[Upstage AI Lab] 18주차 - NLP Basic
[Upstage AI Lab] 18주차 - NLP Basic 학습 내용 정리

들어가며
이번 글에서는 자연어 처리(Natural Language Processing) 분야의 기본 이론과 개념을 정리했다.
텍스트 전처리부터 최신 트랜스포머 모델까지, NLP의 전체적인 흐름을 학습하며 정리한 내용이다.
Natural Language Processing
1. NLP 란? (자연어 처리)
Generative Model은 주어진 데이터로부터 새로운 데이터를 생성해내는 모델을 의미한다.
이미지, 텍스트, 영상, 소리 등 다양한 형태의 데이터를 만들어내는 데 활용되고 있으며
최근 딥러닝 분야에서 활발히 연구되고 있다.
자연언어 처리가 어려운 이유
- 모호성: 단어와 문장은 문맥에 따라 여러 의미를 가질 수 있다.
- 예를 들어, “배”는 먹는 배, 타는 배, 신체 부위의 배 등 다양한 의미를 가질 수 있다.
- 문맥 의존성: 단어와 구문의 의미는 주변 텍스트와 실제 세계 지식에 크게 의존한다.
- 같은 단어라도 어떤 문맥에서 사용되느냐에 따라 전혀 다른 의미를 가질 수 있다.
- 다양성과 창의성: 인간은 같은 아이디어를 표현하는 데 있어 매우 다양한 방법을 사용
- 관용구 및 비유적 표현: “발이 넓다”와 같은 관용구나 비유적인 표현은 단어 그대로의 의미로는 해석할 수 없음
