[Upstage AI Lab] 17주차 - CV Generation
[Upstage AI Lab] 17주차 - CV Generation

들어가며
이번 글에서는 Computer Vision(CV) 분야의 생성(Generation) 기술에 대해 다룬다.
주요 개념과 최신 모델, 그리고 실제 적용 사례를 학습하며 정리했다.
Generative Model
1. Generative Model (생성 모델) 이란?
Generative Model은 주어진 데이터로부터 새로운 데이터를 생성해내는 모델을 의미한다.
이미지, 텍스트, 영상, 소리 등 다양한 형태의 데이터를 만들어내는 데 활용되고 있으며
최근 딥러닝 분야에서 활발히 연구되고 있다.
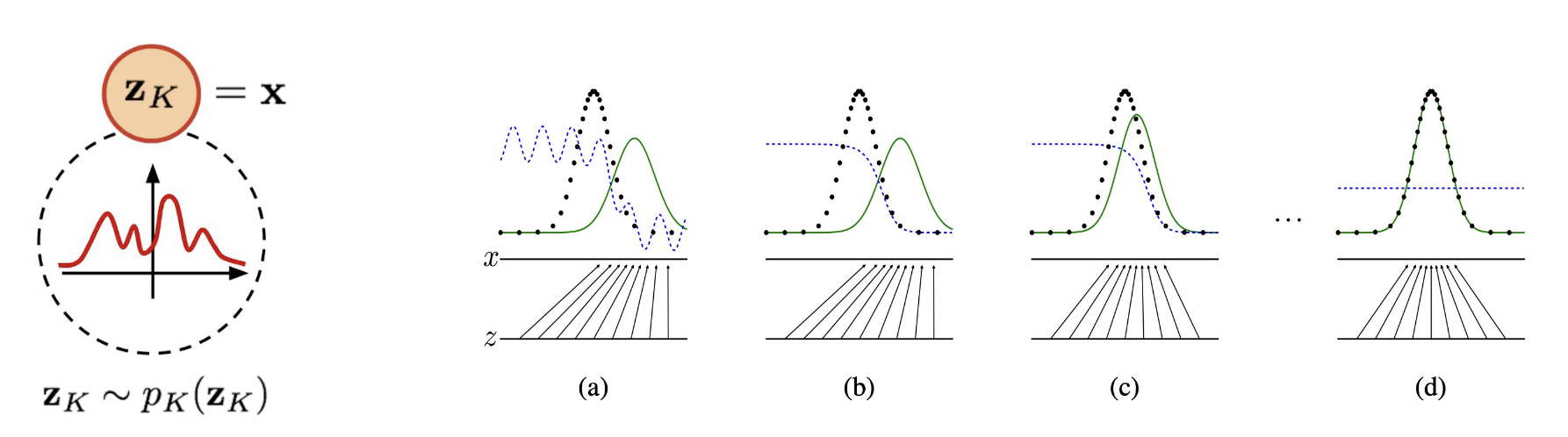
- 데이터는 저차원의 필수적인 정보로부터 생성 가능하다는 가정하에 분포를 학습, 새로운 데이터를 생성
- 훈련 데이터의 확률 분포 P(x)를 학습해서 새로운 샘플을 생성하는 것이 목표
- Discriminative Model(판별 모델)과 달리 데이터 자체의 분포를 모델링한다.
생성 모델의 종류
- VAE (Variational AutoEncoder): 인코더-디코더 구조로 잠재 공간에서 샘플링
- GAN (Generative Adversarial Network): 생성자와 판별자의 적대적 학습
- Diffusion Model: 노이즈를 점진적으로 제거하며 데이터 생성
- Flow-based Model: 가역 변환을 통한 정확한 확률 밀도 계산
- Autoregressive Model: 순차적으로 데이터를 생성 (GPT 등)
활용 사례
- 이미지 생성: 얼굴, 풍경, 예술 작품 생성
- 데이터 증강: 부족한 훈련 데이터 보완
- 스타일 변환: 이미지의 스타일이나 도메인 변경
- 초해상도: 저해상도 이미지를 고해상도로 변환
- 인페인팅: 이미지의 일부분 복원이나 편집
2. Discriminative Model (판별 모델) 이란?
Discriminative Model이란 주어진 입력 데이터에 대해 특정 클래스나 라벨을 예측하는 모델이다.
데이터 자체를 생성하는 것이 아니라 입력과 출력 간의 관계를 학습하여 분류나 회귀 작업을 수행한다.
