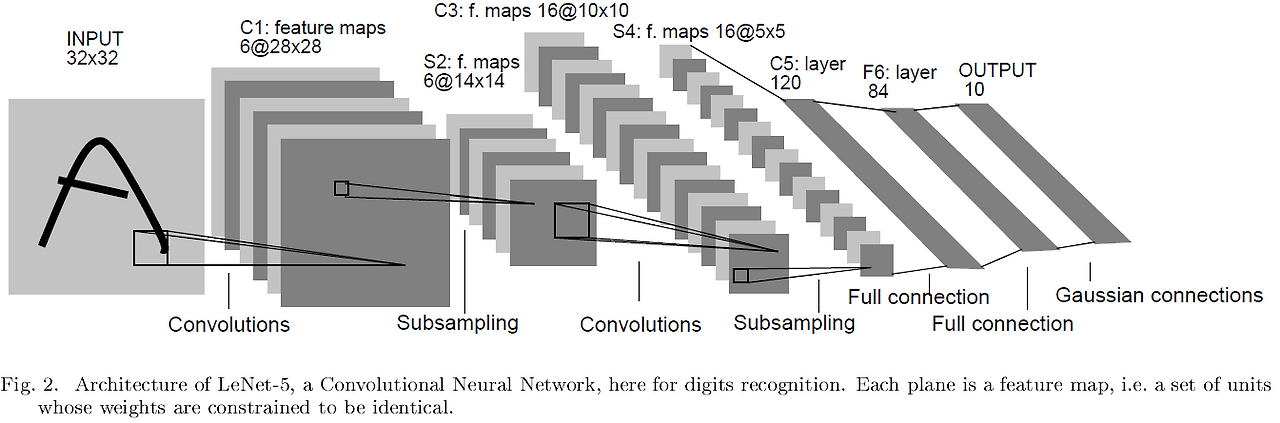
B. LeNet-5 Architecture
LeNet-5는 손글씨 숫자 인식(MNIST 등)을 목표로 설계된 대표적인 CNN 모델이다.
전체적인 구조는 다음과 같다.
- Input Layer: 32x32 크기의 normalized grayscale 이미지
- C1 Layer: 6개의 28x28 feature map을 생성하는 Convolution layer
- S2 Layer: 6개의 14x14 feature map을 생성하는 Subsampling (Average Pooling) layer
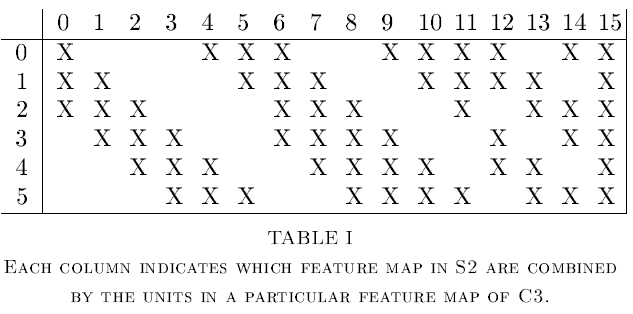
- C3 Layer: 16개의 10x10 feature map을 생성하는 Convolution layer
- S4 Layer: 16개의 5x5 feature map을 생성하는 Subsampling layer
- C5 Layer: 120개의 1x1 feature map (사실상 Fully Connected Layer로 동작)
- F6 Layer: 84개의 노드를 가진 Fully Connected Layer
- Output Layer: 10개의 Euclidean RBF 노드 (0~9 숫자 분류)
LeNet-5의 핵심 아이디어는 다음과 같다.
- 특징 추출과 압축을 반복하면서 점진적으로 고차원 feature를 학습한다.
- Shared weights를 통해 parameter 수를 줄이고, Pooling을 통해 위치 변화에 강인성을 가진다.
- 최종적으로 Fully Connected Layer를 통해 전체 feature를 종합하여 분류를 수행한다.
이 구조는 이후 발전된 다양한 CNN 아키텍처(예: AlexNet, VGGNet 등)의 기반이 되었으며,
딥러닝 기반 이미지 인식 기술 발전에 있어 중요한 전환점을 마련했다.
III. Gradient-Based Learning
본 섹션에서는 Gradient-Based Learning의 원리와 핵심 개념을 다룬다.
Gradient-Based Learning은 모델의 예측 결과와 실제 정답 간의 오차를 계산하고,
이 오차를 줄이기 위해 파라미터(parameter)를 미세 조정하는 학습 방법이다.
