[Internship] - 1달차
[Internship] - 1달차 회고

들어가며
스타트업 인턴십 1달차에 대한 회고
1. Image Model Fine-tuning
LoRA Fine-tuning(Realistic) 업무를 담당하며 배운점을 요약 정리한 내용
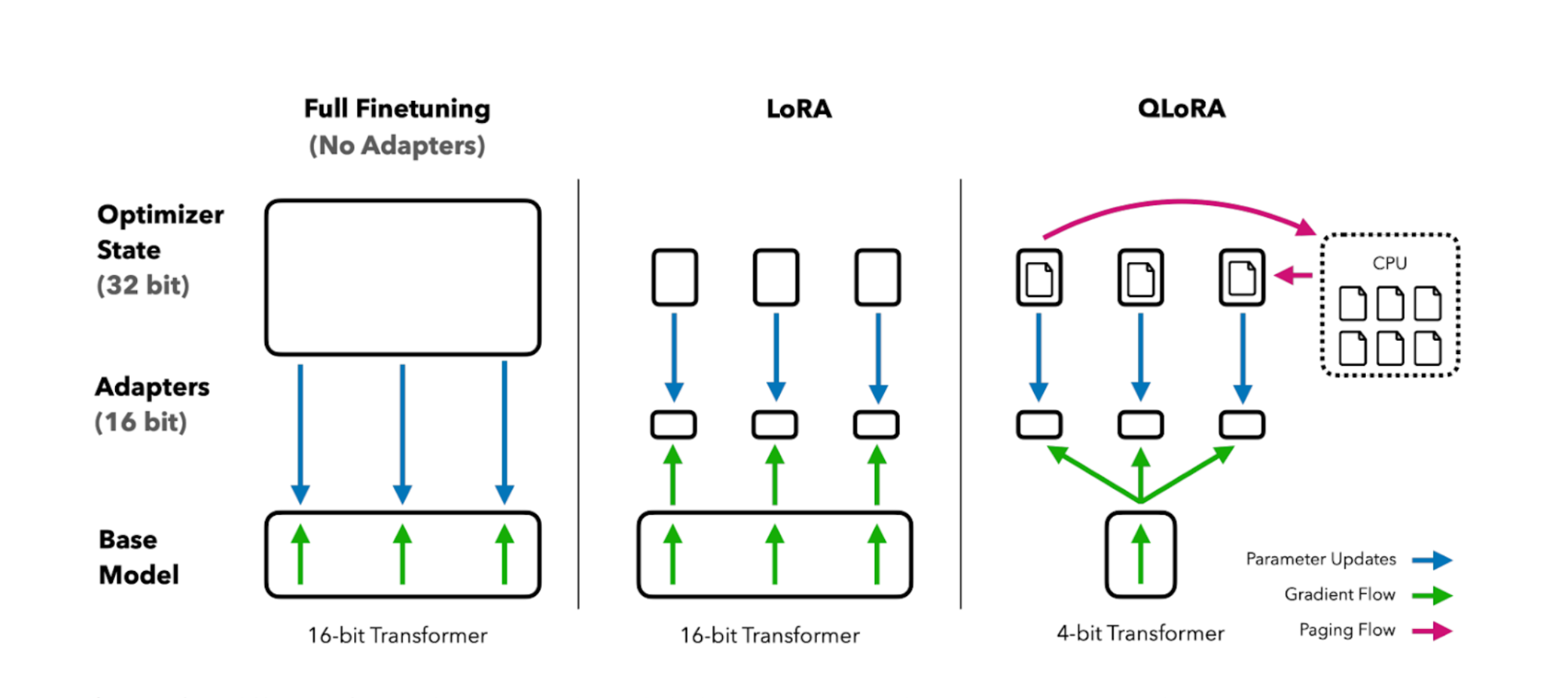 LoRA & QLoRA
LoRA & QLoRA
LoRA (Low-Rank Adaptation) Fine-tuning
- 원본 모델의 모든 파라미터를 업데이트하지 않고 저차원 행렬로 변화량만 학습
- 원본 모델은 freeze, adapter만 학습하여 동일한 효과를 얻는 기법
QLoRA
- LoRA + Quantization을 결합한 더욱 메모리 효율적인 기법
- 4-bit quantization을 통해 모델 크기를 대폭 줄이면서도 LoRA adapter 학습
- GPU 메모리를 75% 이상 절약하면서도 Full Fine-tuning과 유사한 성능 달성
- 일반 LoRA 대비 2-4배 메모리 효율적이지만 약간의 정확도 trade-off 존재
Quantization(양자화) 란?