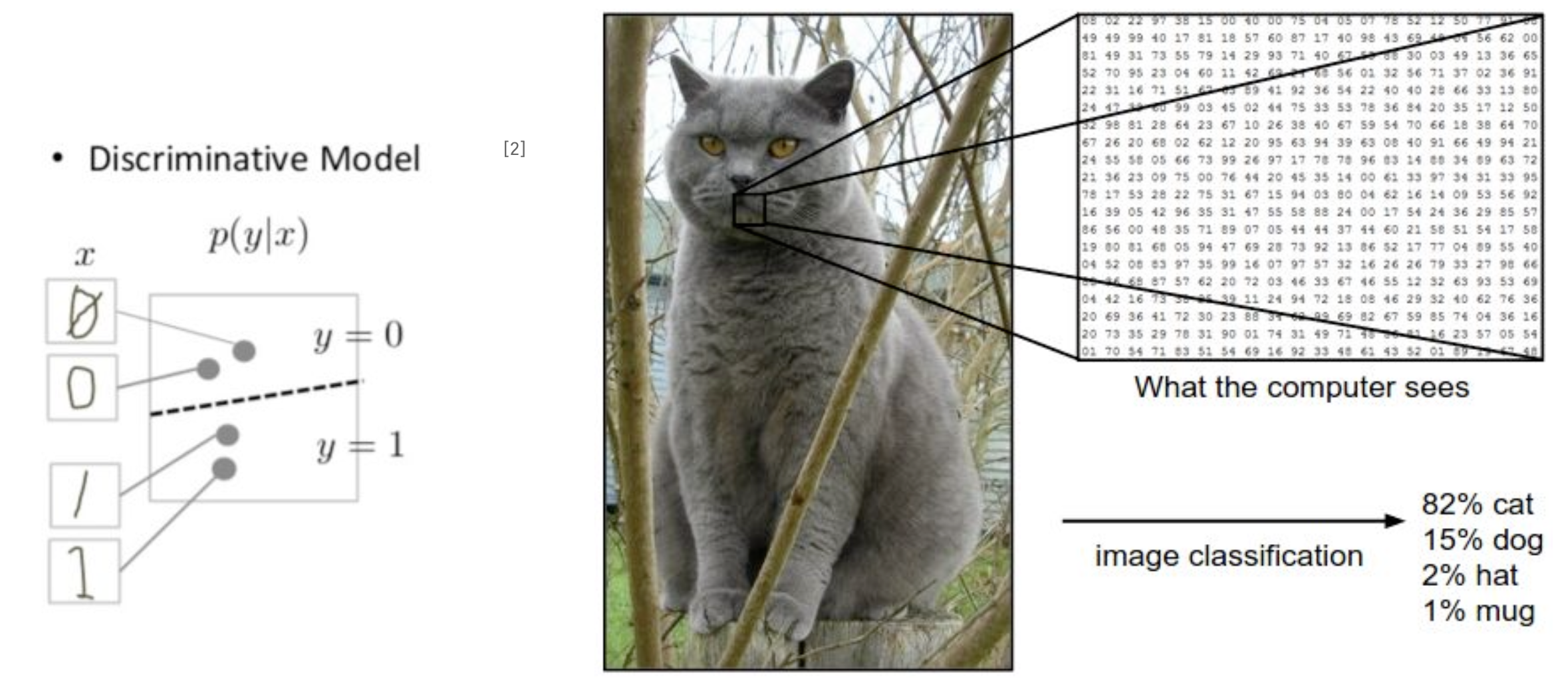
- 조건부 확률 P(Y/X)를 학습하며, 대부분의 지도학습 모델이 이에 해당
- 데이터 X가 주어졌을 때, 특성 Y가 나타날 조건부 확률 P(Y/X)를 직접적으로 반환하는 모델
- 주어진 데이터를 통해 데이터 사이의 경계를 예측
- Generative 와 Discriminative 차이점
- Generative Model: P(x) 또는 P(x,y)를 학습 → 데이터 생성에 초점
- Discriminative Model: P(y/x)를 학습 → 입력에 대한 정확한 예측에 초점
활용 사례
- 어떤 데이터를 서로 다른 클래스로 분류해주는 문제에 활용될 수 있음
- 정상 데이터에 대한 경계를 최대한 좁혀 이를 벗어나는 이상치를 감지하는 문제에도 활용 가능

3. Evaluation Metrics
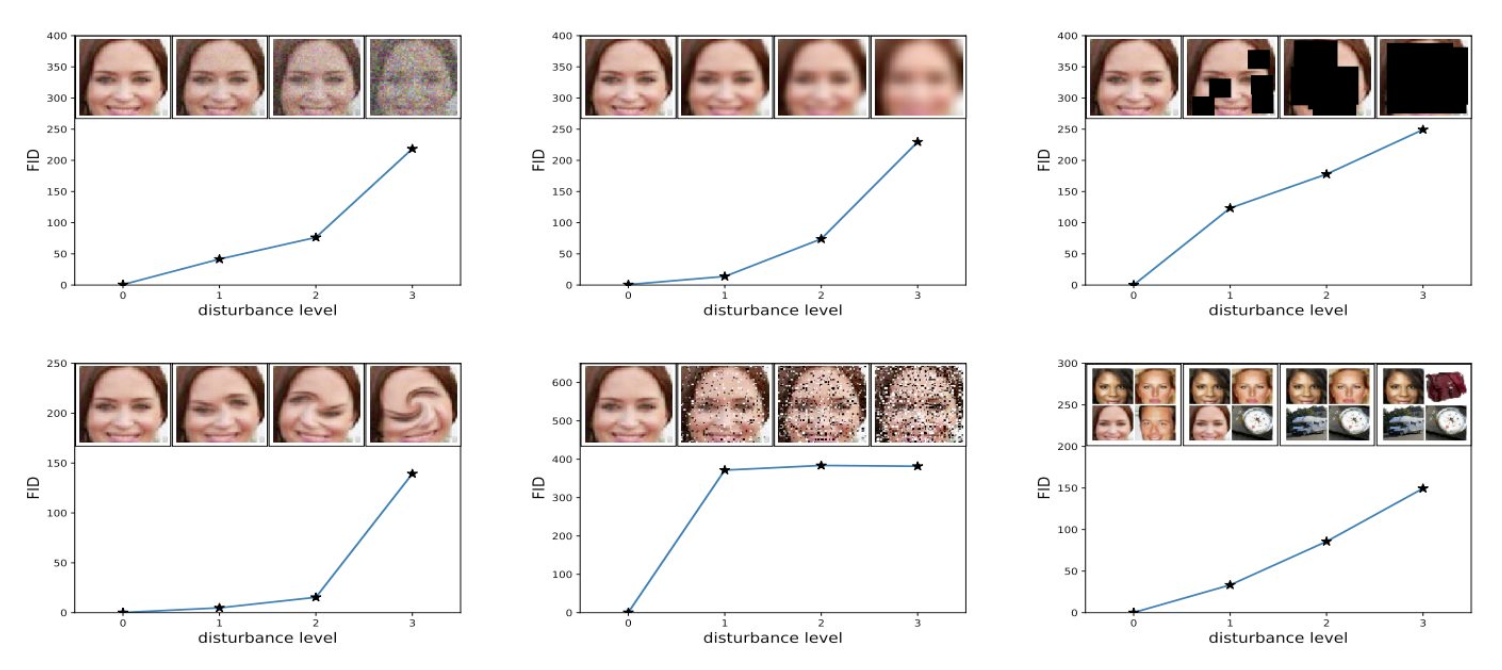
Generative Model의 성능을 평가하는 것은 정답이 없는 작업이기 때문에 매우 어렵다.
