[Upstage AI Lab] 22주차 - Langchain
[Upstage AI Lab] 22주차 - Langchain 학습 내용
들어가며
이번 포스팅에서는 RAG 시스템과 LangChain 프레임워크에 대해 정리했다.
생성형 LLM의 한계를 극복하고 더 정확하고 신뢰할 수 있는 AI 시스템을 구축하는 방법을 다룬다.
RAG 소개
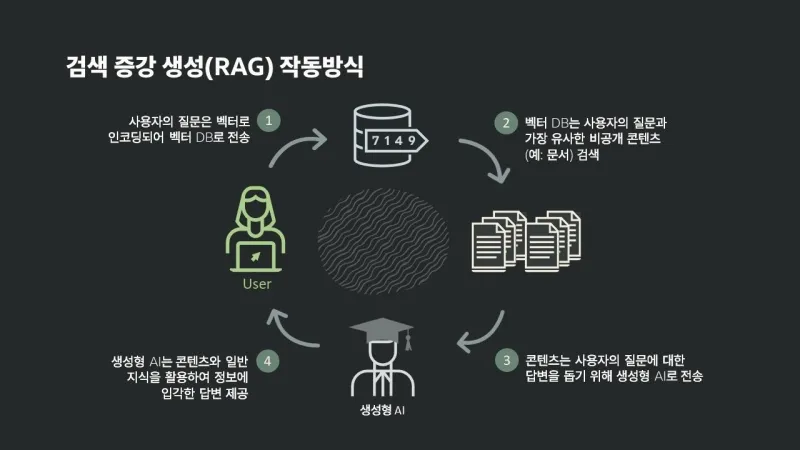
1. RAG란?
RAG는 검색(Retrieval)과 생성(Generation)을 결합한 아키텍처로,
외부 지식 베이스에서 관련 정보를 검색하여 LLM의 응답 품질을 향상시키는 기술이다.
생성형 LLM의 한계
- Hallucination: 사실과 다른 정보를 그럴듯하게 생성
- Knowledge Cutoff: 훈련 시점 이후의 정보는 알지 못함
- Domain-specific Knowledge: 특정 도메인의 전문 지식 부족
- 정보 업데이트: 새로운 정보 반영을 위해서는 재훈련 필요
RAG의 장점
- 실시간 정보 활용: 최신 정보를 바탕으로 응답 생성
- 도메인 특화: 특정 분야의 전문 지식 활용 가능
- Hallucination 감소: 검색된 실제 문서를 바탕으로 답변
- 비용 효율성: 전체 모델 재훈련 없이 지식 업데이트
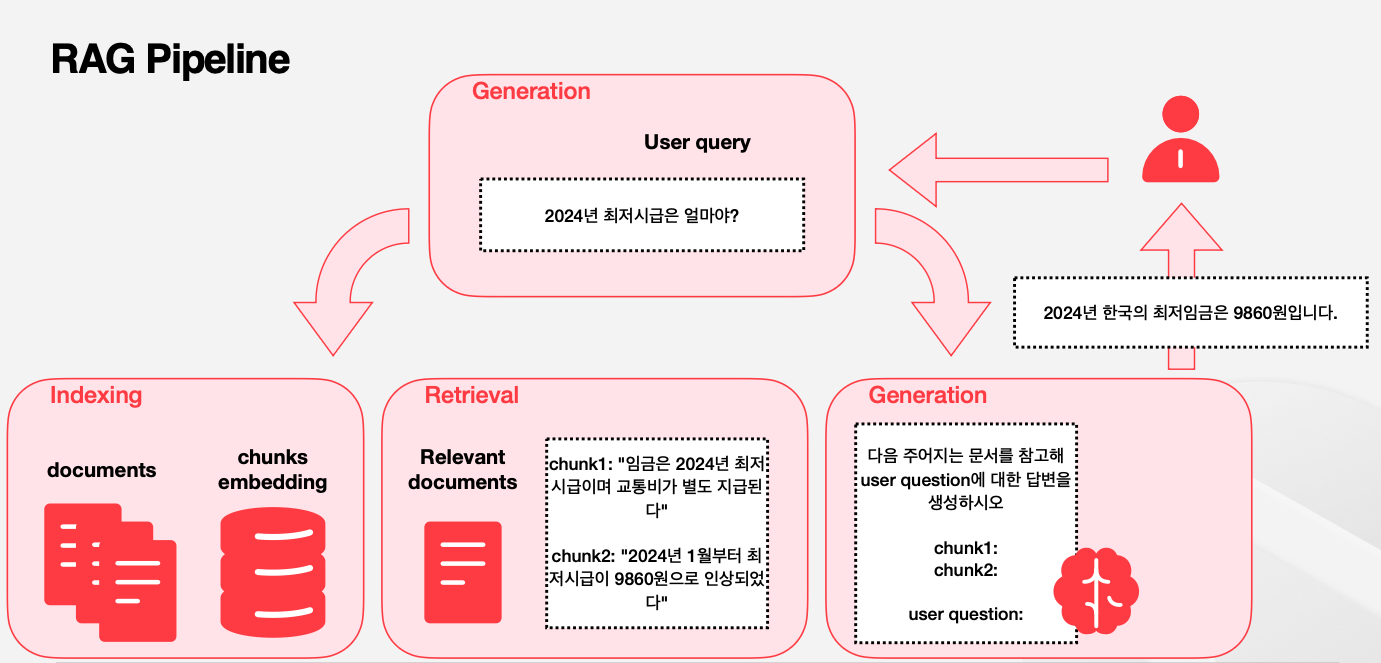
2. RAG Pipeline 구조
RAG 시스템은 크게 인덱싱(Indexing), 검색(Retrieval), 생성(Generation) 세 단계로 구성된다.
