[Upstage AI Lab] 19주차 - NLP Advanced
[Upstage AI Lab] 19주차 - NLP 심화 학습 내용
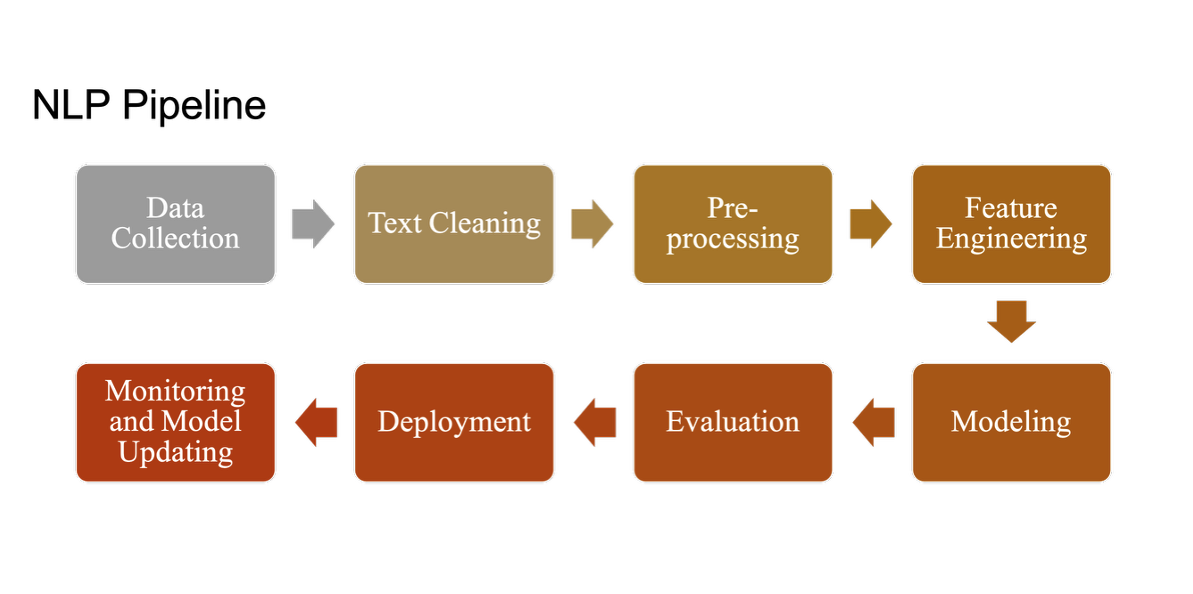
들어가며
이번 글에서는 BERT, GPT, BART 등 현대 NLP의 핵심 모델들과 LLM 시대의 최신 트렌드를 정리했다.
NLP Model 흐름
1. BERT 이전 기술들의 발전 과정
BERT 등장 이전까지 자연어처리 기술은
RNN → Seq2Seq → Attention → Transformer 순으로 발전해왔다.
각 기술은 이전 기술의 한계를 해결하며 현재 LLM의 기반이 됨
RNN (Recurrent Neural Network)
- 순차적 데이터 처리에 특화된 신경망
- 장점: 시퀀스 데이터의 순서 정보 활용
- 단점: 기울기 소실 문제, 병렬 처리 불가
Seq2Seq (Sequence-to-Sequence)
- Encoder-Decoder 구조로 시퀀스 변환 작업 수행
- 기계 번역, 요약 등의 작업에 활용
- 단점: 고정 길이 벡터의 정보 압축 한계
Attention Mechanism
- Seq2Seq의 정보 병목 현상 해결
- 중요한 정보에 집중할 수 있는 메커니즘
- 모든 인코더 출력을 디코더에서 활용 가능
Transformer
- Self-Attention을 통한 병렬 처리 가능
- RNN 없이도 순서 정보 처리 (Positional Encoding)
- 현재 모든 LLM의 기반 아키텍처
2. Transfer Learning
Transfer Learning은 특정 도메인 Task로부터 학습된 모델을 비슷한 도메인 task 수행에 재사용하는 기법
Transfer Learning의 핵심 아이디어
- 대량의 범용 데이터로 모델을 사전 훈련 (Pre-training)
- 특정 태스크 데이터로 모델을 미세 조정 (Fine-tuning)
- 적은 데이터로도 높은 성능 달성 가능
ELMo (Embeddings from Language Models)
- 양방향 언어 모델을 통한 문맥적 임베딩
- 동적 임베딩: 문맥에 따라 달라지는 단어 표현
- BERT 등장의 중요한 선행 연구
3. BERT
BERT는 양방향 Transformer Encoder를 사용한 획기적인 언어 모델이다.
