[Upstage AI Lab] 21주차 - LLM
[Upstage AI Lab] 21주차 - LLM 기반 NLP 연구 동향

들어가며
이번 글은 Upstage AI Lab 과정 중 위키라이더 담당자로 선정되어 강의 내용을 요약한 내용이다.
LLM 기반 NLP 연구 동향을 Data-Centric, Model-Centric 관점에서 살펴보고
Prompt Engineering과 LLM Application 개발에 대해 정리했다.
Data-Centric NLP 연구
1. LLM 학습 데이터 종류
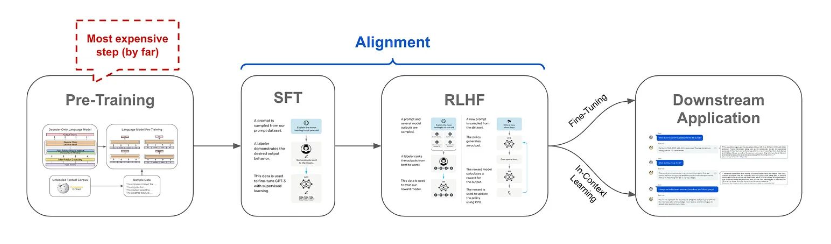
LLM 학습에는 크게 사전 학습(Pre-training) 데이터와 미세 조정(Fine-tuning) 데이터가 활용된다.
각각의 목적과 특성이 다르며, 데이터의 품질과 다양성이 모델 성능에 결정적인 영향을 미친다.
사전 학습(Pre-training) 데이터
- 웹 데이터 (Wikipedia, News, Reviews 등)를 활용하여 구축
- 데이터의 품질 및 다양성이 모델 성능에 큰 영향을 줌
- 필터링/중복 제거 등의 전처리 작업 필수
- 영어의 경우 Common Crawl, WebText2, BookCorpus, Wikipedia 등을 주로 활용
주요 사전 학습 데이터 구성 사례
- GPT-3: Common Crawl (filtered), WebText2, Books1, Books2, Wikipedia (총 300B 토큰)
- LLaMA: Common Crawl, C4, Github, Wikipedia, Books, ArXiv, StackExchange (총 1.4T 토큰)
태스크 특화 사전 학습
특정 작업에 특화된 모델 구축을 위해 도메인별 데이터를 높은 비율로 활용:
- LaMDA: 대화 데이터 50%로 대화 특화 모델 구축
- BLOOM, PaLM: 다국어 텍스트로 다국어 특화 모델 구축