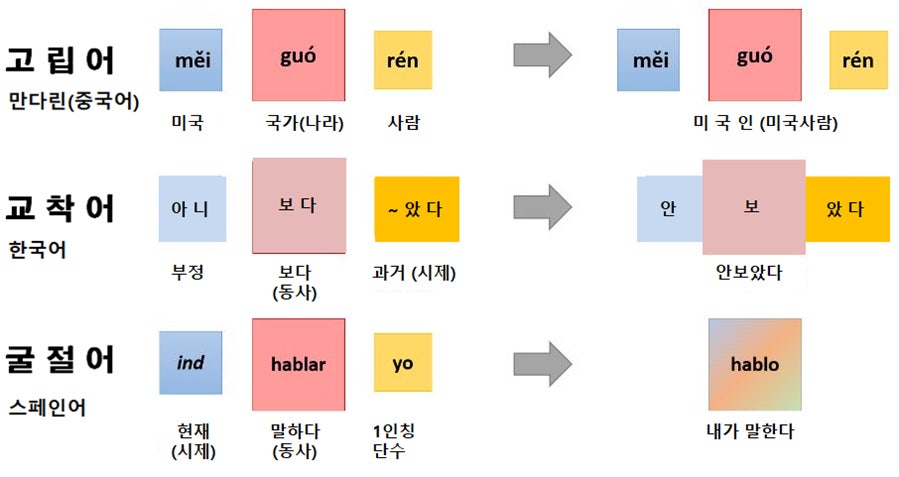
2. ‘한국어’에서 자연언어 처리가 더 어려운 이유
한국어는 교착어로 어근과 접사에 의해 단어의 의미와 기능이 정해진다.
타 언어에 비해 같은 단어라도 무수히 많은 조합이 존재
단어 순서 및 주어 생략
- 한국어는 단어의 순서가 문장의 의미를 결정하는 결정적인 요소는 아님
- 따라서 순서를 바꾸어도 전체 맥락을 이해하는데 전혀 문제가 없음
- 이러한 어순이 바뀌어도 문법적으로도 지장이 없는 경우가 많음
문제점
- 어순이 다르나 의미는 동일한 정보로 처리하는 것이 쉽지 않기 때문에 컴퓨터에게는 매우 어려움
- 또한 주어를 생략하고 표현하는 언어적 특성 역시 문제임
띄어쓰기
- 한국어에서 띄어쓰기는 아직 정착단계, 표준이 계속 변화
- 또한 일반적으로 띄어쓰기가 없어도 어느 정도의 의미전달이 가능
- 그렇기에 띄어쓰기가 올바른 문장과 틀린 문장이 혼재
- 이로 인해 추후 정제단계 중 하나인 ‘분절’ 단계에서 컴퓨터는 띄어쓰기가 없는 단어에서 혼란
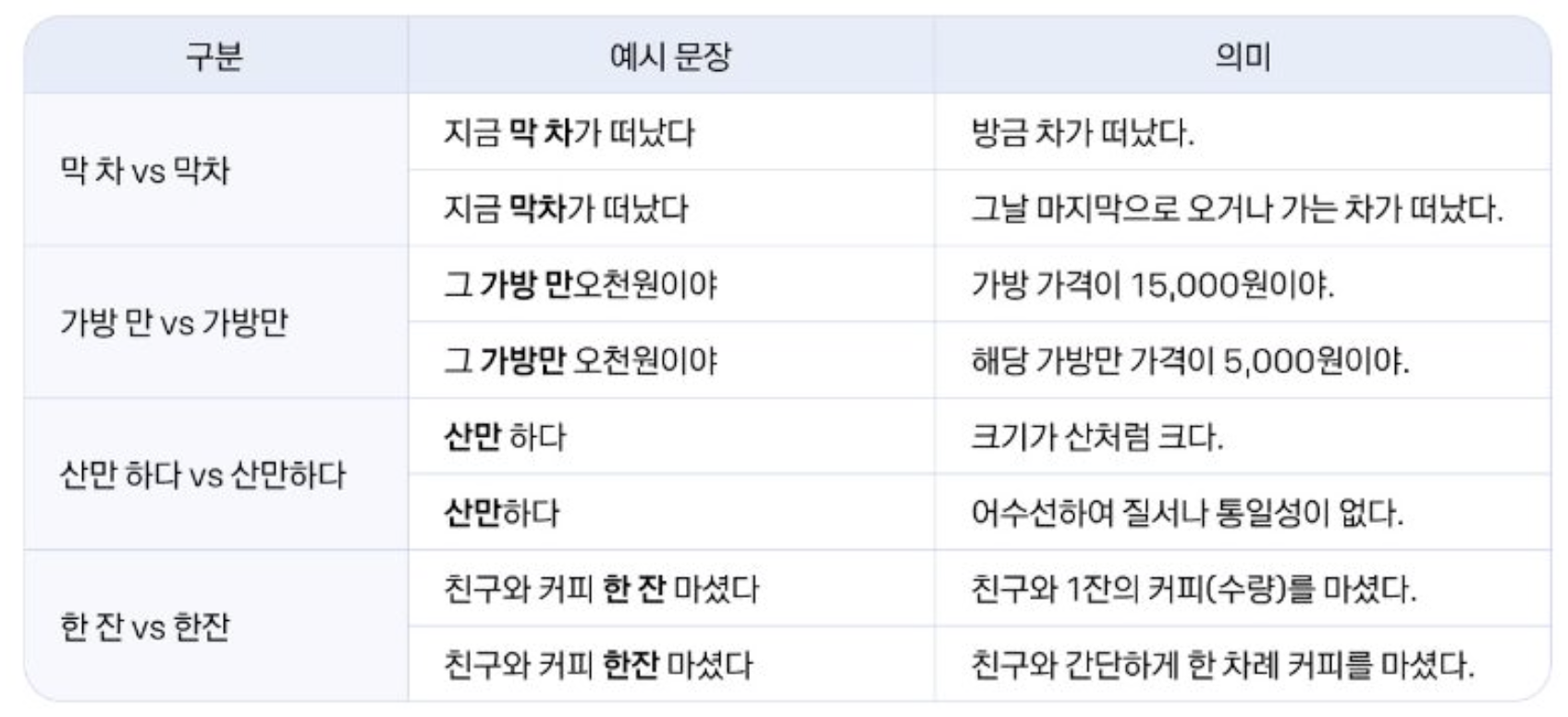 한국어에서 자연언어처리가 어려운 이유 예시
한국어에서 자연언어처리가 어려운 이유 예시
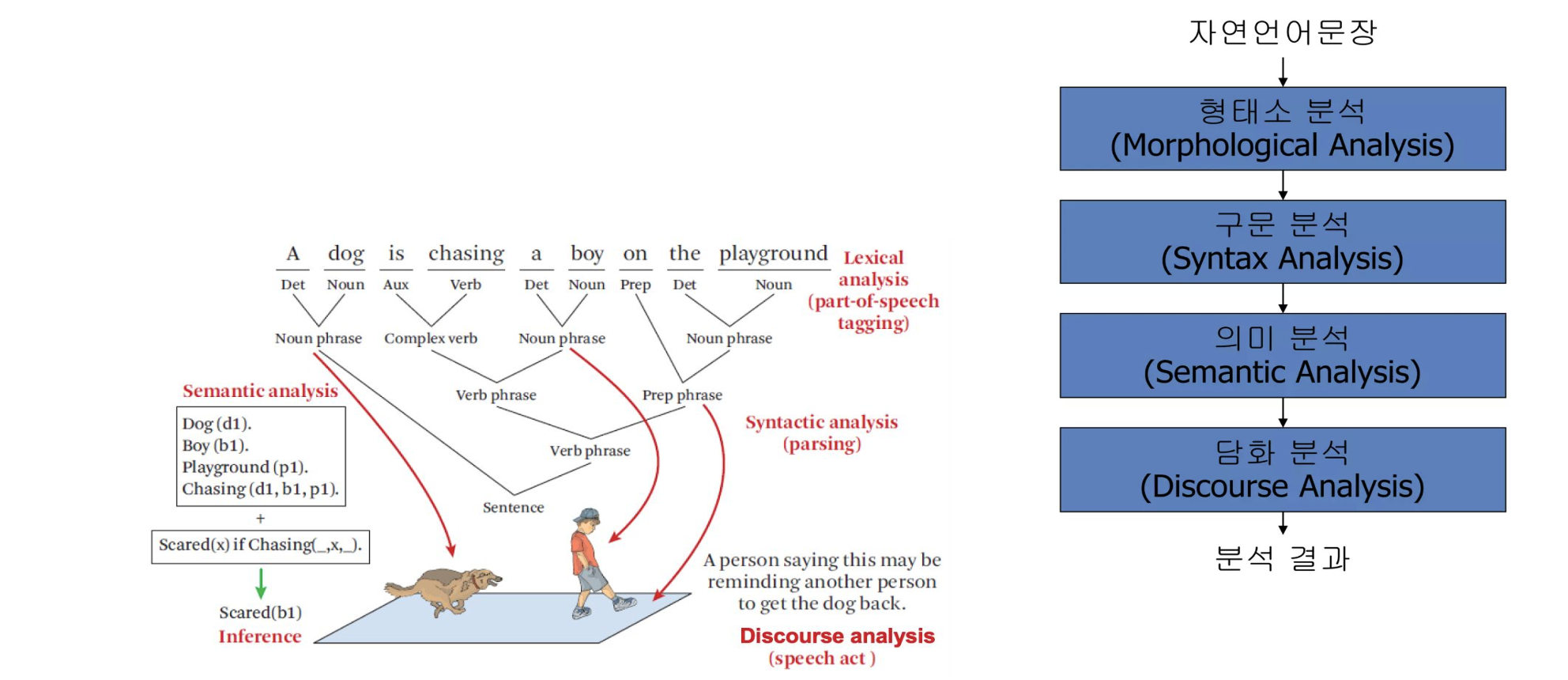
3. 언어학 이란?