Masked Language Modeling과 Next Sentence Prediction 기법으로 문맥을 깊이 이해한다.
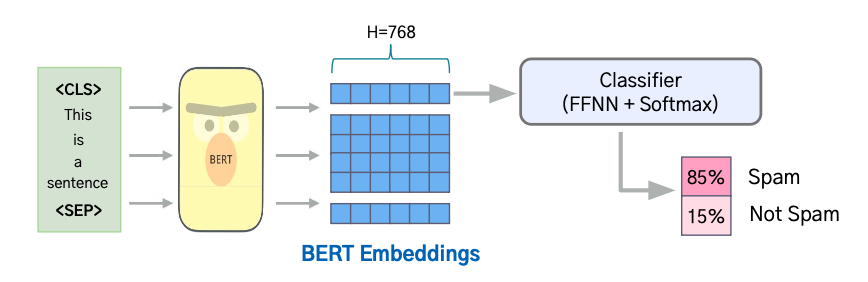
BERT의 핵심 특징
- Bidirectional: 양방향으로 문맥 이해
- Masked Language Modeling (MLM): 일부 단어를 마스킹하여 예측
- Next Sentence Prediction (NSP): 문장 간 관계 학습
- Transfer Learning: Pre-training + Fine-tuning
BERT 모델 구조
- Multi-layer Bidirectional Transformer Encoder
- Self-Attention 메커니즘으로 모든 위치 간 관계 학습
- Position Embedding + Token Embedding + Segment Embedding
BERT의 학습 방법
- Pre-training: 대량의 텍스트로 MLM + NSP 학습
- Fine-tuning: 특정 태스크 데이터로 미세 조정
BERT로 해결 가능한 Downstream Tasks
- Single Sentence Classification: 감정 분석, 스팸 분류
- Single Sentence Tagging: 개체명 인식, 품사 태깅
- Question Answering: 기계독해, QA 시스템
- Text Pair Classification: 문장 유사도, 자연어 추론
4. GPT
GPT는 Transformer Decoder를 기반으로 한 생성형 언어 모델이다.
자기회귀적 언어 모델링을 통해 자연스러운 텍스트 생성이 가능하다.