따라서 품질, 다양성, 일관성 등 여러 측면을 고려한 정량적 지표들이 개발되었으며
이를 통해 모델의 성능을 객관적으로 비교할 수 있다.

Generative Model 평가의 어려움
- 판별 모델과 달리 비교할 정답이 존재하지 않아 결과를 직접적으로 비교할 대상이 없음
- 훈련 데이터를 정답으로 사용할 경우, 훈련 데이터를 그대로 복제하는 현상 발생
- 생성된 결과에 대해 사람의 주관이 들어갈 수 있음
- 전문성이 요구되는 분야 (의료 등)에는 적용하기 어려움
- 생성 모델을 평가할 때, 고려해야할 점은 아래 두가지가 있다.
- Fidelity (충실도): 이미지의 품질
- Diversity (다양성): 이미지의 다양성
주요 정량적 평가지표
- Inception Score (IS): Inception v3 모델을 분류기로 이용하여 GAN을 평가하기 위해 고안된 지표
- Fréchet Inception Distance (FID): 생성 이미지와 실제 이미지의 분포 차이를 수치로 비교하는 대표적 지표
- Precision & Recall: 생성 이미지의 품질(Precision)과 다양성(Recall)을 동시에 평가하는 지표
- Perceptual Path Length (PPL): 생성 모델의 잠재 공간이 얼마나 부드럽게 이미지를 변화시키는지 측정하는 지표
Inception Score (IS)

- Inception v3 모델을 분류기로 이용하여 GAN을 평가하기 위해 고안된 지표
- 예리함 (Sharpness) 과 다양성 (Diversity) 두 가지를 주요하게 고려
- Sharpness: 특정 숫자 (9)를 생성했을 때, 숫자 분류기가 제대로 인식한다면 좋은 예리함을 가짐
- Diversity: 좋은 품질의 데이터를 생성하는 것만큼 다양한 데이터를 생성하는 것도 중요
- 단순하지만 사람이 내리는 판단 기준과 상관 계수가 높음
- Inception Score 한계
- 분류기 모델의 훈련 데이터 셋과 다른 데이터를 생성하는 경우 제대로 평가하기 어려움
- ImageNet으로 사전 훈련된 모델을 활용하며, Class구분이 이에 속하지 않으면 평가 진행이 불가능
- IS가 높은 데이터를 생성하면 계속 같은 데이터를 생성 (Mode Collapse)
- 오로지 생성된 데이터만을 이용하여 계산
- 기울기 기반 (Gradient Based) 공격, 리플레이 공격을 통해 점수 조작 가능
Fréchet Inception Distance (FID)
- FID는 생성된 데이터의 특징 벡터를 이용하여 훈련 데이터와의 거리를 계산
- IS와 마찬가지로 Inception v3를 활용하지만, 분류기를 활용하지 않고 특징 추출기로만 사용
- 훈련 데이터와 생성 데이터 모두를 사용
- 훈련 데이터와 생성 데이터의 각 분포를 정규 분포로 가정하고, 두 분포의 거리를 Fréchet (프레셰) 거리로 계산
- Fréchet Inception Distance (FID) 한계
- FID 점수는 Fidelity와 Diversity를 각각 평가할 수 없음
- Fidelity가 강조된 모델인지, Diversity가 강조된 모델인지, 균형 잡힌 모델인지 알 수 없음
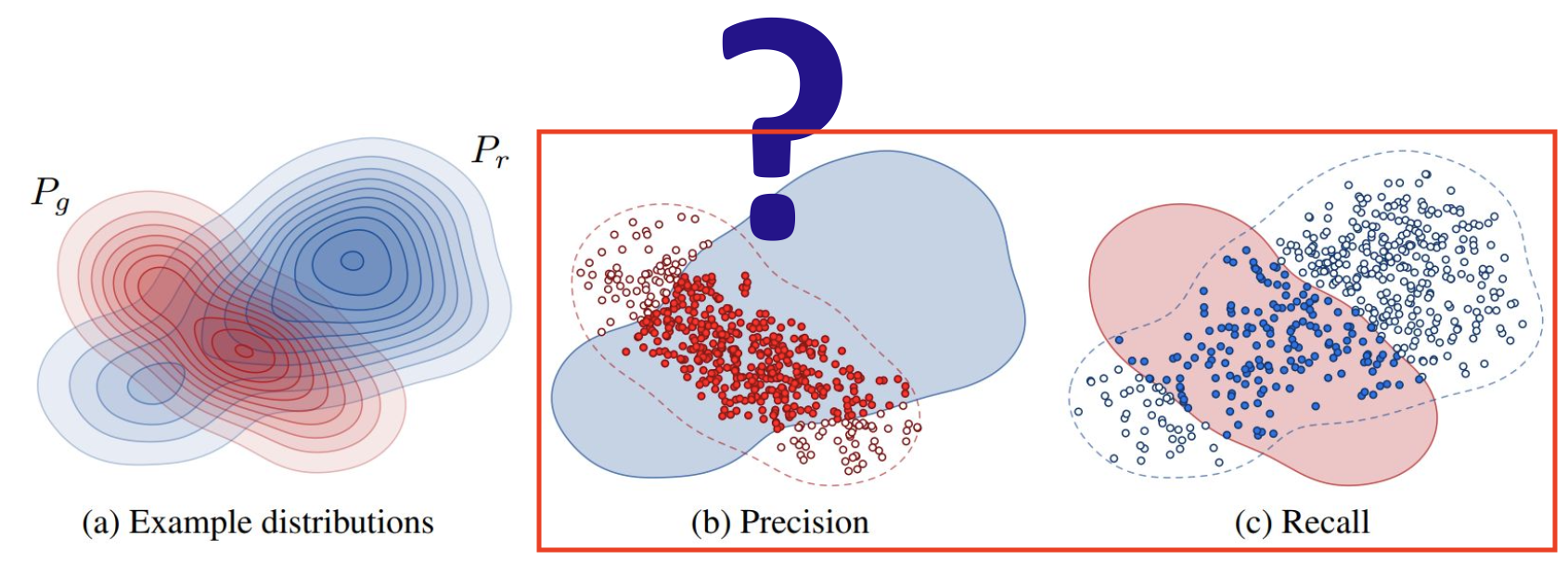
Precision & Recall
- 판별 모델에서 Precision & Recall은 Confusion Matrix(혼동 행렬)를 기반으로 계산
- Precision: 모델이 양성이라고 예측했을 때, 실제로도 양성 (TP) / (TP+FP)
- Recall: 실제로 양성일 때, 모델도 양성 (TP) / (TP+FN)
 Confusion Matrix 예시
Confusion Matrix 예시
- 하지만 생성 모델에서의 Precision & Recall은 약간 다르다.