학습 과정은 다음과 같은 흐름으로 구성된다.
모델 출력
입력 패턴에 대해 모델이 예측 결과(output)를 생성Loss 계산
모델의 예측 결과와 실제 정답 간의 오차(loss)를 계산 (예: Mean Squared Error, Cross Entropy 등)Gradient 계산
오차를 줄이기 위해 각 파라미터가 어느 방향으로, 얼마나 변화해야 하는지를 나타내는 gradient를 계산파라미터 업데이트
계산된 gradient를 이용하여 파라미터를 업데이트 가장 기본적인 업데이트 방법은 Gradient Descent이다.
A. 학습 목표
학습의 목표는 전체 training dataset에 대해 평균적인 오차를 최소화하는 것이다.
Loss function을 E(W)라 할 때, 학습은 다음과 같은 최적화 문제를 푸는 것과 같다.
여기서 W는 모델의 trainable parameters를 의미한다. 하지만 실제로 중요한 것은 training data에서의 성능만이 아니라, test data에 대해서도 오차를 줄이는 것, 즉 일반화를 달성하는 것이다. 이를 위해 Structural Risk Minimization이라는 개념이 등장한다.
- 모델의 복잡도(h)가 낮을수록 train/test 간 오차 차이가 줄어든다.
- 너무 복잡한 모델은 training set에서는 오차가 낮지만, unseen data에서는 성능이 저하될 수 있다.
B. Gradient Descent와 Backpropagation
Gradient Descent는 가장 기본적인 최적화 알고리즘으로, Loss function의 gradient를 따라 parameter를 업데이트하여 점진적으로 loss를 줄여간다. 파라미터 업데이트 식은 다음과 같다.
\[W := W - \epsilon \nabla E(W)\]여기서
- epsilon은 learning rate를 의미하며,
- nabla E(W)는 loss function에 대한 W의 gradient이다.
보다 복잡한 모델에서는 각 층(layer)마다 gradient를 계산해야 하는데,
이 때 필요한 것이 바로 Backpropagation Algorithm이다. Backpropagation은 Chain Rule(연쇄 법칙)을 이용하여, 출력층에서 입력층으로 거꾸로 gradient를 효율적으로 전파하여 모든 파라미터의 업데이트 방향을 계산한다.
이를 역전파 알고리즘이라고 부른다.
C. Stochastic Gradient Descent (SGD)
전통적인 Gradient Descent는 전체 training set에 대해 gradient를 계산하지만, 이 방식은 데이터셋이 클 경우 계산량이 매우 커진다. 이를 해결하기 위해 Stochastic Gradient Descent (SGD) 방법이 제안되었다.
- 데이터 샘플 하나 또는 작은 mini-batch에 대해 gradient를 계산하고 즉시 파라미터를 업데이트한다.
- 이 방법은 계산량을 줄이고, 더 빠른 수렴을 가능하게 한다.
- 다만 업데이트에 noise가 포함되기 때문에, 수렴 과정에 진동이 발생할 수 있다.
Gradient-Based Learning은 CNN을 비롯한 다양한 신경망 구조의 학습을 가능하게 만든 핵심 기반 기술이며, 특히 Backpropagation 알고리즘은 심층 신경망의 학습을 실용적으로 만든 주요 요인 중 하나이다. 학습 과정에서 Training Error와 Test Error가 어떻게 감소하는지를 아래 그래프를 통해 확인할 수 있다.
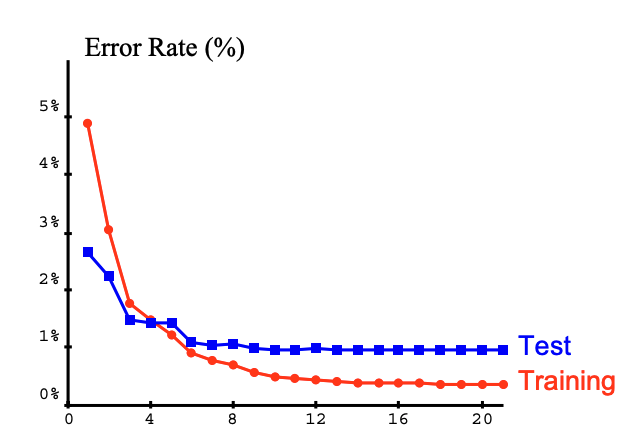 Training Set Iterations에 따른 Error Rate 변화
Training Set Iterations에 따른 Error Rate 변화
IV. Learning in Real Handwriting Recognition Systems
본 섹션에서는 실제 손글씨 인식 문제에 Gradient-Based Learning과 CNN 구조를 적용한 사례를 다룬다.