각 단계가 유기적으로 연결되어 전체 시스템의 성능을 결정한다.
1. 인덱싱 (Indexing)
Documents → Chunks → Embeddings → Vector Store
- 문서 분할: 큰 문서를 작은 청크(chunk)로 분할
- 임베딩 생성: 각 청크를 벡터로 변환
- 벡터 저장소: 임베딩을 검색 가능한 형태로 저장
2. 검색 (Retrieval)
User Query → Embedding → Similarity Search → Relevant Chunks
- 쿼리 임베딩: 사용자 질문을 벡터로 변환
- 유사도 검색: 벡터 공간에서 가장 유사한 청크들 검색
- 관련 문서 반환: 상위 k개의 관련 문서 선택
3. 생성 (Generation)
User Query + Retrieved Context → LLM → Final Answer
- 컨텍스트 결합: 검색된 문서와 사용자 질문을 결합
- 프롬프트 구성: LLM에 입력할 프롬프트 생성
- 답변 생성: LLM을 통한 최종 답변 생성
RAG Pipeline 동작 예시
- 문서: “2024년 한국의 경제성장률은 2.1%였다”
- 청크 분할 및 임베딩 저장
- 사용자 질문: “2024년 한국 경제성장률은?”
- 유사도 검색으로 관련 청크 찾기
- LLM이 검색된 정보를 바탕으로 답변 생성
- 최종 답변: “2024년 한국의 경제성장률은 2.1%입니다.”
3. RAG vs Fine-tuning
RAG와 Fine-tuning은 서로 다른 접근 방식으로 LLM을 개선하는 방법이다.
각각의 장단점을 이해하고 상황에 맞는 방법을 선택하는 것이 중요하다.
RAG (Retrieval-Augmented Generation)
장점:
- 실시간 정보 업데이트 가능
- 투명성: 답변의 근거가 되는 문서 제시 가능
- 비용 효율성: 모델 재훈련 불필요
- 도메인 확장성: 새로운 문서 추가만으로 지식 확장
단점:
- 검색 품질에 의존: 관련 문서를 찾지 못하면 성능 저하
- 응답 속도: 검색 과정으로 인한 지연
- 복잡성: 여러 구성 요소의 통합 관리 필요
Fine-tuning
장점:
- 특화된 성능: 특정 태스크에 최적화
- 빠른 응답: 검색 과정 없이 직접 생성
- 일관된 스타일: 특정 톤이나 스타일 유지
단점:
- 정적 지식: 훈련 시점의 정보로 제한
- 높은 비용: 재훈련을 위한 컴퓨팅 자원 필요
- Catastrophic Forgetting: 새로운 지식 학습 시 기존 지식 손실 위험
LangChain 개요
1. LangChain이란?
LangChain은 LLM 애플리케이션 개발을 위한 프레임워크로,
RAG, 에이전트, 체인 등 복잡한 LLM 워크플로우를 쉽게 구축할 수 있게 해준다.