- Galactica: 과학 데이터 86%로 과학 도메인 특화 모델 구축
- AlphaCode: 코드 데이터 100%로 코딩 특화 모델 구축
미세 조정(Fine-tuning) 데이터
- 사전 학습된 모델을 특정 작업에 특화하기 위한 데이터
- 입력에 대응하는 정답(출력 또는 선호 결과)이 존재
- Instruction Tuning: 지시어와 대응 출력으로 구성된 데이터
- Alignment Tuning: 인간의 선호도가 반영된 데이터
2. LLM 데이터 전처리
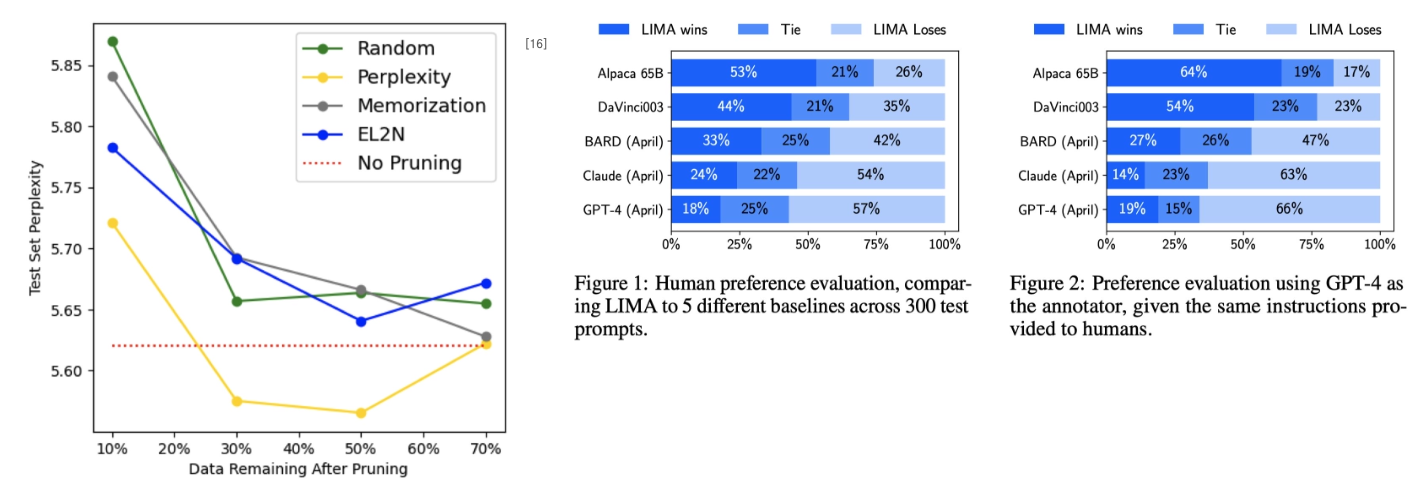
데이터의 양보다 품질과 다양성이 더 중요하다는 것이 여러 연구를 통해 입증되었다.
적절한 데이터 전처리를 통해 더 적은 데이터로도 높은 성능을 달성할 수 있다.
주요 전처리 기법
1. Data Filtering
- 고품질 문서 분류기 학습 및 활용
- 언어 식별 및 비목적 언어 제거
- 휴리스틱 기반 품질 필터링 (구두점, 단어/문장 수 등)
2. Deduplication
- Document-level 중복 제거
- Fuzzy deduplication 및 Hashing 방법론 활용
- 전체 데이터 크기를 10% 감소시키며 과적합 방지
3. Diversification
- 다양한 소스의 고품질 코퍼스 혼합
- 데이터 다양성이 모델 성능에 가장 큰 영향
주요 연구 사례
- The Pile: 22개 고품질 코퍼스로 구성된 800GB 데이터셋
- RefinedWeb: 웹 데이터만으로 강력한 모델 구축 가능성 입증
- LIMA: 단 1,000개 고품질 instruction dataset으로 뛰어난 성능 달성
3. LLM 기반 라벨링 연구
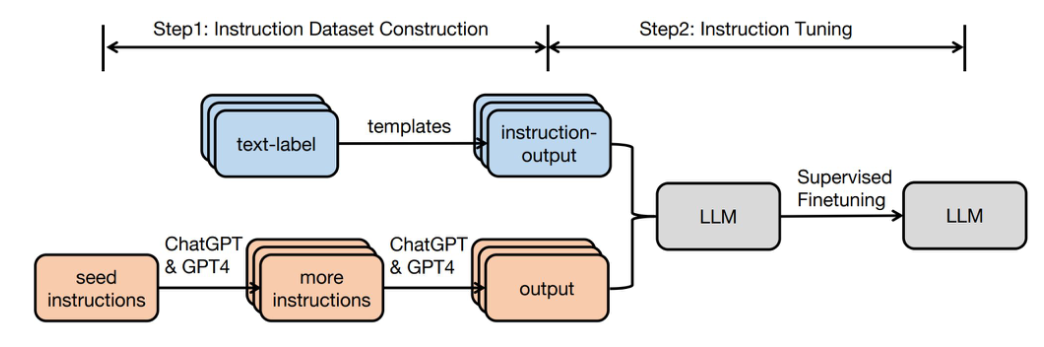
LLM의 높은 언어 능력을 활용하여 데이터를 증강하거나 새로운 데이터를 합성하는 연구가 활발히 진행
이는 데이터 구축 비용을 대폭 절감하면서도 높은 품질의 데이터를 생성할 수 있는 방법론이다.