- Precision: 생성된 데이터 중에서, 실제 데이터 분포에 아주 가까운 데이터의 비율 (생성 데이터의 품질)
- Recall: 실제 데이터 중에서, 생성된 데이터 분포에 아주 가까운 데이터의 비율 (생성 데이터의 다양성)
- 이 개념을 좀 더 명확하게 수식으로 표현한 것이 Improved Precision & Recall이다.
- Improved Precision: 실제 데이터 분포 내의 생성된 데이터 / 생성된 데이터
- Improved Recall : 생성된 데이터 분포 내의 실제 데이터 / 실제 데이터
- Improved Precision & Recall 한계
- 이상치에 민감하며, 일부 데이터만 임베딩 위치가 변해도 값이 크게 변함 -> 평가 지표로서 불안정
- 실제 데이터와 생성된 데이터의 분포가 동일하더라도 샘플링에 따라 점수가 낮을 수 있음
- 계산량이 많음
Autoencoder
1. Autoencoder 이란?
Autoencoder (오토인코더)는 입력 데이터를 압축하여 잠재 공간(Latent Space)으로 표현한 후
다시 원본 데이터로 복원하는 것을 목표로 하는 비지도 학습 신경망이다.
주로 차원 축소, 특징 추출, 노이즈 제거 등에 활용된다.
