[Internship] - 1주차
[Internship] - 1주차 회고

Internship Process
인턴십 연계 과정을 통해 합격하여 스타트업에서의 첫 인턴십 경험과 1주차에 대한 회고
1. 인턴십 연계 과정
Upstage AI Lab 과정 중 인턴십 연계 프로그램에 지원하여 선발 과정을 거쳐 합격한 과정에 대한 기록
선발 과정 개요
- 지원 기간: 2025년 8월 말
- 채용 직무: AI Engineer
- 선발 과정: 1차 서류전형 → 1차 면접 → 2차 면접 → 최종 합격
- 인턴십 기간: 2025.09.01 ~ 2025.10.31 (2달)
2. 선발 과정 상세
예상보다 한 단계 더 추가된 2차 면접과 예비군 훈련과 겹친 특별한 상황에 대한 기록
1. 서류전형
- 부트캠프 과정에서의 프로젝트 포트폴리오 및 학습 성과 기반 평가
- 지원 동기 및 AI 분야에 대한 관심사 작성
2. 면접
- 면접 전에는 기술적인 질문을 별로 하지 않을 것이라고 개인적으로 예상했음
- 하지만 포트폴리오에서 정말 자세한 질문을 많이 받았고, 그래서 초반에는 당황스러웠다.
- 하지만 그래도 내 포트폴리오를 꼼꼼히 봐주신 것 같아서 신기하기도 하고 감사했다.
(보통 면접에서는 포트폴리오를 제대로 안 보시는 경우가 많기에…) - 기술 질문은 포트폴리오 중심의 질문과 통계, ML 지식 등에 대한 질문을 위주로 받았다.
3. 2차 면접 - 특별한 상황
- 예상치 못한 2차 면접 연락을 받았다.
- 하필 예비군 동원훈련과 일정이 겹치는 상황이여서
- 동원훈련 마지막 날 퇴소 직후, 부대 근처 카페에서 Zoom으로 면접을 진행했다. (군복 면접..)
최종 합격
- 개인적으로 지원자가 가장 많을 거 같다고 생각해서 기대는 안 하고 있었지만 운이 좋게도 합격을 했다.
- 포트폴리오 위주 질문에서 그래도 다행히 대답을 잘해서 잘 봐주신게 아닐까 싶다.
회고
인턴십 1주차를 진행하며 얻은 경험과 인사이트에 대한 내용을 다룬다.
Tech
Generative AI 경험
이번 인턴십을 통해 Generative AI 분야에 첫 입문을 하게 됐다.
지금까지 주로 Predictive Modeling, Classification 중심으로 경험했던 배경에서,
Text Generation, Model Fine-tuning, LLM Training 등의 영역은 완전히 새로운 경험이였고
기존에 해당 내용을 얼마나 얕게 알고 있었는지 명확히 체감 할 수 있었다..ㅎ
아래 내용은 이번 1주차에서 배정 받은 업무를 수행하며 새롭게 알게 된 사실과 기존에 알고 있었던
내용을 다시 깊이 있게 복습할 수 있게 정리해봤다.
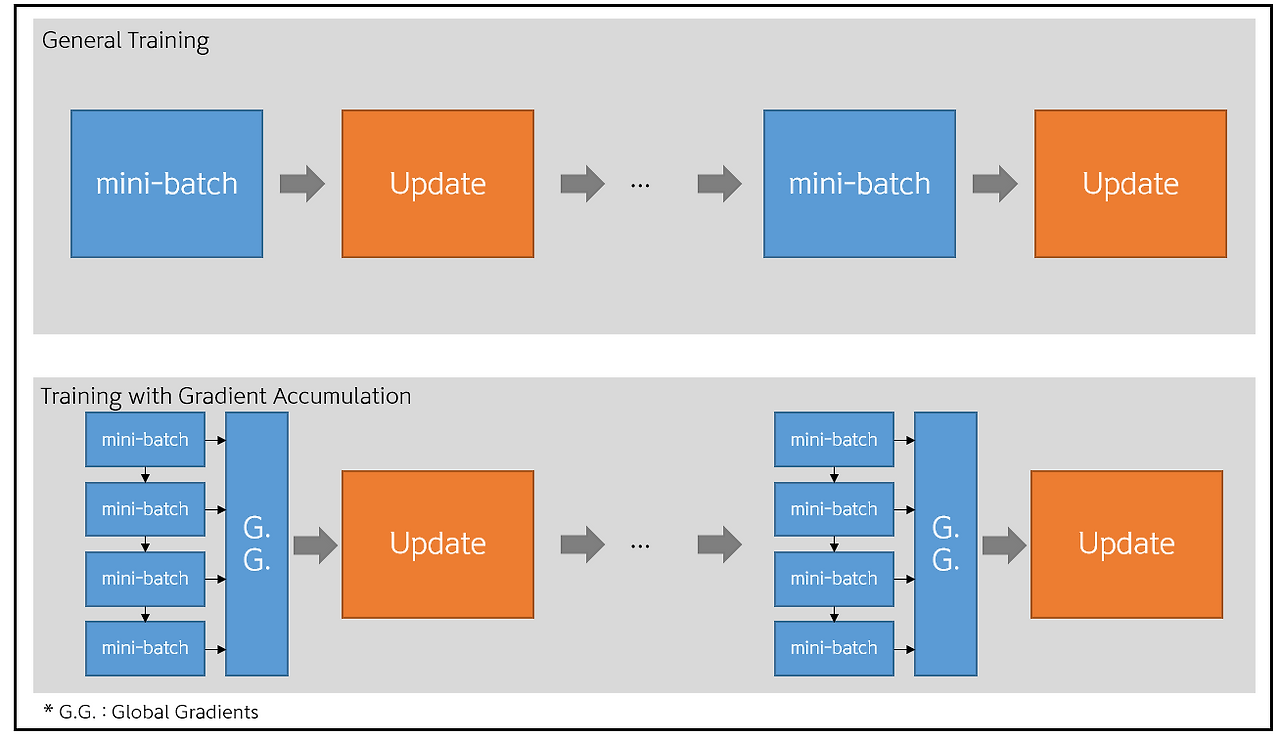
Gradient Accumulation Step
 Architecture
Architecture
왜 필요한가?
- 실무에선 GPU 자원이 풍족하지가 않다. 그렇기에 비용과 시간을 고려해서 개발을 해야하는게 가장 큰 문제다.