언어학은 인간 고유의 정신적인 능력인 언어를 “과학적으로” 연구하는 학문
NLP를 학습하기 앞서 언어학에서 기본적인 개념을 이해하는 것이 중요
언어학의 접근 방법
- 규칙기반 접근: 이론언어학적인 연구를 통해 얻어진 형식화된 문법을 이용
- 통계기반 접근: 전자화된 텍스트의 분석을 통해 언어 단위의 분포와 빈도에 관한 정보를 이용
- 딥러닝 기반 접근: 인공 신경망의 많은 양의 자료를 통해 학습한 결과를 바탕으로 산출되는 규칙
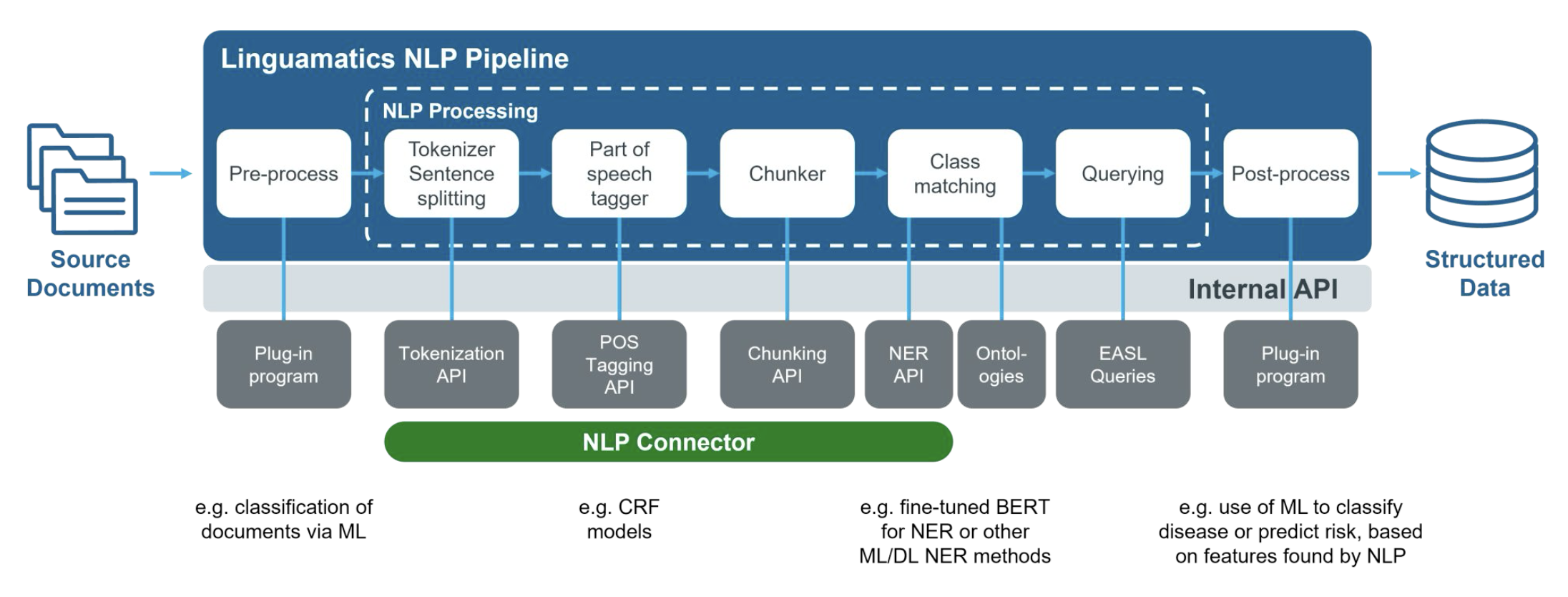 전통적인 자연언어처리 파이프라인
전통적인 자연언어처리 파이프라인
음절 (Syllable)
- 음절은 언어를 말하고 들을 때, 하나의 덩어리로 여겨지는 가장 작은 말소리의 단위
- ex: ‘한’, ‘국’, ‘어’는 각각 하나의 음절이며, ‘한국어’라는 단어는 세 개의 음절로 이루어짐
 음절
음절
형태소 (Morpheme)
- 형태소는 언어에서 의미를 가지는 가장 작은 단위
- 형태소를 쪼개면 더 이상 기능이나 의미를 갖지 않음
- 일반적으로 자연언어처리에서는 분석의 기본이 되는 토큰으로써 형태소를 이용함
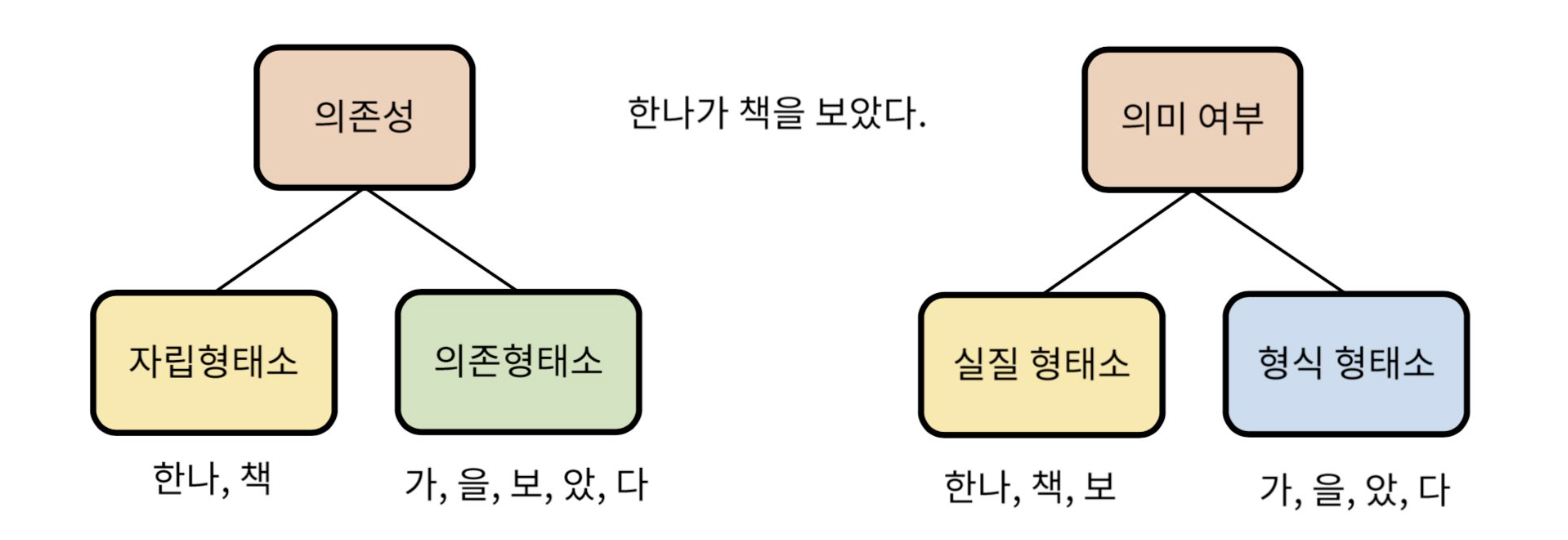 형태소
형태소
어절 및 품사
- 어절은 한 개 이상의 형태소가 모여 구성된 단위. 자연언어는 어절단위로 띄어쓰기 되어 발화 또는 서술됨
- 품사는 단어를 문법상 의미, 형태, 기능에 따라 분류한 종별을 의미
- NLP에서는 품사를 분석해 구분하는 작업을 POS(Part Of Speech) Tagging이라고 함
- 여러 라이브러리를 통해 구현
4. Text Preprocess (텍스트 전처리) 란?
Text Preprocess란 컴퓨터가 자연어를 분석하고 학습할 수 있도록 정제하고 가공하는 과정을 의미
이는 Data Preprocessing의 한 종류로, NLP 모델의 성능에 큰 영향을 미친다.
주로 아래와 같은 방법들을 사용한다.
