[Upstage AI Lab] 20주차 - NLP 경진대회
[Upstage AI Lab] 20주차 - NLP 경진대회 회고
NLP Dialogue Summarization
Upstage AI Lab 의 NLP 경진대회에 대한 주요 내용과 회고록 내용
1. 개요
NLP Dialogue Summarization 경진대회는 주어진 데이터를 활용하여 일상 대화에 대한 요약을
효과적으로 생성하는 모델을 개발하는 대회다.
Project Overview
- Project Duration: 2025.07.25 ~ 2025.08.06
- Team: 7명
- Submission: 499개 문서의 요약문을 생성한 CSV 파일 제출
- Evaluation Metric: ROUGE Score
- ROUGE: 생성된 요약문이 참조 요약문과 얼마나 유사한지를 측정하는 지표
- 주로 Text 요약 Task 에서 사용, ROUGE-1, ROUGE-2, ROUGE-L 등 다양한 변형이 있다.
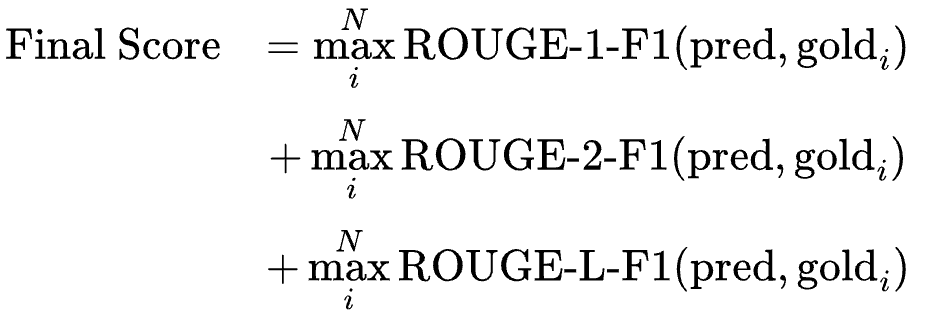 최종 평가지표
최종 평가지표
2. 주요 역할
본 대회는 팀 프로젝트로 진행되었으며, 이 글에서는 내가 맡았던 주요 작업과 전략적 접근에 대해 기술한다. 이번 경진대회에도 마찬가지로 팀장을 맡았다.
- EDA
- Text Data 특성 및 분포 분석
- 문장 길이, 단어 빈도, 토픽 빈도, 토큰 수 등 분석
- Train/Validation/Test Set 차이점 분석
- 대화 - 요약 간 상관관계 분석
- TF-IDF 후 Cosine Similarity 통해 유사도 분석(중복 단어 확인)