- 고정밀도 수치를 낮은 정밀도로 변환하여 모델 크기와 연산량을 줄이는 기법
- 32-bit 부동소수점 → 8-bit 정수 또는 4-bit 정수로 변환
- 모델 크기 대폭 감소: 75~87% 메모리 절약 가능
- 추론 속도 향상: 낮은 정밀도 연산으로 더 빠른 처리
- 성능 trade-off: 정밀도 손실로 인한 약간의 정확도 저하
QLoRA 적용 시 VAE(Variational Autoencoder) 부분에는 Quantization을 적용하면 안된다.
VAE는 이미지 인코딩/디코딩을 담당하는 핵심 컴포넌트로, 정밀도 손실이 이미지 품질에
직접적 영향을 미친다. 그렇기에 UNet 부분만 quantization 적용하고 VAE는 원래 정밀도를
유지해야 안정적인 학습과 고품질 결과를 얻을 수 있다.
2. Language Model Fine-tuning
Language Model Fine-tuning(Translation) 업무를 담당하며 배운점을 요약 정리한 내용
 LoRA & QLoRA
LoRA & QLoRA
SFT (Supervised Fine-tuning) for Translation
- Korean-English parallel corpus를 활용한 지도 학습 방식
- Instruction format으로 구성된 번역 데이터셋으로 학습
- input-output 쌍이 명확한 structured training 진행
보통
.jsonl확장자로 사용해서 학습함1 2 3 4 5 6
# ex: Instruction-based SFT Format { "instruction": "다음 한국어 문장을 자연스러운 영어로 번역하세요:", "input": "안녕하세요, 반갑습니다.", "output": "Hello, nice to meet you." }
LLM Fine-tuning (LoRA)
- Tokenization (토큰화)
- 토큰화는 자연어 처리에서 텍스트를 작은 단위로 나누는 과정을 말한다.
- 이 과정은 보통 단어, 형태소 등을 텍스트에서 추출하여 분리하는 작업을 포함함