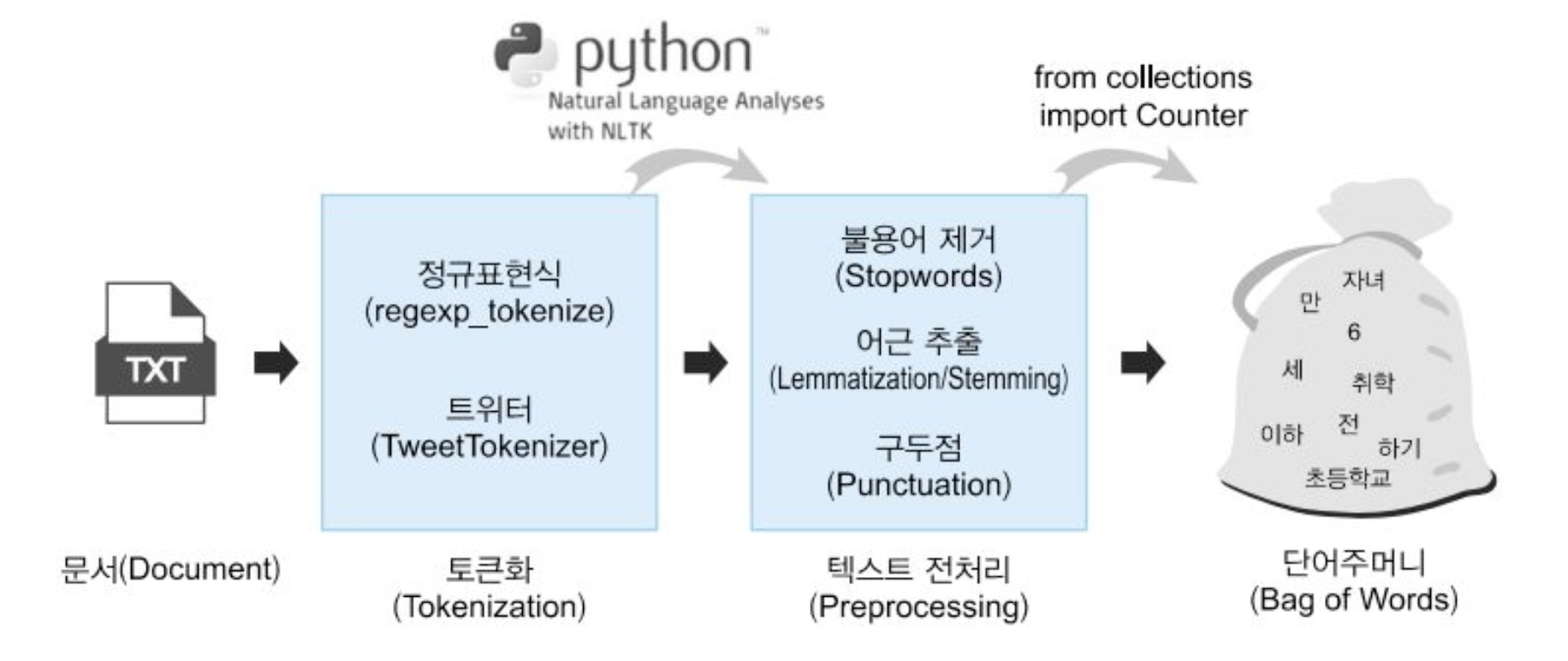
- 클리닝(Cleaning): HTML 태그, 특수문자, 이모티콘 등 제거
- 정규표현식(Regular Expression): 복잡한 패턴을 가진 문자열을 찾고 제거하거나 다른 문자로 대체할 때 사용
- 정규화(Normalization)
- 불용어 (Stopword) 제거: 분석에 큰 의미가 없는 단어들(예: ‘나는’, ‘은’, ‘는’)을 제거하여 노이즈를 줄임
- 어간추출(Stemming): 품사를 고려하지 않고 단순히 단어의 뒷부분을 잘라내는 방법
- 표제어추출(Lemmatizing): 단어의 품사 정보를 고려하여 원형을 찾아내는 작업, 어간 추출보다 더 정확
대표적인 Library
- KoNLPy: 한국어 자연언어처리를 위한 대표 Library
- NLTK: 영어로 된 텍스트의 자연처리를 위한 대표적인 Library
5. Tokenization (토큰화) 란?
Tokenization는 주어진 데이터를 토큰(Token)이라 불리는 단위로 나누는 작업이다.
토큰이 되는 기준은 다를 수 있음(어절, 단어, 형태소, 음절, 자소 등)
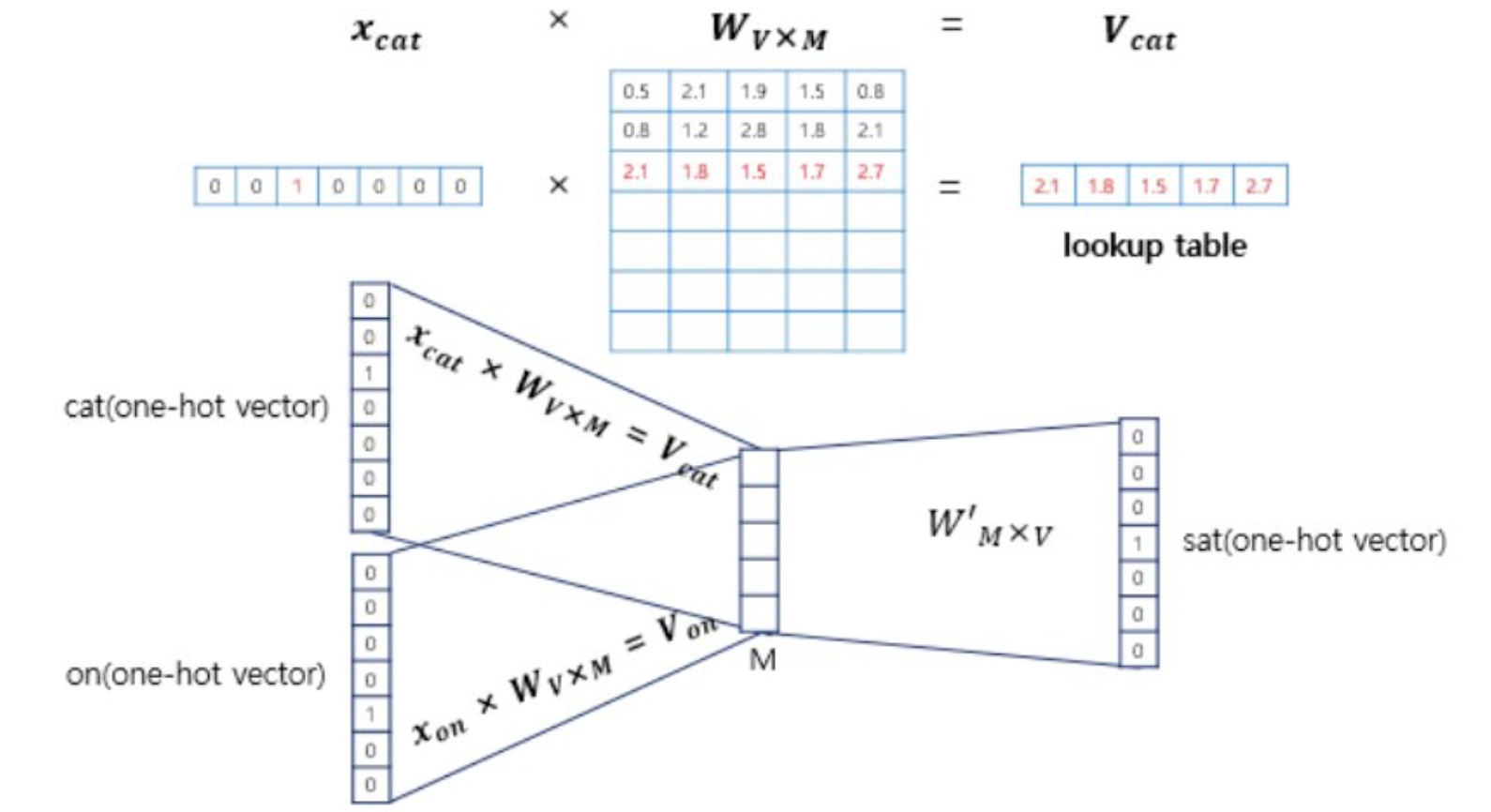
- 단어 의미를 밀집 Vector로 표현하기 위해 단어들을 사전화
- Tokenization 고려사항
- 구두점이나 특수 문자를 단순 제외 (Cleaning 작업)
- 줄임말과 단어 내 띄어쓰기
- 문장 토큰화: 단순 마침표를 기준으로 자를 수 없음
한국어 토큰화의 어려움
- 영어는 New York과 같은 합성어나 he’s 와 같이 줄임말에 대한 예외처리만 한다면
- 띄어쓰기를 기준으로 하는 띄어쓰기 토큰화를 수행해도 단어 토큰화가 잘 작동
- 하지만 영어와는 달리 한국어에는 조사라는 것이 존재
- ex: ‘그가’, ‘그를’, ‘그와’, ‘그는’과 같이 다양한 조사가 붙음
- 같은 단어임에도 서로 다른 조사가 붙어서 다른 단어로 인식
Konlpy 주요 함수
- morphs : 형태소 추출
- pos : 품사 태깅
- nouns : 명사 추출
실습 코드
- 아래는 간단한 실습 예제이다.
- 전체 코드는 GitHub에서 확인 가능
1
2
3
4
5
6
7
8
9
10
11
12
# konlpy 관련 패키지 import
from konlpy.tag import Okt
from konlpy.tag import Kkma
from konlpy.tag import Hannanum
from konlpy.tag import Komoran
from konlpy.tag import Twitter
kkma = Kkma()
okt = Okt()
komoran = Komoran()
hannanum = Hannanum()
twitter = Twitter()
- morphs (형태소 추출)
1
2
3
4
5
6
# konlpy 의 라이브러리 형태소 비교
print("okt 형태소 분석 :", okt.morphs(u"집에 가면 감자 좀 쪄줄래?"))
print("kkma 형태소 분석 : ", kkma.morphs(u"집에 가면 감자 좀 쪄줄래?"))
print("hannanum 형태소 분석 : ", hannanum.morphs(u"집에 가면 감자 좀 쪄줄래?"))