전체 실습 코드는 GitHub에서 확인할 수 있다.
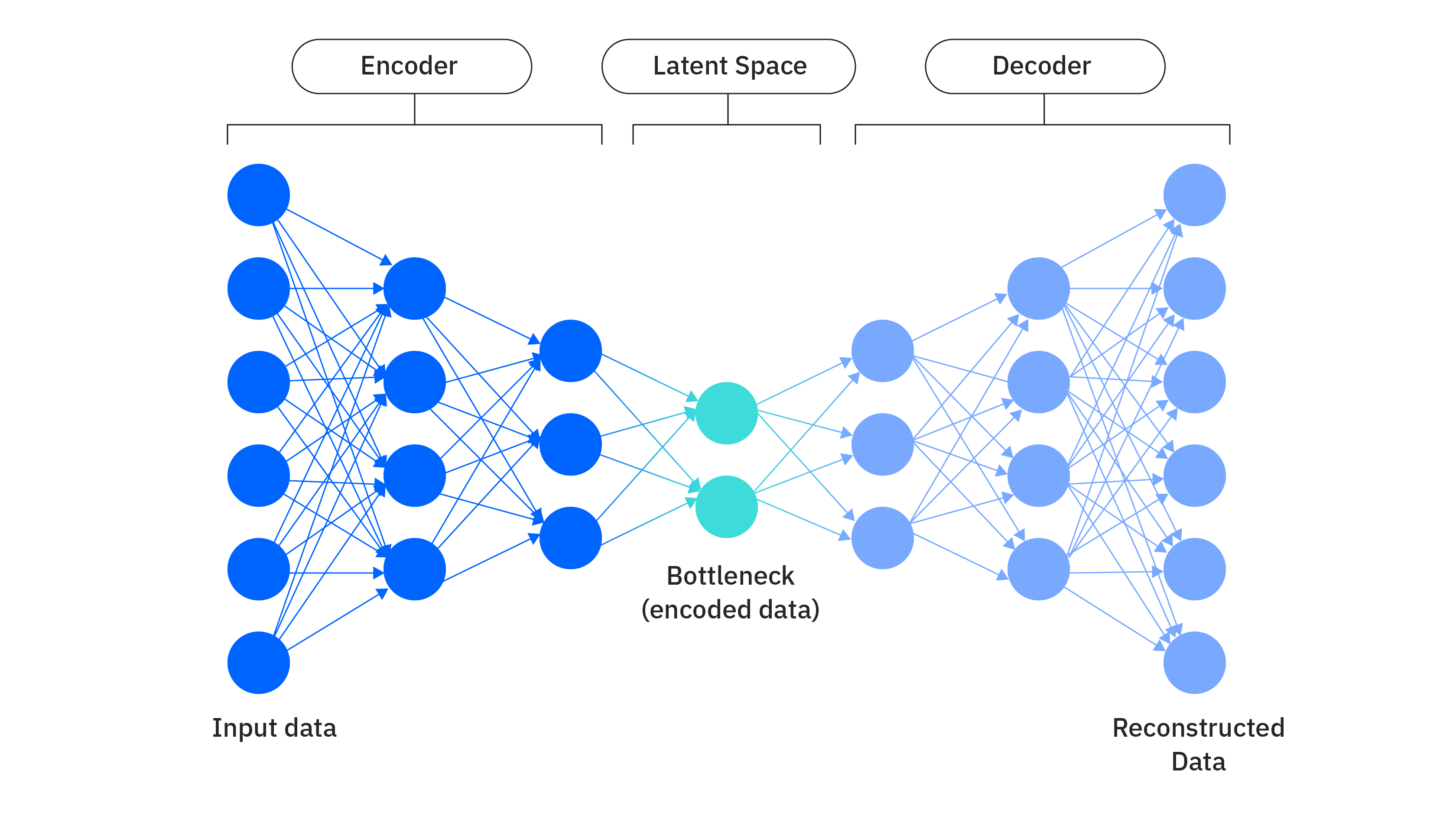
- Encoder (인코더): 입력 데이터를 받아 잠재 공간의 압축된 표현(Latent Representation)으로 변환
- Decoder (디코더): 잠재 공간의 표현을 받아 원본 데이터와 유사하게 복원
- loss Function (손실 함수): 잠재 표현으로부터 복구한 데이터와 입력 데이터의 평균제곱오차(MSE)
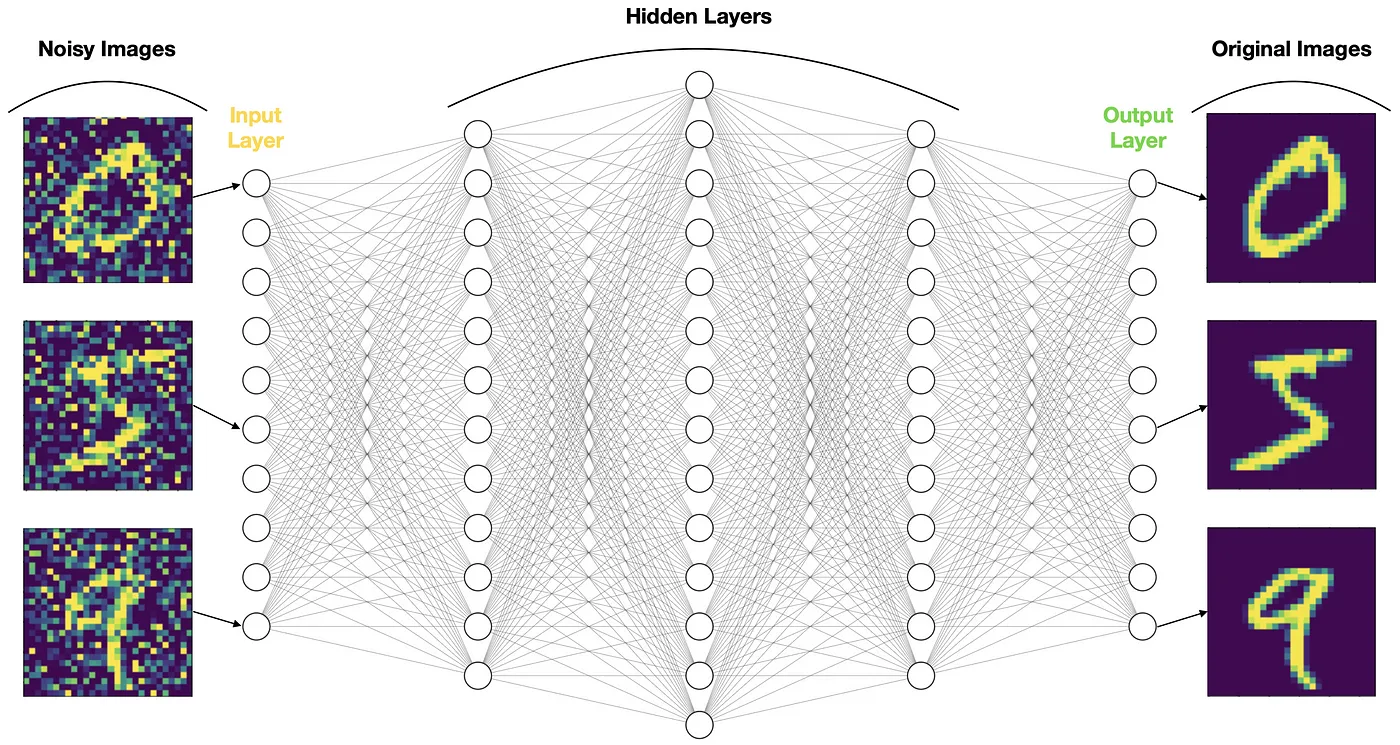
Denoising Autoencoder (디노이징 오토인코더)
- 입력 데이터에 랜덤 노이즈를 주입하거나 Dropout layer를 적용
- 노이즈가 없는 원래 데이터로 재구성
- 노이즈에 강건한 잠재 표현 (미세하게 변형된 데이터도 같은 잠재 벡터로 표현되도록)
2. Variational Autoencoder (VAE) 이란?
VAE (변분 오토인코더)는 오토인코더의 개념을 확장하여 생성 능력을 강화한 모델이다.
잠재 공간을 확률 분포로 모델링하여 새로운 데이터를 생성할 수 있게 한다.
전체 실습 코드는 GitHub에서 확인할 수 있다.