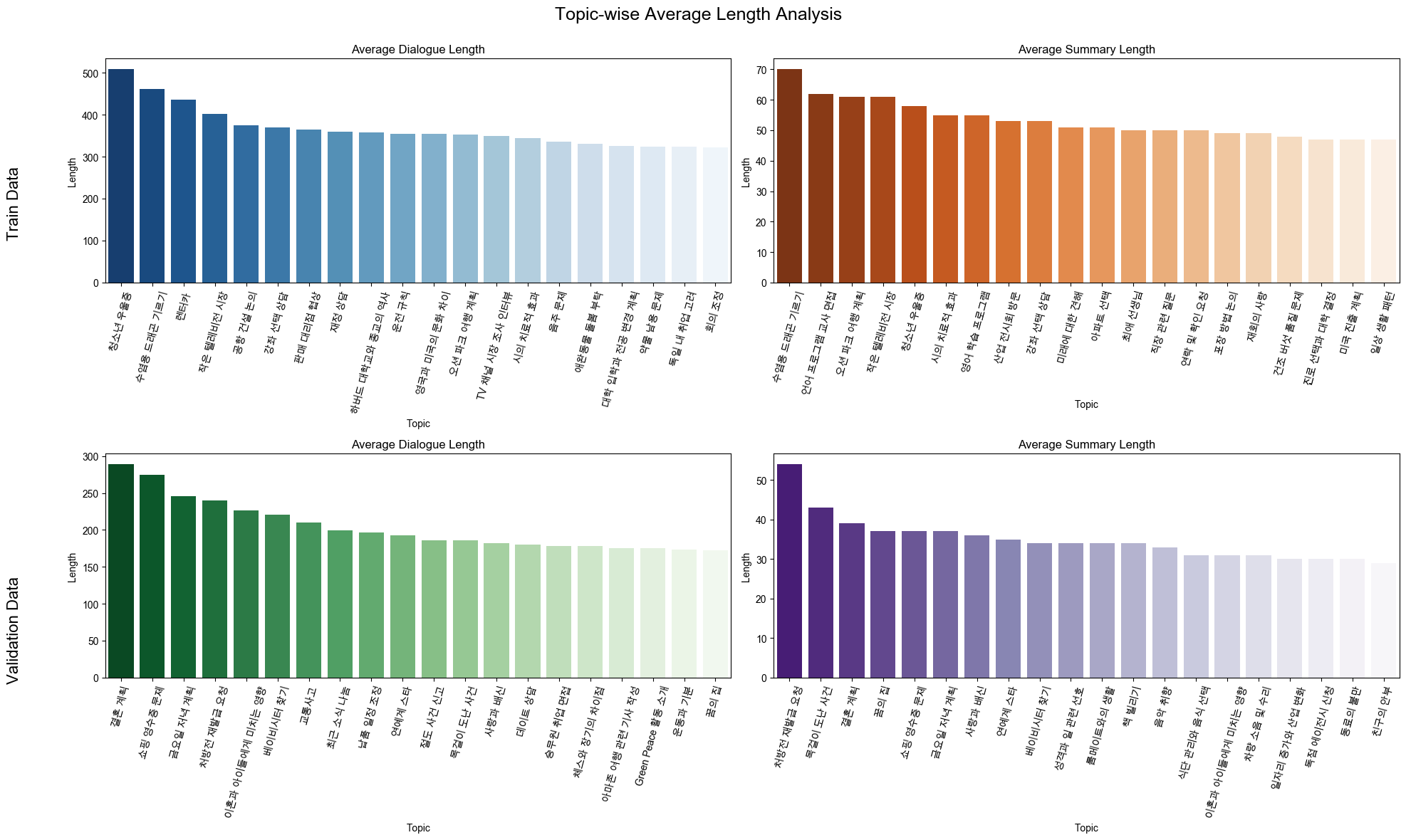 Topic 별 평균 문장 길이
Topic 별 평균 문장 길이
 단어 빈도 wordcloud 시각화
단어 빈도 wordcloud 시각화
- Data PreProcessing
- 텍스트 정규화, 불용어 제거, 토큰화 등 전처리
- Sequence Length 조절 및 Padding/Truncation 전략 수립
- Pre-trained Tokenizer 활용
- 실험 및 기록
- WandB(Weights & Biases)를 도입하여 모든 실험을 체계적으로 기록 및 관리
- hydra를 사용해 하이퍼파라미터를 효율적으로 관리하고 다양한 실험을 자동화
- 팀원들에게 WandB 사용 가이드를 직접 작성 및 공유하여 협업 효율성 증대
 WandB
WandB
- Modeling
- Model Architecture
- KoBART: 한국어 요약에 특화된 BART 모델
- Model Architecture
3. DataSet
경진대회에서 제공된 Dataset는 다음과 같았다.
- Train
- 총 12,457개의 데이터
train.csv파일에dialogue,summary, 등 컬럼이 포함- 데이터는 다양한 주제와 길이의 Text 로 구성
- Test
- 총 499개의 원문 텍스트
test.csv파일에dialogue컬럼이 포함되어 있으며, 예측 결과를 제출할 때 사용
4. 최종 결과
최종적으로 9개 팀 중 2위로 대회를 마무리했다.
이번엔 투자한 시간이 적었기에 예상하지 못했지만 높은 순위를 기록했다.