print("komoran 형태소 분석 : ", komoran.morphs(u"집에 가면 감자 좀 쪄줄래?"))
print("twitter 형태소 분석 : ", twitter.morphs(u"집에 가면 감자 좀 쪄줄래?"))
okt 형태소 분석 : ['집', '에', '가면', '감자', '좀', '쪄줄래', '?'] kkma 형태소 분석 : ['집', '에', '가', '면', '감자', '좀', '찌', '어', '주', 'ㄹ래', '?'] hannanum 형태소 분석 : ['집', '에', '가', '면', '감', '자', '좀', '찌', '어', '줄', '래', '?'] komoran 형태소 분석 : ['집', '에', '가', '면', '감자', '좀', '찌', '어', '주', 'ㄹ래', '?'] twitter 형태소 분석 : ['집', '에', '가면', '감자', '좀', '쪄줄래', '?']
- pos (품사 태깅)
1
2
3
4
5
6
# konlpy 의 라이브러리 품사태깅 비교
print("okt 품사태깅 :", okt.pos(u"집에 가면 감자 좀 쪄줄래?"))
print("kkma 품사태깅 : ", kkma.pos(u"집에 가면 감자 좀 쪄줄래?"))
print("hannanum 품사태깅 : ", hannanum.pos(u"집에 가면 감자 좀 쪄줄래?"))
print("komoran 품사태깅 : ", komoran.pos(u"집에 가면 감자 좀 쪄줄래?"))
print("twitter 품사태깅 : ", twitter.pos(u"집에 가면 감자 좀 쪄줄래?"))
okt 품사태깅 : [('집', 'Noun'), ('에', 'Josa'), ('가면', 'Noun'), ('감자', 'Noun'), ('좀', 'Noun'), ('쪄줄래', 'Verb'), ('?', 'Punctuation')]
kkma 품사태깅 : [('집', 'NNG'), ('에', 'JKM'), ('가', 'VV'), ('면', 'ECE'), ('감자', 'NNG'), ('좀', 'MAG'), ('찌', 'VV'), ('어', 'ECS'), ('주', 'VXV'), ('ㄹ래', 'EFQ'), ('?', 'SF')]
hannanum 품사태깅 : [('집', 'N'), ('에', 'J'), ('가', 'P'), ('면', 'E'), ('감', 'P'), ('자', 'E'), ('좀', 'M'), ('찌', 'P'), ('어', 'E'), ('줄', 'P'), ('래', 'E'), ('?', 'S')]
komoran 품사태깅 : [('집', 'NNG'), ('에', 'JKB'), ('가', 'VV'), ('면', 'EC'), ('감자', 'NNP'), ('좀', 'MAG'), ('찌', 'VV'), ('어', 'EC'), ('주', 'VX'), ('ㄹ래', 'EF'), ('?', 'SF')]
twitter 품사태깅 : [('집', 'Noun'), ('에', 'Josa'), ('가면', 'Noun'), ('감자', 'Noun'), ('좀', 'Noun'), ('쪄줄래', 'Verb'), ('?', 'Punctuation')]
- nouns (명사 추출)
1
2
3
4
5
6
# konlpy 의 라이브러리 명사 추출
print("okt 명사 추출 :", okt.nouns(u"집에 가면 감자 좀 쪄줄래?"))