손글씨 인식 문제는 단순히 문자 하나를 인식하는 문제에 그치지 않고, 문장이나 문서 수준에서 segmentation이라는 추가적인 과제를 포함한다. Segmentation은 연속된 글자 스트림에서 각 문자를 올바르게 분리해내는 작업이다.
전통적인 방법은 다음과 같은 과정을 거쳤다.
- Heuristic Over-Segmentation
- 가능한 모든 분할 지점을 탐색하여 후보를 생성하고,
- Recognizer
- 생성된 후보 중 최적의 조합을 선택하는 구조로 작동하였다.
그러나 이 방식은 다음과 같은 한계를 가진다.
- segmentation 품질에 강하게 의존 → 잘못 분리되면 인식 실패
- 후보군이 많을 경우 최적 조합을 찾는 데 연산량 급증
- 오류가 발생해도 정확한 레이블링(labeling)이 어려워, 인식기 학습이 힘듬
전통적인 segmentation 기반 방법은 다양한 형태의 손글씨를 다루기에 한계가 있었다.
아래는 실제 훈련 데이터에 등장하는 다양한 왜곡의 예시이다.
 실제 손글씨 데이터에서 발생하는 다양한 변형 예시
실제 손글씨 데이터에서 발생하는 다양한 변형 예시
CNN 기반 접근 방식의 이점
논문에서는 CNN 기반 인식기(recognizer)를 활용하여, feature를 자동으로 학습하고, segmentation에 의존하지 않고도 전체 단어 또는 문서를 인식하는 접근을 제안한다.
이 방식의 핵심은 다음과 같다
- feature extractor와 classifier를 통합하여, 입력 이미지에서 직접적으로 특징을 추출하고 분류
- segmentation 오류에 대한 민감도를 낮추어, 보다 견고한 인식이 가능
- 전체 시스템을 end-to-end로 학습시켜, feature와 classifier를 동시에 최적화
이를 통해, 기존 heuristic 기반 시스템 대비 손글씨 인식 성능을 크게 향상시킬 수 있었다.
또한 데이터 레이블링 비용과 segmentation 오류를 줄이는 데에도 실질적인 이점을 제공하였다.
요약
이 논문은 전통적인 패턴 인식 방식(수작업 feature 설계 + classifier 조합)이 가진 한계를 지적하며, 사람이 직접 feature를 설계하는 대신, 데이터로부터 특징을 자동으로 학습하는 방법을 제안한다.
이를 위해 Convolutional Neural Network (CNN) 구조를 도입하고, Gradient-Based Learning (특히 Backpropagation) 을 통해 네트워크를 학습시킨다.
CNN은 입력 이미지의 국소적(local) 특징을 효과적으로 추출하며, Pooling 과정을 통해 위치 변화나 왜곡에도 강인한 특성을 확보할 수 있다.
논문에서는 이러한 CNN 구조를 손글씨 인식 문제에 적용하여, 전통적인 segmentation 기반 방식에 비해 뛰어난 성능을 달성했음을 보여준다.
결국, 사람이 feature를 일일이 설계하지 않아도, 데이터와 Gradient 기반 학습만으로 효과적인 인식이 가능하다는 사실을 실험을 통해 입증한 연구다.
Code 구현
위 논문에서 제안한 LeNet-5 모델 구조를 기반으로, MNIST 데이터셋 분류를 위한 코드를 짧게 구현해봤습니다.
전체 코드는 GitHub 링크에서 확인 할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# Library
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import warnings
from torch.utils.data import DataLoader
# LeNet-5 Model
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5) # (1, 32, 32) -> (6, 28, 28)
self.pool = nn.AvgPool2d(2, 2) # (6, 28, 28) -> (6, 14, 14)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5) # (6, 14, 14) -> (16, 10, 10)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = torch.tanh(self.conv1(x))
x = self.pool(x)
x = torch.tanh(self.conv2(x))
x = self.pool(x)
x = x.view(-1, 16*5*5)
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
x = self.fc3(x)
return x
[Epoch 1/5] Loss: 0.2929 [Epoch 2/5] Loss: 0.0955 [Epoch 3/5] Loss: 0.0632 [Epoch 4/5] Loss: 0.0474 [Epoch 5/5] Loss: 0.0386 Test Accuracy: 98.41%