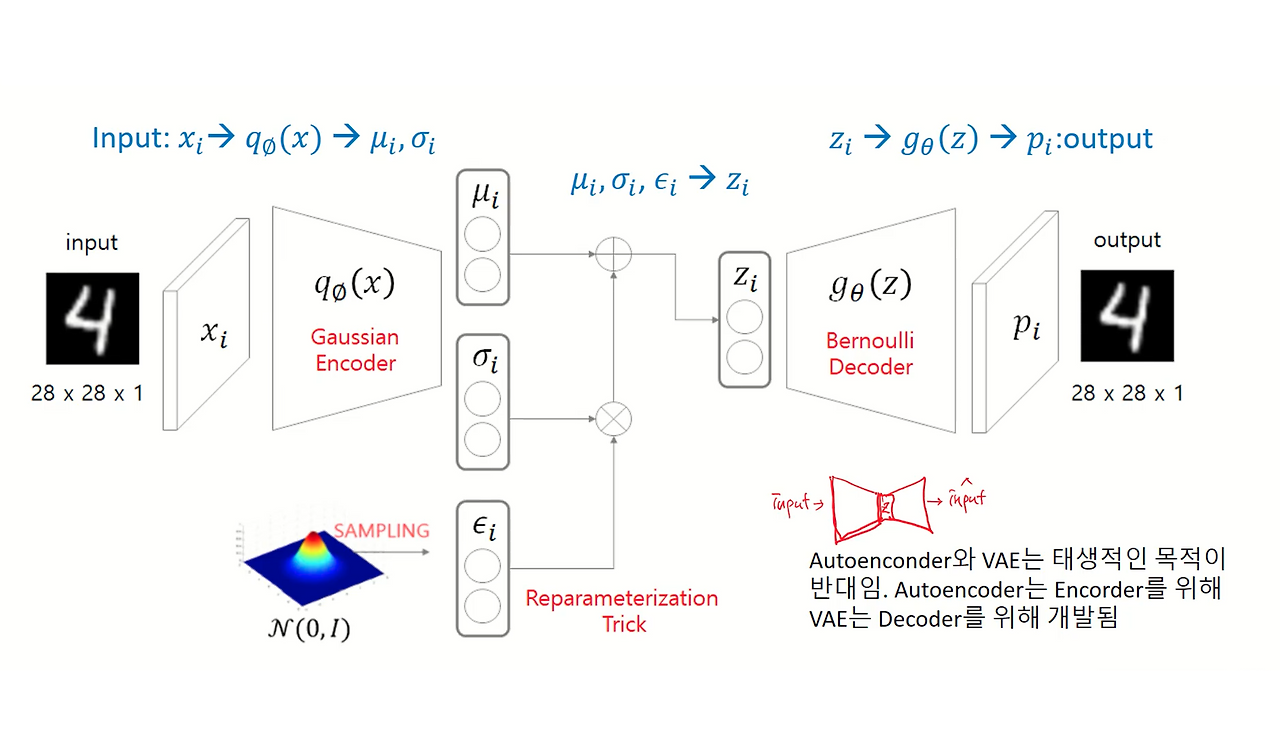
- Autoencoder와 동일한 구조를 가지는 생성 모델
- 데이터는 저차원의 잠재 변수로부터 생성됨
- 잠재 벡터의 분포: 표준정규분포
- 잠재 변수(z)가 표준정규분포를 따른다고 가정 (사전 분포 → p(z))
- 조건부 분포
p(x|z)(=확률적 디코더)는 일반적으로 정규분포 또는 베르누이 분포로 모델링 - 새로운 데이터를 생성할 수 있음
- 경우에 따라 흐릿한 영상이 생성되는 경향이 있음
Generative Adversarial Networks (GANs)
1. GANs 이란?
GANs (적대적 생성 신경망)은 생성자 (Generative)와 판별자 (Discriminator)라는
두 개의 신경망이 서로 경쟁하며 학습하는 구조를 통해 새로운 데이터를 생성하는 모델이다.
특히 사실적인 이미지 생성 분야에서 혁혁한 성과를 보였다.
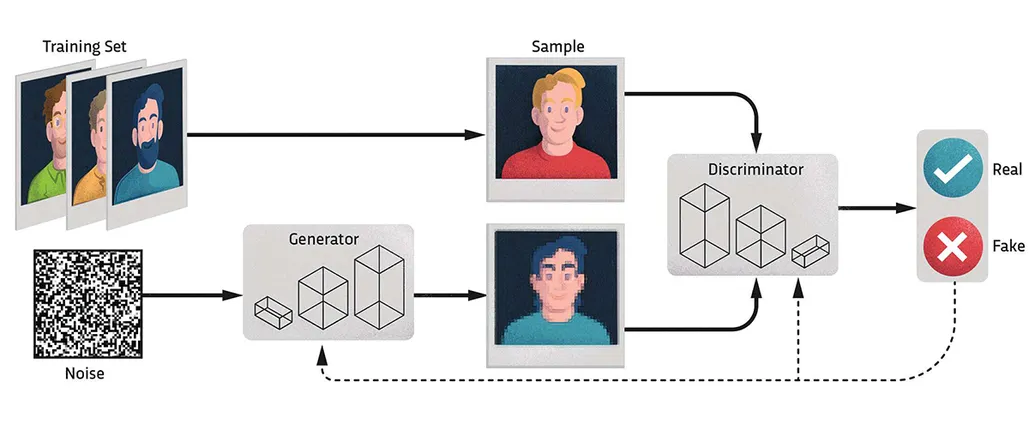
- 데이터를 생성하는 생성 모델 (Generator)과 데이터의 진위를 구별하는 판별 모델 (Discriminator)로 구성
- Generator (생성자): 임의의 노이즈를 입력으로 받아 가짜 데이터를 생성
- Discriminator (판별자): 생성된 데이터를 입력으로 받아 실제 데이터인지 생성된 데이터인지를 출력
- GANs는 생성 모델의 분포와 판별 모델의 예측을 지속적으로 갱신하면서 학습됨
- 두 모델이 서로 적대적인 방향으로 학습
- 생성 모델은 판별 모델의 출력값을 최소화
- 판별 모델은 출력값을 최대화
2. Conditional GAN (조건부 생성 모델) 이란?
Conditional GAN (조건부 생성 모델)은 기존 GAN에 조건 정보(Condition)를 추가하여
특정 조건에 맞는 데이터를 생성할 수 있도록 확장한 모델이다.
예를 들어, 특정 클래스의 이미지나 텍스트 설명에 맞는 이미지를 생성하는 데 활용된다.