- 해당 과정은 모델이 텍스트를 이해할 수 있도록 적절한 입력 형태로 변환하는 역할을 한다.
- Tokenizer (토크나이저)
- Tokenizer는 텍스트를 토큰으로 분할하는 도구나 알고리즘을 말함.
- 주어진 텍스트를 토큰 단위로 쪼개고, 각각의 토큰을 해당하는 token_ids(정수 ID)로 변환
- 즉, 문자열 → 숫자 배열 변환을 담당하여 모델이 이해할 수 있는 형태로 변환
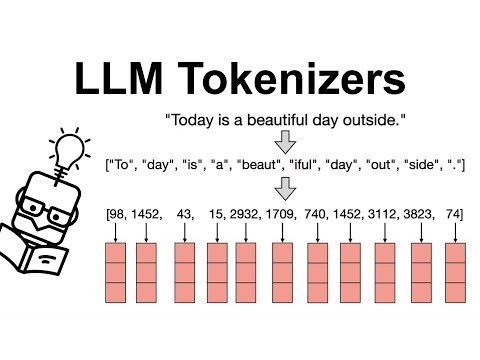
- token_ids
- Tokenizer가 생성한 각 토큰에 대응하는 고유한 정수 번호
- 모델은 텍스트를 직접 이해할 수 없고, 오직 숫자(token_ids)로만 처리 가능
- ex: “안녕하세요” → tokenizer → [1234, 5678, 9012] (token_ids)
- Vocabulary 사전에서 각 토큰의 위치를 나타내는 인덱스 번호
- 하지만 모든 Token이 어휘 집합에 존재하지 않을 수 있음
- 이 경우 Special Token으로 처리:
[UNK](unknown),[PAD](padding),[CLS],[SEP]등 - Fine-tuning 시 중요: padding token의 token_id는 attention에서 무시되도록 설정
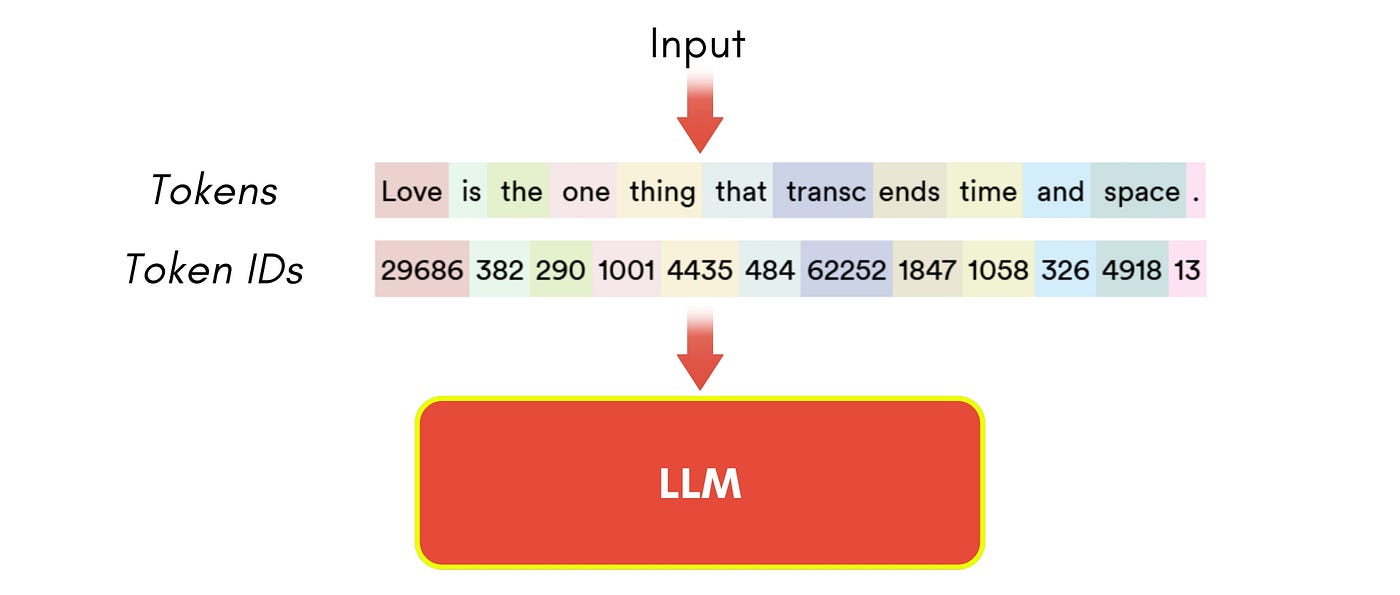
- Attention mask
- Attention mask는 padding token과 실제 token을 구분하기 위한 이진 배열이다.
- 1은 실제 토큰 (계산에 참여), 0은 padding 토큰 (계산에서 제외)을 의미한다.
- 예를 들어
[1, 1, 1, 0, 0]은 앞의 3개 토큰만 유효하고, 뒤의 2개는 padding임을 나타낸다. - 모델 학습시 핵심적인 역할을 하는데, padding 토큰이 실제 학습에 영향을 주지 않도록 차단하는 것이다.
- 특히 모델의 품질에 직접적인 영향을 미치므로, 잘못된 mask 설정 시 성능 저하가 발생할 수 있다.