- Gradient Accumulation은 GPU 메모리 제약 상황에서 effective batch size를 확장하는 핵심 기법이다.
- 대용량 모델 학습 시 GPU 메모리 부족으로 인한 OOM(Out of Memory) 에러 해결
- Large Batch Size의 이점을 얻으면서도 메모리 효율성 확보
- 분산 학습 환경에서 gradient synchronization 최적화
effective batch size 란?
Gradient Accumulation Step을 알기전에 먼저 effective batch size를 알아야한다.
비전공자, 막 입문한 분들이라면 보통 batch size까지만 알고 있었을 것이다.
(아니라면 잘 공부하신 거 같습니다. 전 이번에 알게 됐거든요..)
하지만 실제 학습에 영향을 주는 진짜 배치 크기는 따로 있는데, 이것이 바로 effective batch size다.
- 일반적인 batch size: 한 번에 GPU 메모리에 올라가는 샘플 수
- effective batch size: 실제로 gradient 업데이트에 사용되는 전체 샘플 수
핵심: 메모리는 물리적 batch size만큼 사용하지만, 학습 효과는 effective batch size로 결정됨
1 2 3 4 5
# ex batch_size=8, gradient_accumulation_step=4 effective_batch_size = batch_size * gradient_accumulation_step # effective_batch_size=32
언제 사용되는가?
- Fine-tuning 과정에서 큰 배치 사이즈가 필요한 경우
- GPU 메모리 제약으로 인해 원하는 배치 사이즈를 사용할 수 없는 상황
- Gradient 안정성을 위해 더 큰 effective batch size가 필요한 경우
쉽게 말해, 우리는 모델을 훈련할 때 한 번에 처리하는 batch_size를 크게 하고 싶지만
GPU Memory가 작아서 그렇게 할 수 없는 경우가 있다. 이럴 때 Gradient Accumulation Step을 사용하면
작은 batch_size로 여러 번 나누어 Gradient를 계산한 다음, 이걸 누적해서 한 번에 Weights를 업데이트한다.
그 결과, 실제 메모리를 적게 쓰면서도 마치 훨씬 큰 effective_batch_size를 처리한 것과 동일한 효과를 얻게 된다. 이를 통해 large-scale model training에서 메모리 효율성과 학습 안정성을 동시에 확보할 수 있으며
특히 제한된 GPU 리소스 환경에서도 고품질 모델 학습이 가능하다.
Culture
아직 1주차라 회사 코드베이스 이해하고 개발 환경 세팅하느라 정신없이 흘러갔다.
스타트업이다 보니 빠른 속도로 업무가 진행되고, 실무 코드를 직접 보면서 이해하고 배워야한다.
이번 인턴쉽을 통해 부족한 이론 지식과 개발 실력을 향상시킬 수 있을 거 같다.(매우 힘들 예정)