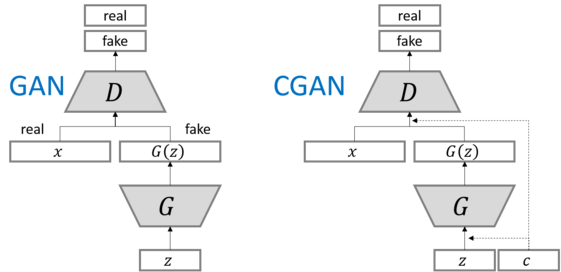
- 임의의 잠재 벡터 + 조건 정보를 추가해 데이터를 생성
- 생성 모델에 입력되는 잠재 벡터와, 판별 모델에 입력되는 조건부 벡터가 추가된 형태
- 판별 모델이 입력받은 데이터가 실제 데이터와 유사하더라도 입력된 조건을 만족하지 않으면 0을 출력
- 높은 다양성과 품질을 동시에 누릴 수 있으나 수집하기 더 까다로운 데이터를 필요로함
3. Diffusion Probabilistic Model (확산 확률 모델) 이란?
Diffusion Probabilistic Model, DPM은 최근 이미지 생성 분야에서 가장 주목받는 모델 중 하나로
정방향으로 노이즈를 점진적으로 추가하고, 역방향으로 이를 제거하며 데이터를 생성한다.
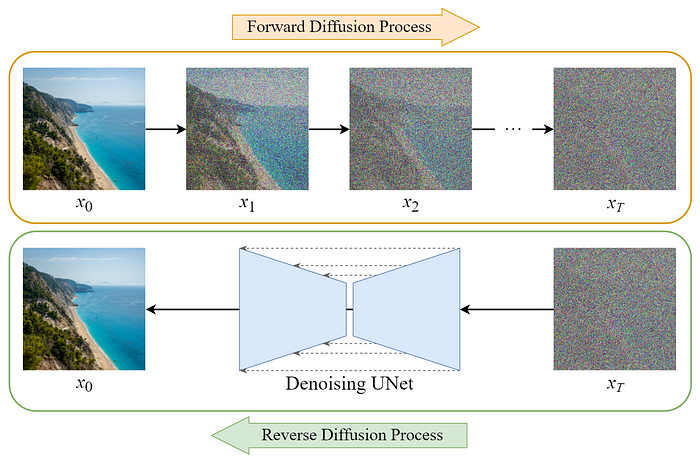
- 정방향 (Forward Diffusion Process): 원본 이미지에 노이즈를 추가하여 이미지를 완전히 노이즈로 만듬
- 역방향 (Reverse Diffusion Process): 노이즈가 포함된 이미지에서 노이즈를 제거하여 원본 이미지를 복원
- 학습 목표: 역방향 과정에서 각 시간 단계별로 추가된 노이즈를 정확하게 예측하도록 신경망을 학습시킨다.
- VAE와 차이점
- 잠재 변수의 차원이 모든 데이터의 차원과 동일 + 여러 단계의 잠재 변수를 가짐
- Decoder를 모든 시점에서 공유 + Encoder는 학습되지 않음
4. Denoising Diffusion Probabilistic Model (디노이징 확산 확률) 이란?
DDPM (Denoising Diffusion Probabilistic Model)은 기존 확산 모델의 역방향 과정을 단순화하여
원본 이미지를 복원하는 대신, 추가된 노이즈 자체를 예측하도록 학습하는 모델이다.
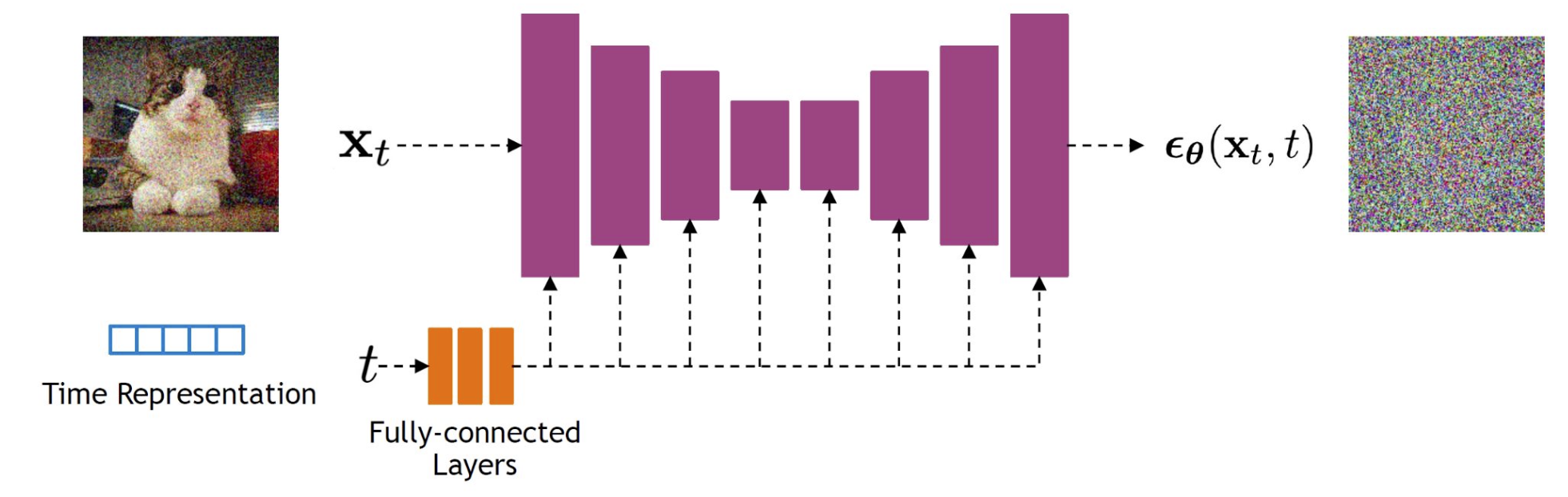
- 학습 목표: 역방향에서 원본 이미지를 복원하는 대신, 각 단계에서 추가된 노이즈를 예측하는 것을 목표로 한다.