데이터 증강(Data Augmentation) 연구
- Cross-lingual Dataset 증강으로 다국어 성능 향상
- Structured prediction tasks를 위한 Mixture of Soft Prompts 방법론
- Human-in-the-loop 방식으로 데이터 다양성과 품질 개선
데이터 합성(Data Synthesis) 연구
- Vicuna: 70K ChatGPT 대화 데이터로 LLaMA 미세조정
- Self-Instruct: LLM을 활용한 고품질 Instruction 데이터셋 자동 구축
- GPT-4 기반 Instruction Tuning: Zero-shot 성능 대폭 개선
Model-Centric NLP 연구
1. LLM Tuning
LLM의 방대한 파라미터 수로 인해 효율적인 튜닝 방법론이 필수적이다.
Parameter Efficient Tuning 기법들을 통해 적은 자원으로도 효과적인 모델 튜닝이 가능하다.
Fine-Tuning vs Parameter Efficient Tuning
- Fine-Tuning: 모델 전체 파라미터를 업데이트하는 전통적 방법
- Parameter Efficient Tuning: 일부 파라미터만 튜닝하여 효율성 증대
주요 Parameter Efficient Tuning 기법
1. LoRA (Low-Rank Adaptation)
- Gradient values (ΔW)를 low-rank 행렬 A, B로 매핑
- 메모리 사용량 대폭 감소 (GPT-3 175B: 1.2TB → 350GB)
- 체크포인트 크기 감소 (350GB → 35MB, r=4)
- 빠른 태스크 전환 가능
2. QLoRA (Quantized LoRA)
- 4-bit NormalFloat (NF4) 양자화
- Double Quantization 기법
- Paged Optimizer 활용
3. Prefix-Tuning
- Transformer layer 입력 앞에 trainable parameters 추가
- 0.1% 파라미터만으로 full fine-tuning 수준 성능 달성
4. LLaMA-Adapter
- Zero-initialized gating 방법론
- 1.2M Adapter 파라미터만 학습
- Multi-modal instruction 지원
2. Domain Specialization