print("kkma 명사 추출 : ", kkma.nouns(u"집에 가면 감자 좀 쪄줄래?"))
print("hannanum 명사 추출 : ", hannanum.nouns(u"집에 가면 감자 좀 쪄줄래?"))
print("komoran 명사 추출 : ", komoran.nouns(u"집에 가면 감자 좀 쪄줄래?"))
print("twitter 명사 추출 : ", twitter.nouns(u"집에 가면 감자 좀 쪄줄래?"))
okt 명사 추출 : ['집', '가면', '감자', '좀'] kkma 명사 추출 : ['집', '감자'] hannanum 명사 추출 : ['집'] komoran 명사 추출 : ['집', '감자'] twitter 명사 추출 : ['집', '가면', '감자', '좀']
6. 정규화 (Normalization)
정규화는 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어주는 작업이다.
이를 통해 동일한 의미를 가진 여러 형태의 단어들을 하나로 통일시킬 수 있다.
불용어 (Stop Words)
- 분석에 큰 의미가 없는 단어로 코퍼스 내에 빈번하게 등장하나, 실질적으로 의미를 갖고 있지 않은 용어
- 전처리 시 불용어로 취급할 대상을 정의하는 작업이 필요
- NLTK에서는 여러 불용어를 사전에 정의
Stemming (어간 추출)
- 어형이 변형된 단어로부터 접사 등을 제거하고 그 단어의 어간을 분리해내는 것
- 대표적으로 포터 스태머 알고리즘이 존재함
Lemmatization (표제어 추출)
- 품사 정보가 보존된 형태의 기본형으로 변환
- 표제어 추출에 가장 섬세한 방법은 형태학적 파싱
- 형태소란?
- 의미를 가진 가장 작은 단위
- 어간(stem): 단어의 의미를 담고 있는 단어의 핵심 부분
- 접사(affix): 단어에 추가적인 의미를 주는 부분
7. 편집거리 (Edit Distance)
편집거리는 두 문자열 간의 유사도를 측정하는 방법 중 하나로,
한 문자열을 다른 문자열로 변환하는데 필요한 최소 편집 횟수를 의미한다.
Levenshtein Distance
- 한 string s1을 s2로 변환하는 최소 횟수를 두 string 간의 거리로 정의
- 거리가 낮을수록 유사한 문자열로 판단함
- 예: ‘꿈을꾸는아이’에서 ‘아이오아이’로 바뀌기 위해서는 (꿈을꾸 → 아이오)로 바뀌고, 네번째 글자 ‘는’이 제거
편집 방법의 세 가지 분류
- Delete: ‘점심을먹자’ → ‘점심먹자’로 바꾸기 위해서는 ‘을’ 삭제
- Insert: ‘점심먹자’ → ‘점심을먹자’로 바꾸기 위해서는 반대로 ‘을’ 삽입
- Substitution: ‘점심먹자’ → ‘점심먹장’로 바꾸기 위해서는 ‘자’를 ‘장’으로 치환
8. 정규표현식 (Regular Expression)
정규표현식(Regex)은 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어다.
복잡한 문자열의 검색과 치환을 위해 사용되며, 문자열을 처리하는 모든 곳에서 사용된다.
정규표현식의 활용
- 원하는 규칙에 해당하는 문자만 남기거나 제거
- 규칙에 맞는 문자열 반환 등
- 단시간 내에 텍스트가 갖는 모든 패턴의 형태를 처리
- 파이썬에서는 re 라이브러리를 이용해 사용이 가능함
정규표현식 기본 패턴
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import re
# 숫자만 추출
text = "전화번호는 010-1234-5678입니다."
numbers = re.findall(r'\d+', text)
print(numbers) # ['010', '1234', '5678']
# 이메일 패턴 찾기
email_pattern = r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}'
text = "연락처: john.doe@example.com"
emails = re.findall(email_pattern, text)
print(emails) # ['john.doe@example.com']
# 한글만 추출
korean_pattern = r'[가-힣]+'
text = "Hello 안녕하세요 World 세상"
korean_words = re.findall(korean_pattern, text)
print(korean_words) # ['안녕하세요', '세상']
NLP 발전 과정
1. 규칙 기반 → 통계 기반 → 딥러닝 기반
NLP 기술은 규칙 기반에서 시작해 통계 기반을 거쳐 현재의 딥러닝 기반으로 발전해왔다.
각 단계마다 고유한 장단점과 특징을 가지고 있다.