LangChain의 핵심 구성 요소
1. LLMs: 다양한 언어 모델 통합 인터페이스 2. Prompts: 프롬프트 템플릿 및 관리 3. Chains: 여러 구성 요소를 연결하는 워크플로우 4. Agents: 동적으로 도구를 선택하고 사용하는 시스템 5. Memory: 대화 기록 및 상태 관리 6. Retrievers: 문서 검색 및 벡터 스토어 연동
LangChain의 장점
- 모듈화: 각 구성 요소를 독립적으로 개발 및 테스트
- 확장성: 새로운 LLM이나 도구 쉽게 추가
- 표준화: 일관된 인터페이스로 다양한 모델 사용
- 생산성: 복잡한 LLM 애플리케이션을 빠르게 프로토타이핑
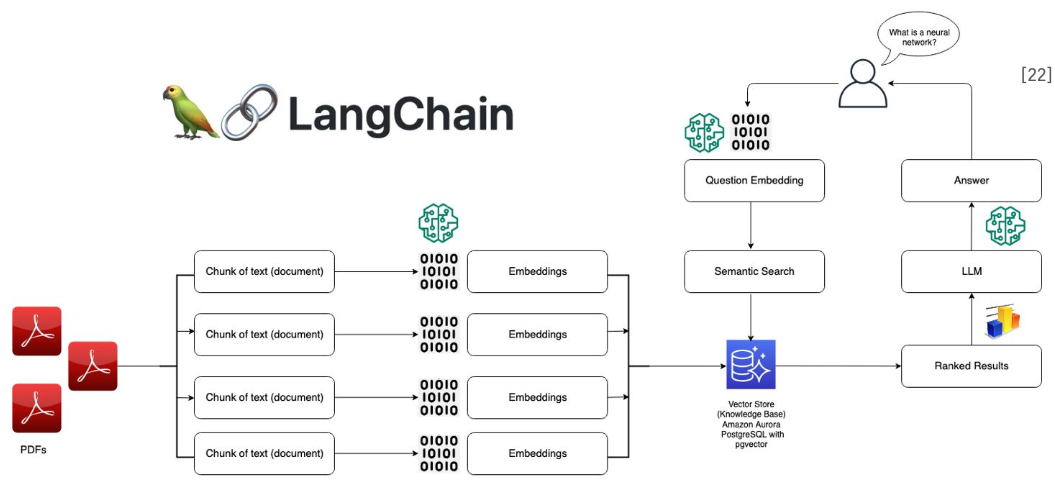
2. LangChain RAG 구현
LangChain을 사용하면 RAG 시스템을 간단하게 구현할 수 있다.
문서 로딩부터 벡터 저장, 검색, 생성까지 전체 파이프라인을 제공한다.
기본 RAG 구현 예제
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# 1. 문서 로딩
loader = TextLoader("document.txt")
documents = loader.load()
# 2. 문서 분할
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 3. 임베딩 및 벡터 스토어 생성
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(texts, embeddings)
# 4. 검색기 설정
retriever = vectorstore.as_retriever()
# 5. RAG 체인 생성
llm = OpenAI()
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# 6. 질문 답변
question = "문서의 주요 내용은 무엇인가요?"
result = qa_chain.run(question)
print(result)
고급 RAG 기법들
1. Multi-Query Retrieval
- 하나의 질문을 여러 관점에서 reformulate
- 다양한 검색 결과를 종합하여 더 포괄적인 답변
2. Parent Document Retriever
- 작은 청크로 검색하지만 큰 컨텍스트 반환
- 검색 정확도와 컨텍스트 풍부함의 균형
3. Self-Query Retriever
- 메타데이터 필터링과 시맨틱 검색 결합
- 구조화된 쿼리로 더 정확한 검색
3. LlamaIndex vs LangChain
LlamaIndex와 LangChain은 모두 LLM 애플리케이션 개발을 지원하지만
서로 다른 강점과 특화 분야를 가지고 있다.
LlamaIndex 특징
- Data-centric: 데이터 인덱싱과 검색에 특화
- RAG 최적화: RAG 시스템 구축에 최적화된 도구들
- 복잡한 쿼리 처리: 다단계 추론과 복잡한 질문 처리
- 성능 최적화: 대규모 문서 컬렉션 처리에 효율적
LangChain 특징
- 워크플로우 중심: 복잡한 LLM 워크플로우 구축
- 에이전트 시스템: 도구 사용과 계획 수립 기능
- 다양한 통합: 수많은 LLM과 도구들과의 연동
- 생태계: 활발한 커뮤니티와 풍부한 예제
사용 사례별 선택 가이드
- 문서 검색/QA 중심: LlamaIndex 추천
- 복잡한 워크플로우: LangChain 추천
- 에이전트 시스템: LangChain 추천
- 대규모 문서 처리: LlamaIndex 추천
페르소나 챗봇
1. 페르소나 기반 챗봇
페르소나(Persona)를 가진 챗봇은 일관된 성격과 말투를 유지하며
사용자와의 상호작용에서 더 자연스럽고 매력적인 경험을 제공한다.
페르소나의 중요성
- Speaker Consistency: 일관된 화자 특성 유지
- User Engagement: 사용자와의 감정적 연결 강화
- Brand Identity: 브랜드나 서비스의 고유한 개성 반영
- Trust Building: 예측 가능한 상호작용으로 신뢰 구축
페르소나 설계 요소
- 성격 특성: 친근함, 전문성, 유머 등
- 말투와 어조: 존댓말/반말, 격식/비격식
- 전문 분야: 특화된 지식 영역
- 반응 패턴: 특정 상황에서의 일관된 반응
2. 페르소나 구현 방법
LangChain을 활용하여 페르소나가 적용된 챗봇을 구현할 수 있다.