General Domain 데이터로 학습된 LLM은 특정 도메인에 대한 이해력이 부족할 수 있다.
Domain Specialization을 통해 특정 분야에 특화된 고성능 모델 구축이 가능하다.
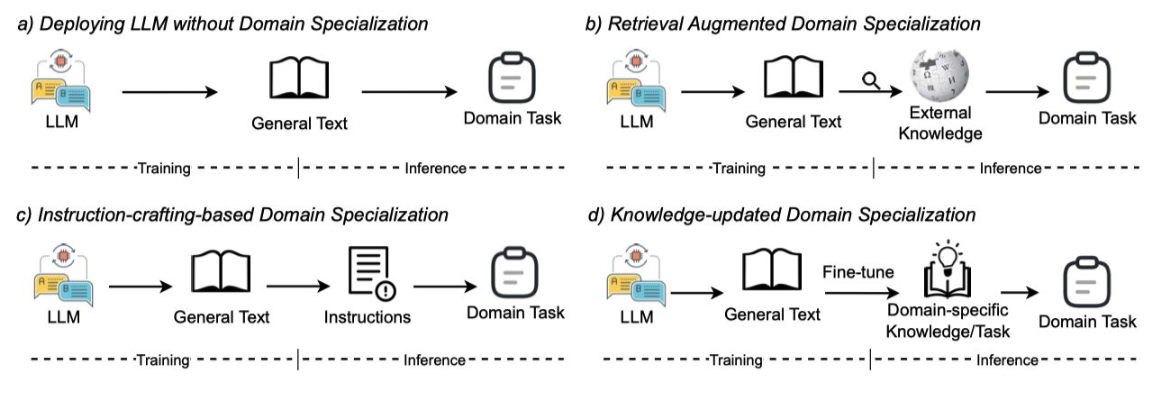
Knowledge Augmentation (RAG)
- Retrieval-Augmented Generation을 통한 외부 지식 활용
- 모델 파라미터 업데이트 없이 도메인 지식 향상
- In-Context Learning을 통한 지식 주입
주요 연구 사례:
- GeneGPT: NCBI Web APIs와 LLM 결합
- Verify-and-Edit: Chain-of-Thought에 지식 기반 검증 과정 추가
Domain Tuning
1. 금융 도메인 - FinGPT
- 실시간 금융 데이터 자동 수집 파이프라인
- QLoRA 및 주가 기반 강화학습 활용
2. 의료 도메인 - Med-PaLM 2
- USMLE 합격 점수 달성한 최초 모델
- Instruction fine-tuning, Few-shot prompting, Chain-of-Thought 등 다양한 기법 활용
LLM Application 연구
1. LLMOps
LLM의 대규모 파라미터와 복잡한 배포 과정으로 인해 LLMOps가 새로운 패러다임으로 등장했다.
기존 MLOps와 유사하지만 모델 규모에 따른 특수성을 고려해야 한다.
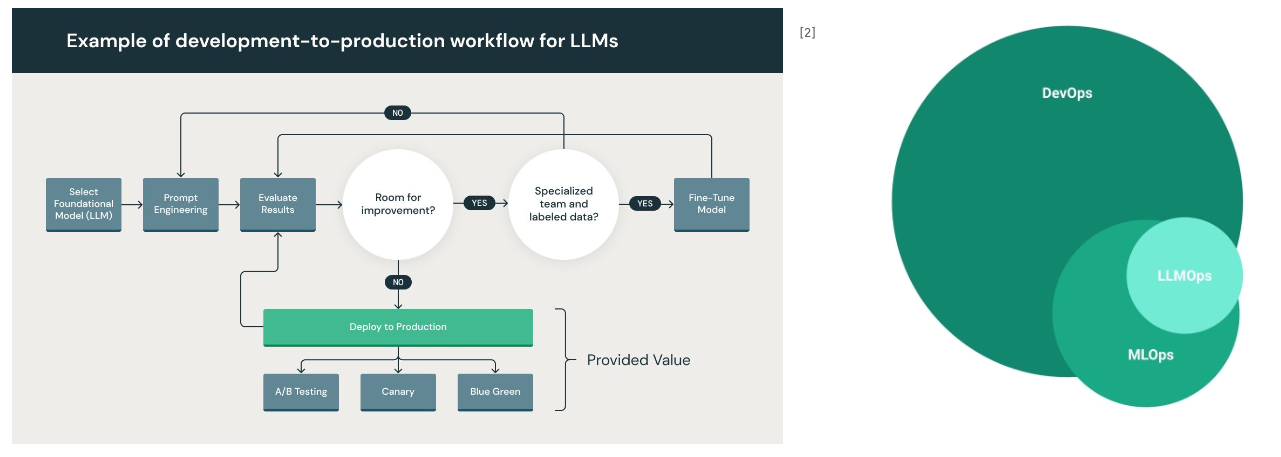
LLMOps의 특수성
1. 모델 사이즈
- 대규모 파라미터로 인한 높은 컴퓨팅 자원 요구
- 최적화 및 병렬 처리 시스템 필수
2. 데이터 특수성
- 방대한 데이터 크기 및 Prompt Engineering 요구
- In-Context Learning 극대화를 위한 데이터 구조화
3. Generative Models
- 출력 결과의 다양성으로 인한 복잡한 평가
- 윤리적 문제, 편향성, 환각 현상 고려
4. API 형태 배포
- 대화형 챗봇, 어시스턴트 등 다양한 형태
- 실시간 상호작용 및 확장성 고려
2. Augmented LLMs
LLM 단독으로는 해결하기 어려운 문제들을 외부 도구와의 결합을 통해 해결하는
Tool-using LLM 연구가 활발히 진행되고 있다.