규칙 기반 (Rule-based)
- 전문가가 직접 작성한 규칙을 통해 언어를 처리
- 장점: 명확한 논리, 해석 가능성
- 단점: 규칙 작성의 복잡성, 확장성 부족
 Rule-based
Rule-based
통계 기반 (Statistical-based)
- 코퍼스의 통계적 정보를 활용한 처리
- n-gram, TF-IDF 등의 방법 사용
- 장점: 자동화된 학습, 데이터 기반 접근
- 단점: 희소성 문제, 문맥 정보 부족
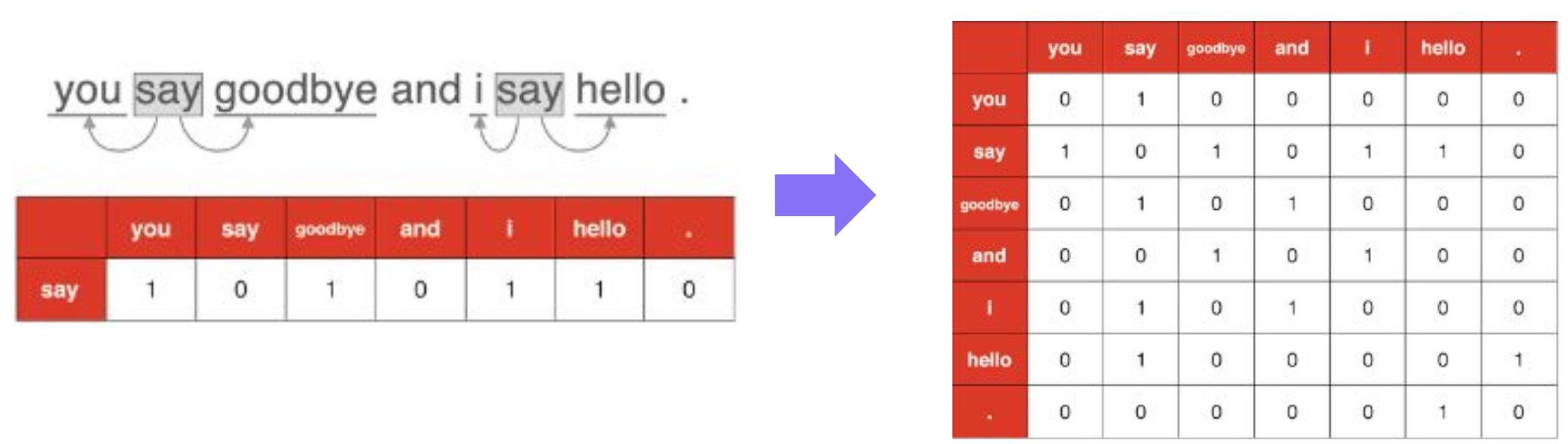 Statistical-based
Statistical-based
딥러닝 기반 (Deep Learning-based)
- 신경망을 통한 복잡한 패턴 학습
- Word2Vec, BERT, GPT 등의 모델
- 장점: 높은 성능, 문맥 이해
- 단점: 계산 비용, 해석 어려움
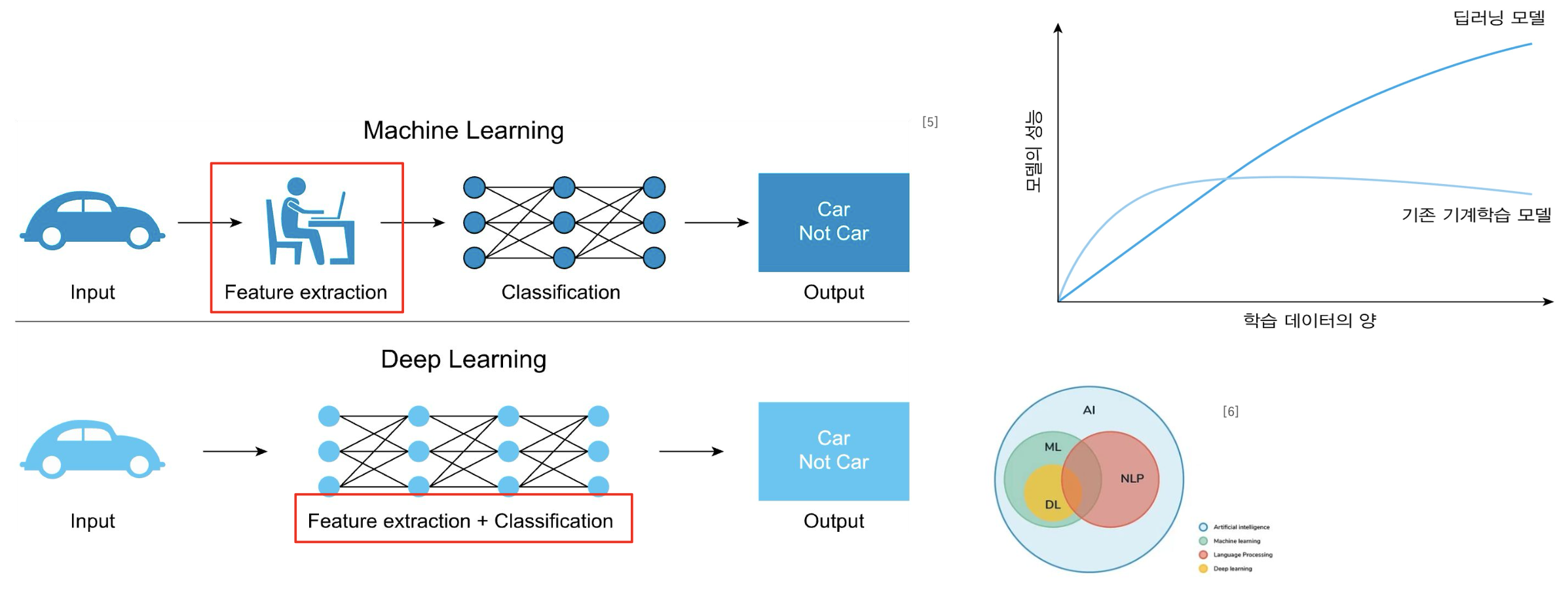 DL-based
DL-based
2. Transformer와 현대 NLP
Transformer 아키텍처의 등장으로 현대 NLP는 완전히 새로운 전환점을 맞았다.
Self-Attention 메커니즘을 통해 문맥을 더 잘 이해할 수 있게 되었다.
Pre-training & Fine-tuning
- Pre-training: 원하는 task 이외의 다른 task의 데이터를 이용하여 주어진 모델을 학습하는 과정
- Fine-tuning: 사전학습된 모델을 원하는 task에 해당하는 학습 방식으로 다시한번 재학습 시키는 과정
- 대표 모델: BERT, GPT, RoBERTa, T5
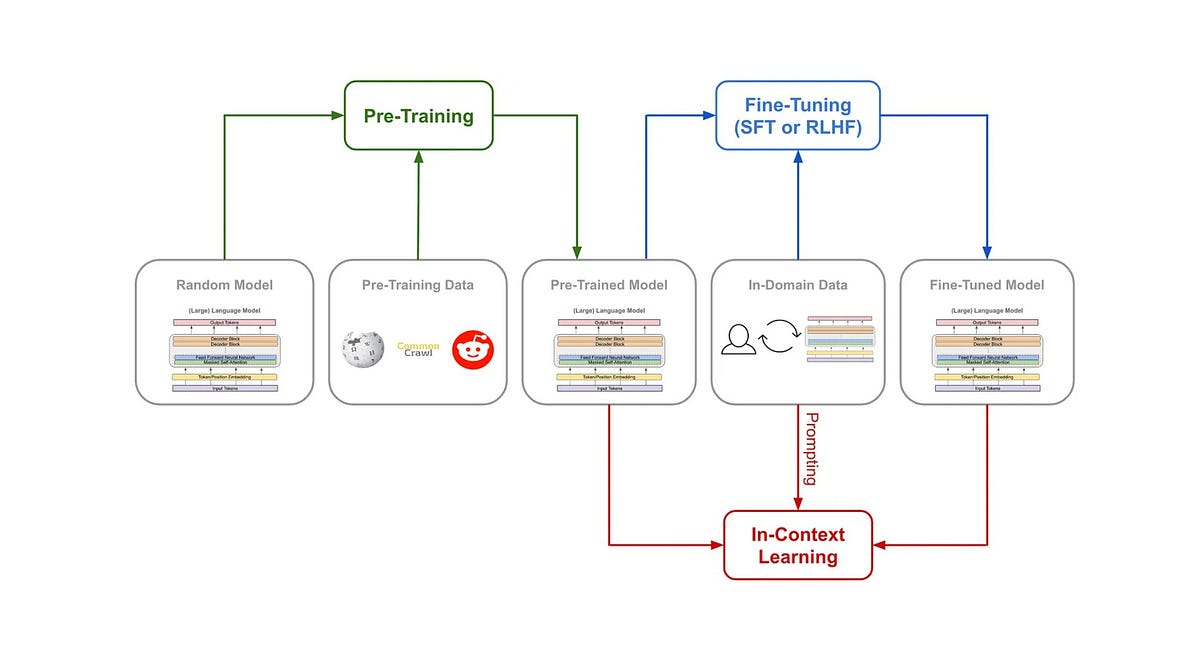 Pre_training-Fine_tuning
Pre_training-Fine_tuning
3. RNN과 Attention
RNN 계열 모델들은 순차적 데이터 처리에 특화되어 있으며,
Attention 메커니즘은 중요한 정보에 집중할 수 있게 해주는 핵심 기술이다.