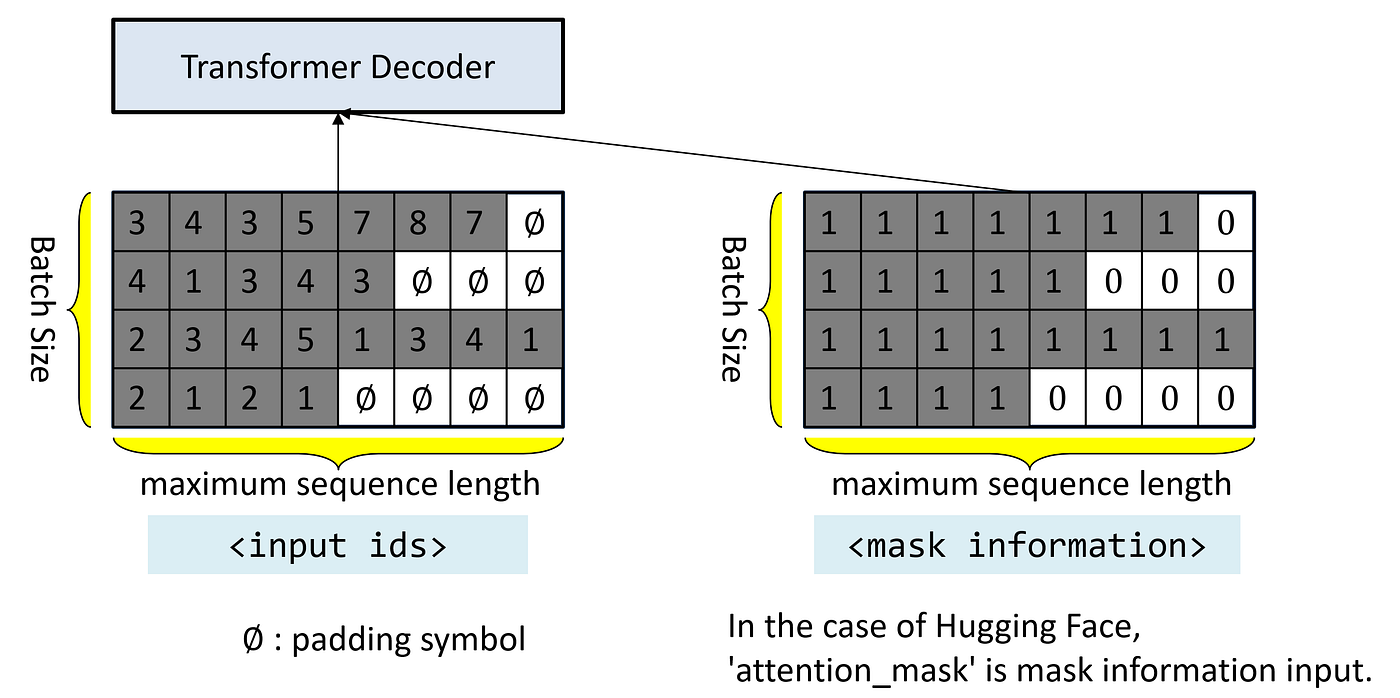
- Padding
- Padding은 서로 다른 길이의 텍스트를 동일한 길이로 맞추는 과정이다.
- 배치 처리를 위해 필수적인 단계로, 모든 시퀀스가 같은 길이여야 한다.
- 짧은 문장의 끝에 특별한 padding token (보통
[PAD])을 추가하여 길이를 맞춘다. - ex:
["안녕", "안녕하세요"]→["안녕", "[PAD]"],["안녕하세요"]로 통일 - Padding 방식에 따라 메모리 사용량과 학습 효율성이 크게 달라진다.
max_length방식은 고정 길이로 안정적이지만 메모리 낭비가 심하다.longest방식은 배치 내 최대 길이로 패딩하여 메모리 효율적이다.- 💡padding token은 attention mask를 통해 학습에서 제외되어야 함
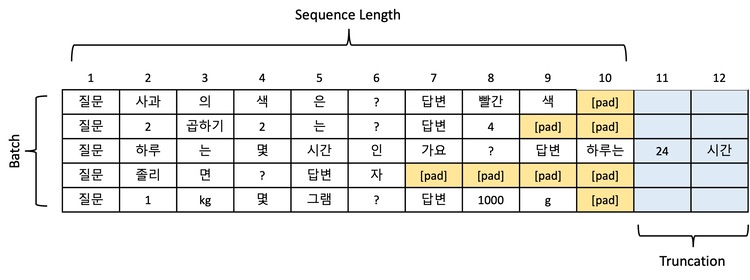
회고
인턴십 1달차를 진행하며 얻은 경험과 인사이트에 대한 내용을 다룬다.
Tech
GPU Memory
업무를 하면서 가장 어려웠던 부분은 GPU 메모리 제약 하에서 최적의 성능을 내는 것이었다.
padding, max_length, batch_size 등 모든 설정이 메모리 사용량에 영향을 미쳤고
하나라도 잘못 설정하면 OOM(Out of Memory) 에러가 발생했다.
메모리 최적화의 복잡성
- Batch size를 늘리면 → 학습 안정성 향상, but 메모리 부족
- Max_length를 줄이면 → 메모리 절약, but 긴 문장 처리 불가
- QLoRA 적용하면 → 메모리 대폭 절약, but 미세한 성능 저하
- Gradient accumulation → 효과적 배치 확대, but 학습 시간 증가
각 설정이 trade-off 관계에 있어서 완벽한 답은 없고 상황에 맞는 최적점을 찾는 과정이 핵심이었다.