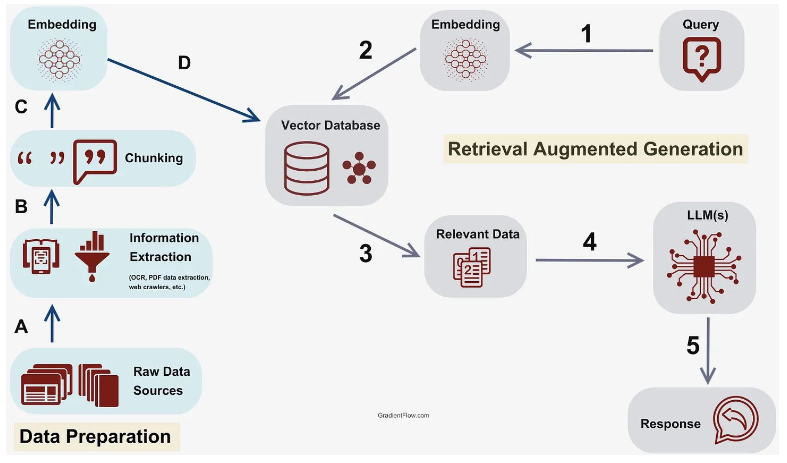
주요 도구 활용 연구
1. Toolformer
- LLM이 스스로 도구 사용법 학습
- 다양한 API와의 자동 연동
2. TaskMatrix.AI
- 수백만 개의 API와 Foundation Model 연결
- 복잡한 태스크의 자동 분해 및 실행
3. CRITIC
- Tool-Interactive Critiquing을 통한 자기 수정
- 외부 도구 피드백 기반 성능 개선
자기 개선 연구
1. Self-Debug
- 코드 생성 시 자동 디버깅 능력
- 실행 결과 기반 자기 수정
2. Reflexion
- 언어적 강화학습을 통한 에이전트 개선
- 실패 경험 학습 및 전략 개선
3. BlenderBot 3
- 지속적 학습을 통한 책임감 있는 대화 에이전트
- 실시간 피드백 반영
Prompt Engineering 연구
1. Prompt Engineering 개요
LLM의 In-Context Learning 능력을 최대화하기 위한 Prompt Engineering이 핵심 기술로 부상했다.
적절한 프롬프트 설계를 통해 모델 재학습 없이도 다양한 태스크에서 높은 성능을 달성할 수 있다.

Prompt 구성 요소
- Task Instruction: 수행할 작업에 대한 명확한 설명
- Demonstrations (Examples): 문제 해결 방법을 보여주는 예시
- Query: 실제 해결하고자 하는 문제
2. 주요 Prompting 기법
LLM의 성능을 극대화하기 위해 다양한 프롬프트 기법들이 개발되었으며
각 기법은 특정 문제 해결에 효과적인 접근 방식을 제공한다.
Chain-of-Thought (CoT) Prompting
- 단계적 사고 과정을 유도하여 복잡한 추론 문제 해결
- 수학적 추론, 상식 추론 등에서 큰 성능 향상
- Human-crafted examples를 통한 학습
Least-to-Most Prompting
- 복잡한 문제를 하위 문제로 분해하여 순차적 해결
- Compositional generalization 태스크에서 CoT 대비 큰 개선
Auto-CoT (Automatic Chain of Thought)
- Manual CoT의 인간 노력 문제 해결
- Diversity 기반 자동 예시 선택으로 성능 향상
Plan-and-Solve Prompting
- 계획 수립 후 실행 방식으로 오류 감소
- Zero-shot에서도 Few-shot Manual-CoT 수준 성능
Self-Consistency
- 다양한 추론 경로 생성 후 다수결 투표
- 복잡한 추론 태스크에서 특히 효과적
3. Advanced Prompting 기법
기존 프롬프트 기법을 넘어선 고급 프롬프트 기법들은 LLM의 추론 능력과 활용 범위를 더욱 확장시킨다.