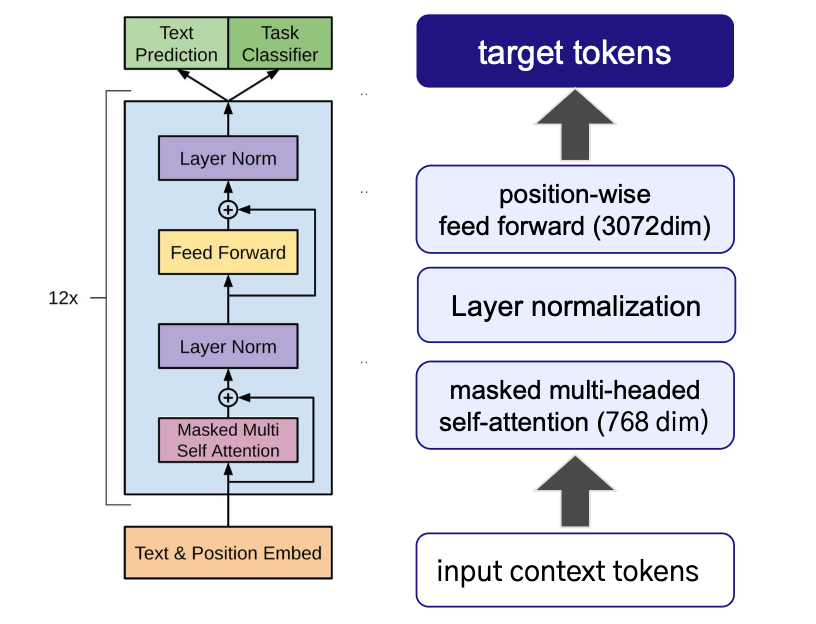
GPT-1의 등장 배경
- 이전 모델의 한계: 레이블 데이터 의존성, 제한적인 아키텍처
- Unsupervised Pre-training: 대량의 무라벨 텍스트 활용
- Transformer Decoder: 순차적 텍스트 생성에 특화
GPT 모델 구조
- Multi-layer Transformer Decoder
- Causal Self-Attention: 이전 토큰만 참조
- Autoregressive Generation: 순차적 토큰 생성
GPT의 Pre-training & Fine-tuning
- Pre-training: 다음 토큰 예측 (Language Modeling)
- Fine-tuning: 태스크별 헤드 추가 후 미세 조정
5. GPT-2와 GPT-3의 혁신
GPT-2, GPT-3는 모델 크기의 대폭 확장을 통해 놀라운 생성 능력을 보여줬다.
Few-shot Learning과 In-context Learning의 가능성을 제시했다.
GPT-2의 특징
- 1.5B 매개변수 (GPT-1의 10배)
- Zero-shot Task Transfer: Fine-tuning 없이 태스크 수행
- 고품질 텍스트 생성
- 당시 공개 보류 (악용 우려)
GPT-3의 혁신
- 175B 매개변수: 사상 최대 규모
- In-context Learning: 예시만으로 태스크 학습
- Few-shot Learning: 적은 예시로 높은 성능
- Emergent Abilities: 예상치 못한 능력 출현
GPT 시리즈의 한계
- 높은 계산 비용
- Hallucination: 사실과 다른 내용 생성
- 일관성: 긴 텍스트에서의 일관성 유지 어려움
6. BART
BART는 BERT의 양방향 인코딩과 GPT의 자기회귀 생성을 결합한 모델이다.
다양한 노이즈 제거 태스크를 통해 강력한 생성 능력을 학습한다.
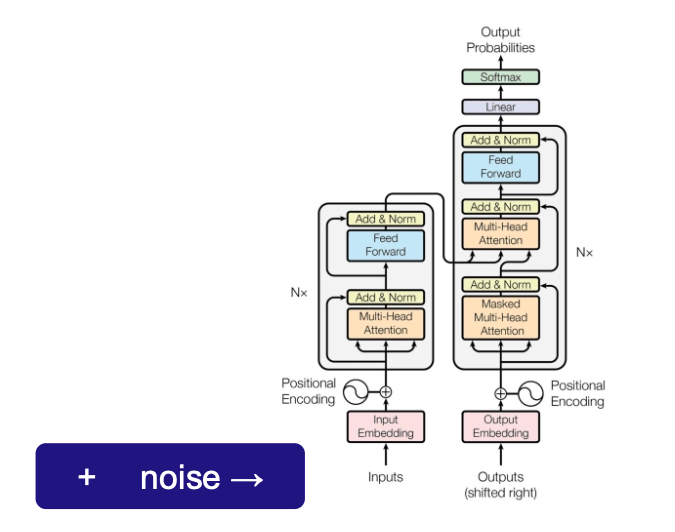
BART의 구조적 특징
- Encoder: BERT와 유사한 양방향 Transformer
- Decoder: GPT와 유사한 자기회귀 Transformer
- Cross-Attention: 인코더와 디코더 연결
BART vs 다른 모델들
- vs BERT: 생성 능력 추가
- vs GPT: 양방향 문맥 이해
- vs T5: 더 자유로운 노이즈 패턴