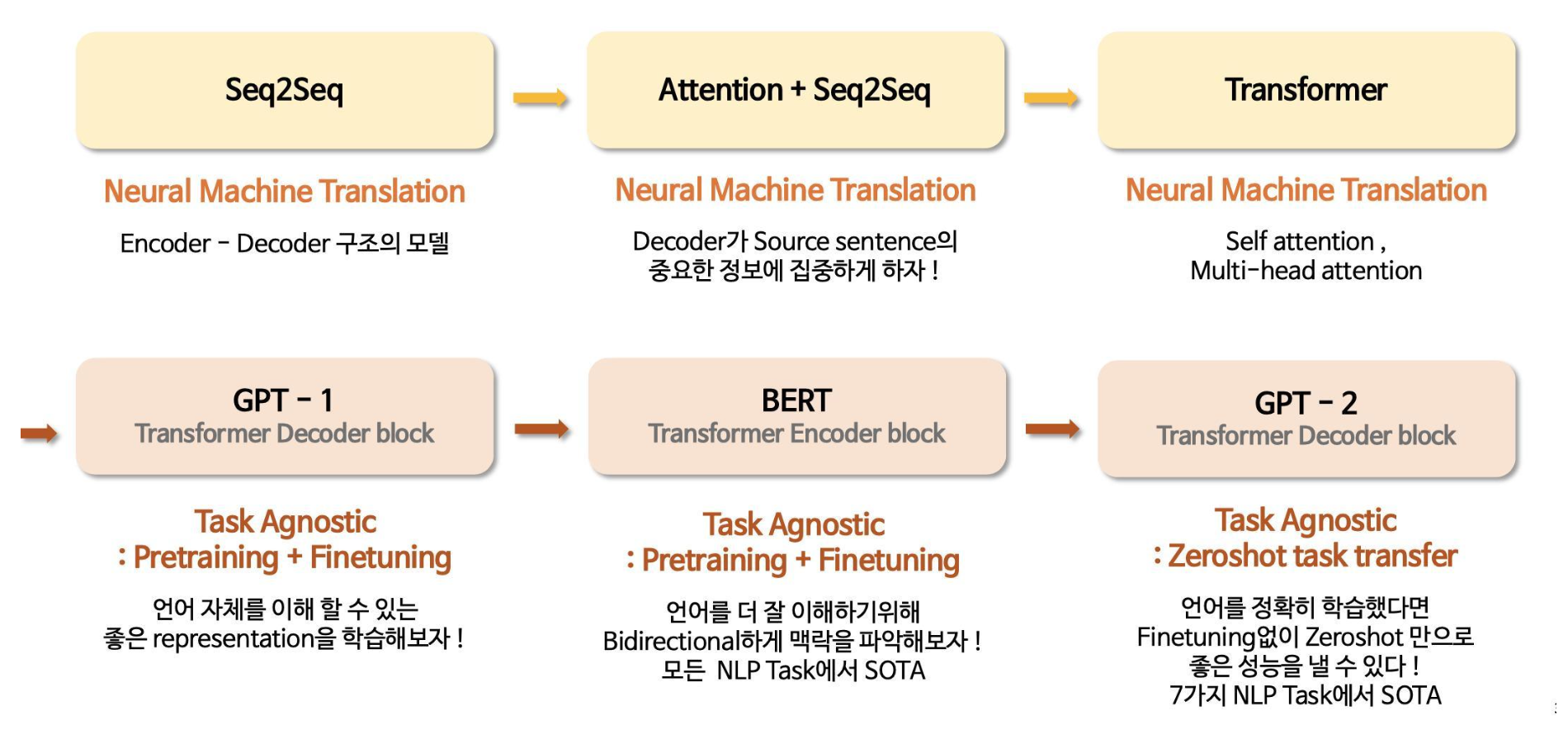 LLM 계보
LLM 계보
RNN의 한계와 발전
- Vanilla RNN: 기울기 소실 문제
- LSTM: Long-term dependency 해결
- GRU: 더 간단한 구조로 LSTM과 비슷한 성능
- Bidirectional RNN: 양방향 정보 활용
Attention 메커니즘
- 문제점: RNN의 bottleneck 문제 (마지막 hidden state에 모든 정보 압축)
- 해결책: 모든 시점의 정보를 가중합으로 활용
- Self-Attention: 입력 시퀀스 내부의 관계 모델링
- Multi-Head Attention: 여러 관점에서 attention 계산
4. NLP 윤리와 공정성
NLP 모델이 사회에 미치는 영향이 커지면서 윤리적 고려사항이 중요해졌다.
편향성, 공정성, 투명성 등이 주요 이슈로 대두되고 있다.
주요 윤리적 문제들
- 편향성 (Bias): 훈련 데이터의 편향이 모델에 반영
- 공정성 (Fairness): 특정 집단에 대한 차별적 결과
- 투명성 (Transparency): 모델 결정 과정의 해석 가능성
- 개인정보 보호: 훈련 데이터 내 민감한 정보 처리
- 가짜 정보 생성: 딥페이크 텍스트, 허위 정보 확산
해결 방안
- Debiasing 기법: 편향 제거 알고리즘 적용
- Fairness Metrics: 공정성 측정 지표 개발
- Explainable AI: 설명 가능한 AI 기술
- Human-in-the-loop: 인간 검수 체계 구축
- 윤리 가이드라인: 개발 및 배포 시 윤리 기준 준수