Self-Instruct
- LLM을 활용한 고품질 Instruction 자동 생성
- 인간 노력 없이도 다양한 학습 데이터 구축 가능
Verify-and-Edit Framework
- 외부 지식 기반 검증 과정 추가
- Knowledge-intensive tasks 성능 대폭 개선
Promptbreeder
- Prompt Evolution 기법
- Self-referential Self-improvement 전략
4. LLM Tools
LLM 개발 및 활용을 용이하게 하는 다양한 프레임워크와 라이브러리가 등장하여
복잡한 LLM 애플리케이션 구축을 지원하고 있다.
LangChain
- LLM 개발/활용을 위한 통합 프레임워크
- Model I/O, Retrieval, Agents 등 모듈화된 구성 요소
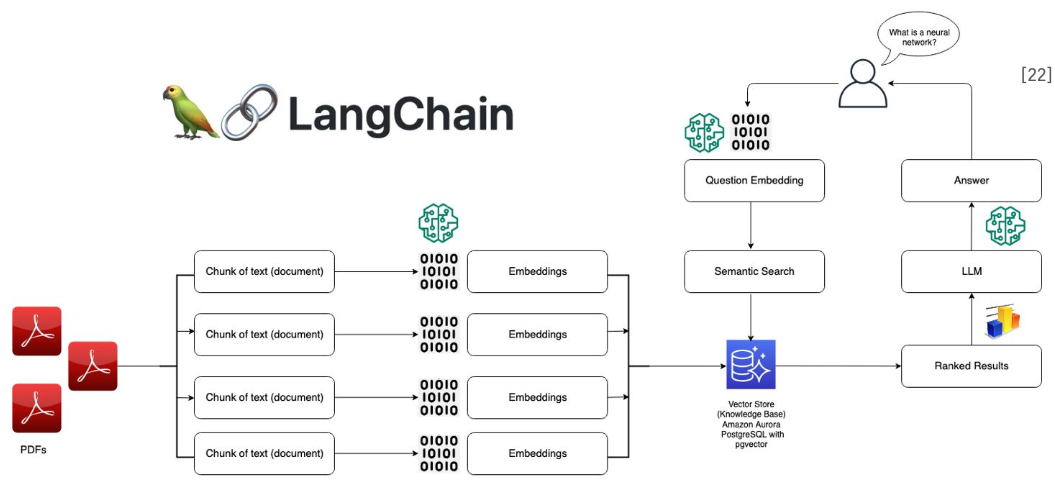 LangChain
LangChain
AutoGPT
- GPT 간 자율적 상호작용을 통한 목표 달성
- 사용자 설정 목표의 자동 분해 및 실행
 AutoGPT
AutoGPT
Scikit-LLM
- Scikit-learn 방식의 LLM 활용 인터페이스
- 전통적인 머신러닝 워크플로우에 LLM 통합
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Import the necessary modules
from skllm.datasets import get_classification_dataset
from skllm.config import SKLLMConfig
from skllm.models.gpt.classification.zero_shot import ZeroShotGPTClassifier
# Configure the credentials
SKLLMConfig.set_openai_key("<YOUR_KEY>")
SKLLMConfig.set_openai_org("<YOUR_ORGANIZATION_ID>")
# Load a demo dataset
X, y = get_classification_dataset() # labels: positive, negative, neutral
# Initialize the model and make the predictions
clf = ZeroShotGPTClassifier(model="gpt-4")
clf.fit(X, y)
clf.predict(X)