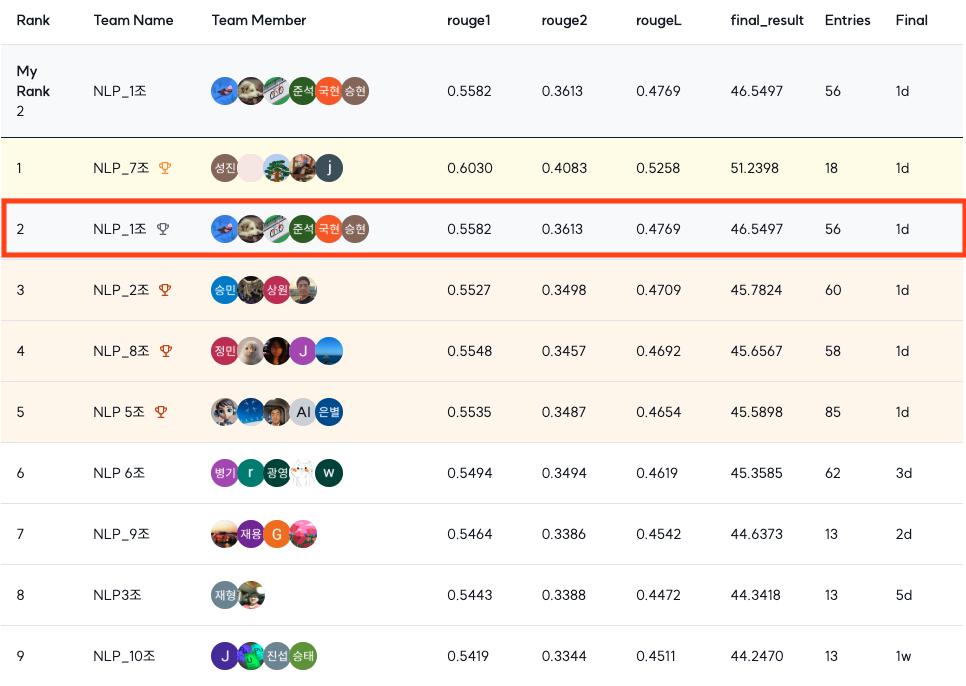
- Public Score
- rouge1: 0.5827
- rouge2: 0.3986
- rougeL: 0.5095
- final_result: 49.6957
- Private Score:
- rouge1: 0.5582
- rouge2: 0.3613
- rougeL: 0.4769
- final_result: 46.5497
회고
이 섹션은 Upstage AI Lab NLP 경진대회를 통해 경험한 문제와 해결과정에 대한 회고를 담았다.
문제 & 해결 과정
문제
이번에는 이전보다 코드에서 에러적인 문제를 훨씬 많이 접했는데, 그중 예시를 들자면 다음과 같다.
에러 유형: HFValidationError: Repo id must be in the form ‘repo_name’
원인: 모델 추론 시 from_pretrained() 함수를 사용하여 모델을 불러오려 했으나, Hugging Face 라이브러리가
로컬 경로를 유효하지 않은 온라인 저장소 ID로 잘못 인식하여 발생했다. local_files_only=True
인자를 사용했음에도 오류가 해결되지 않아 라이브러리의 경로 해석 방식에 문제가 있었음을 알 수 있었다.
공식 문서나 GitHub 등을 Search 해보니 Hugging Face에서 종종 이러한 에러가 자주 발생한다고 한다.
해결 과정
AI가 발전하고 있지만 (GPT, Gemini, Cursor 등) AI에만 의존하기보다는 이번 기회에 에러를 해결하기 위해
공식 문서나 블로그 등을 많이 찾아보며 해결할 수 있었다. (GPT가 없던 세대는 대체 어떻게 해결해나갔을지..)
위에서 설명한 문제의 경우, 커널 재시작을 하면 해결되거나 다시 에러가 발생하는 등의 불규칙적인 패턴을 보인다.
(다른 분들도 비슷한 에러를 겪었지만 저와 동일한 방법으로 해결한 사례가 많은 것 같습니다.)
원인을 분석해 본 결과, 해당 에러가 발생할 수 있는 상황은 크게 세 가지로 다음과 같다.
하지만 나는 이 모든 조건을 확인했을 때 어느 하나도 만족하지 못했다.
(혹시 독자분들 중에 이 에러의 명확한 원인을 알거나 해결해본 경험이 있으시면 댓글 부탁드립니다. 🙏)
- 경로 오타 (상대경로, 절대경로 모두 적용 확인)
- 로컬에 저장한 모델의 경로 안에 특정 파일(예:
config.yaml)이 없을 때 - 라이브러리 버전 문제
인사이트
아쉬웠던 점
이번 대회에서는 인턴십 준비, 이력서 및 포트폴리오 수정 등으로 인해 이전만큼 시간을 투자하지 못했다.
그 결과, 가장 기대하고 참여하고 싶었던 NLP Task임에도 불구하고 다양한 모델과 분석, 전처리 기법을
시도해보지 못한 점이 가장 큰 아쉬움으로 남는다.
알게 된 점
NLP Task의 전반적인 프로세스와 필수적인 전처리(정규화, Tokenizer) 등을 알 수 있었다.
hydra, UV(pip대신 사용한 빠른 패키지 관리 도구) 같은 다양한 툴의 사용법을 익혔다.