시스템 프롬프트와 메모리 관리를 통해 일관성을 유지한다.
페르소나 프롬프트 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
persona_prompt = """
당신은 친근하고 도움이 되는 AI 어시스턴트입니다.
다음과 같은 특성을 가지고 있습니다:
성격:
- 항상 긍정적이고 격려하는 말투를 사용합니다
- 복잡한 내용도 쉽게 설명하려고 노력합니다
- 사용자의 감정에 공감하며 적절히 반응합니다
말투:
- 존댓말을 사용하되 너무 딱딱하지 않게 합니다
- 적절한 이모티콘을 사용하여 친근감을 표현합니다
- 질문에 대해서는 명확하고 구체적으로 답변합니다
전문 분야:
- 기술 관련 질문에 특히 능숙합니다
- 학습 방법과 문제 해결에 대한 조언을 잘 합니다
사용자와의 대화에서 이러한 특성을 일관되게 유지해주세요.
"""
메모리 기반 페르소나 유지
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
# 메모리 설정
memory = ConversationBufferMemory()
# 페르소나가 적용된 대화 체인
conversation = ConversationChain(
llm=llm,
memory=memory,
prompt=persona_prompt,
verbose=True
)
# 대화 진행
response1 = conversation.predict(input="안녕하세요!")
response2 = conversation.predict(input="파이썬을 어떻게 공부하면 좋을까요?")
Advanced Persona Techniques
1. Context-Aware Persona
- 대화 맥락에 따라 페르소나 조정
- 사용자의 감정 상태에 따른 적응적 반응
2. Multi-Modal Persona
- 텍스트뿐만 아니라 이미지, 음성 등 다양한 모달리티
- 일관된 페르소나를 여러 채널에서 유지
3. Persona Evolution
- 시간과 상호작용에 따른 페르소나 발전
- 사용자와의 관계 깊이에 따른 변화
실무 활용
1. RAG 시스템 최적화
RAG 시스템의 성능은 각 구성 요소의 최적화에 달려있다.
청킹 전략, 임베딩 모델, 검색 알고리즘 등을 세심하게 조정해야 한다.
청킹(Chunking) 전략
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 고정 크기 청킹
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
# 의미 단위 청킹
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n", ".", "!", "?", ",", " ", ""]
)
# 문서 구조 기반 청킹
from langchain.text_splitter import MarkdownHeaderTextSplitter
splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=[
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
)
임베딩 모델 선택
- OpenAI Embeddings: 높은 품질, API 비용 발생
- Sentence Transformers: 로컬 실행, 다양한 모델 선택
- Cohere Embeddings: 멀티링구얼 지원
- Custom Embeddings: 도메인 특화 모델
검색 성능 개선
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 하이브리드 검색 (벡터 + 키워드)
from langchain.retrievers import EnsembleRetriever
from langchain.retrievers import BM25Retriever
# BM25 키워드 검색
bm25_retriever = BM25Retriever.from_documents(documents)
# 벡터 검색
vector_retriever = vectorstore.as_retriever()
# 앙상블 검색
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5]
)
2. 프로덕션 배포 고려사항
RAG 시스템을 프로덕션 환경에 배포할 때는
성능, 확장성, 비용, 보안 등 다양한 요소를 고려해야 한다.
성능 최적화
- 벡터 DB 선택: Pinecone, Weaviate, Qdrant 등
- 캐싱 전략: 자주 검색되는 결과 캐싱
- 병렬 처리: 배치 임베딩 및 검색
- 모니터링: 응답 시간 및 품질 모니터링
확장성 고려사항
- 수평적 확장: 여러 벡터 DB 인스턴스
- 로드 밸런싱: 트래픽 분산
- 자동 스케일링: 부하에 따른 자동 조정
보안 및 개인정보
- 데이터 암호화: 저장 및 전송 중 암호화
- 접근 제어: 사용자별 권한 관리
- 감사 로그: 모든 요청과 응답 기록
- 개인정보 마스킹: 민감한 정보 처리
비용 최적화
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 비용 효율적인 RAG 구현 예시
from langchain.llms import HuggingFacePipeline
from langchain.embeddings import HuggingFaceEmbeddings
# 로컬 임베딩 모델 사용
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
# 오픈소스 LLM 사용
llm = HuggingFacePipeline.from_model_id(
model_id="microsoft/DialoGPT-medium",
task="text-generation",
model_kwargs={"temperature": 0.1}
)