- U-Net 구조: 노이즈 예측을 위해 U-Net 구조를 활용, 입력된 노이즈 이미지와 동일한 크기의 노이즈 맵을 출력
- 장점: 고품질의 다양한 이미지를 생성하는 데 매우 효과적이며, 학습이 안정적이다.
- 단점: 여러 단계에 걸쳐 반복적으로 노이즈를 제거해야 하므로 샘플링 속도가 느리다는 단점이 있다.
DDPM 한계점
- 느린 생성 과정: 5만개의 32x32 크기 이미지 생성 위해 20시간 필요
- 조건부 생성 불가: DDPM은 조건 없는 모델이며, 품질-다양성 조절이 불가하다.
5. Latent Diffusion Model (잠재 확산 모델) 이란?
LDM (Latent Diffusion Model)은 기존 확산 모델의 계산 비효율성을 해결하기 위해,
고차원의 픽셀 공간 대신 압축된 잠재 공간(Latent Space)에서 확산 과정을 수행하는 모델이다.
대표적인 예로 Stable Diffusion이 있다.
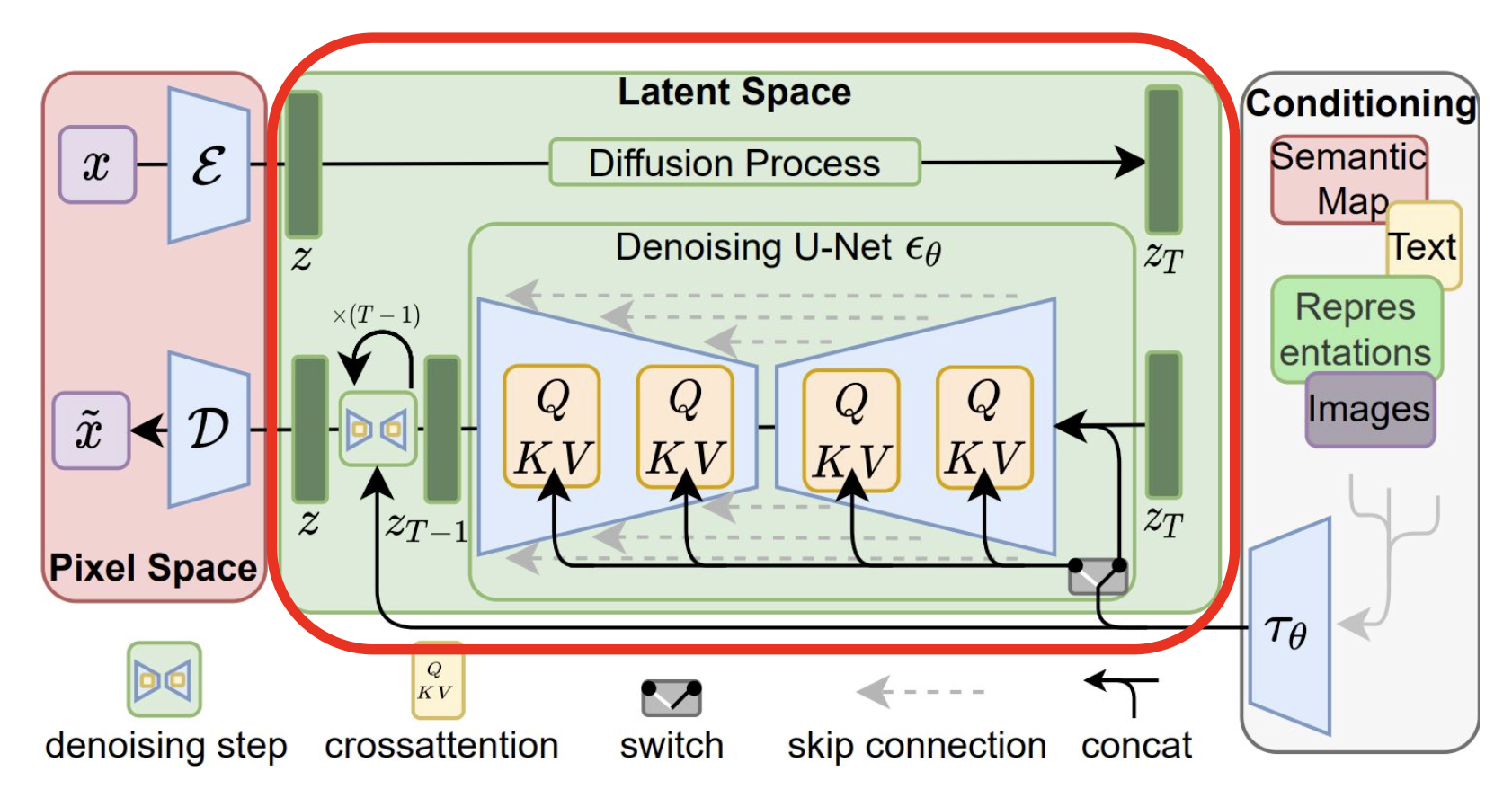
- 작동 원리:
- Autoencoder (VAE)를 사용해 원본 이미지를 저차원의 잠재 공간으로 압축 (Encoder)
- 이 잠재 공간에서 DDPM과 동일한 확산 및 디노이징 과정을 수행
- 디노이징이 완료된 잠재 벡터를 다시 원본 이미지 공간으로 복원 (Decoder)
- 장점:
- 효율성: 고차원 픽셀이 아닌 저차원 잠재 공간에서 연산하므로 학습 및 추론 속도가 매우 빠르다.
- 고품질 생성: 강력한 디코더를 통해 고해상도의 이미지를 생성할 수 있다.
- 조건부 생성 용이: Cross-Attention 메커니즘을 통해 텍스트 등 다양한 조건에 맞는 이미지 생성이 가능하다.
- 한계:
- Autoencoder의 성능에 따라 최종 이미지 품질이 좌우될 수 있다.
- 압축 과정에서 일부 세부 정보가 손실될 수 있다.