[Upstage AI Lab] 16주차 - CV 경진대회
[Upstage AI Lab] 16주차 - CV 경진대회 회고
Document Type Classification
Upstage AI Lab 의 CV 경진대회에 대한 주요 내용과 회고록 내용
1. 개요
Document Type Classification 경진대회는 문서 타입 분류를 위한 이미지 분류 대회다.
Project Overview
- Project Duration: 2025.06.30 ~ 2025.07.10
- Team: 3명
- Submission: 3,140장에 대한 예상 문서 유형 분류
- Class: 17
- Evaluation Metric: F1 Score macro
2. 주요 역할
본 대회는 팀 프로젝트로 진행되었으며, 이 글에서는 내가 맡았던 주요 작업과 전략적 접근에 대해 기술한다. 이번 경진대회에선 팀장을 맡았다.
- EDA
- 문서 유형별 이미지 특성 분석 및 분포 확인
- Class Imbalance 여부 확인
- Class 별 Image size 분석
- Train/Test 데이터 차이점 분석
 Class Imbalance class
Class Imbalance class
- Data PreProcessing
- Albumentations, augraphy 등을 사용해서 데이터 증강 (오프라인 증강)
- 이미지 회전, 잘림, 밝기/대비, 노이즈, 잉크 번짐, 그림자 등 다양한 방법으로 증강
- mixup/cutmix 등의 코드를 팀원들에게 공유
- 데이터 증강 시 Class Imbalance를 고려하여, 모든 클래스의 데이터 수를 동일하게 조정
 Data Augmentation
Data Augmentation
- 실험 및 기록
- WandB(Weights & Biases)를 도입하여 모든 실험을 체계적으로 기록 및 관리
- 하이퍼파라미터, 학습 곡선, 등을 실시간으로 모니터링하여 효율적인 실험 진행
- 팀원들에게 WandB 사용 가이드를 직접 작성 및 공유하여 협업 효율성 증대
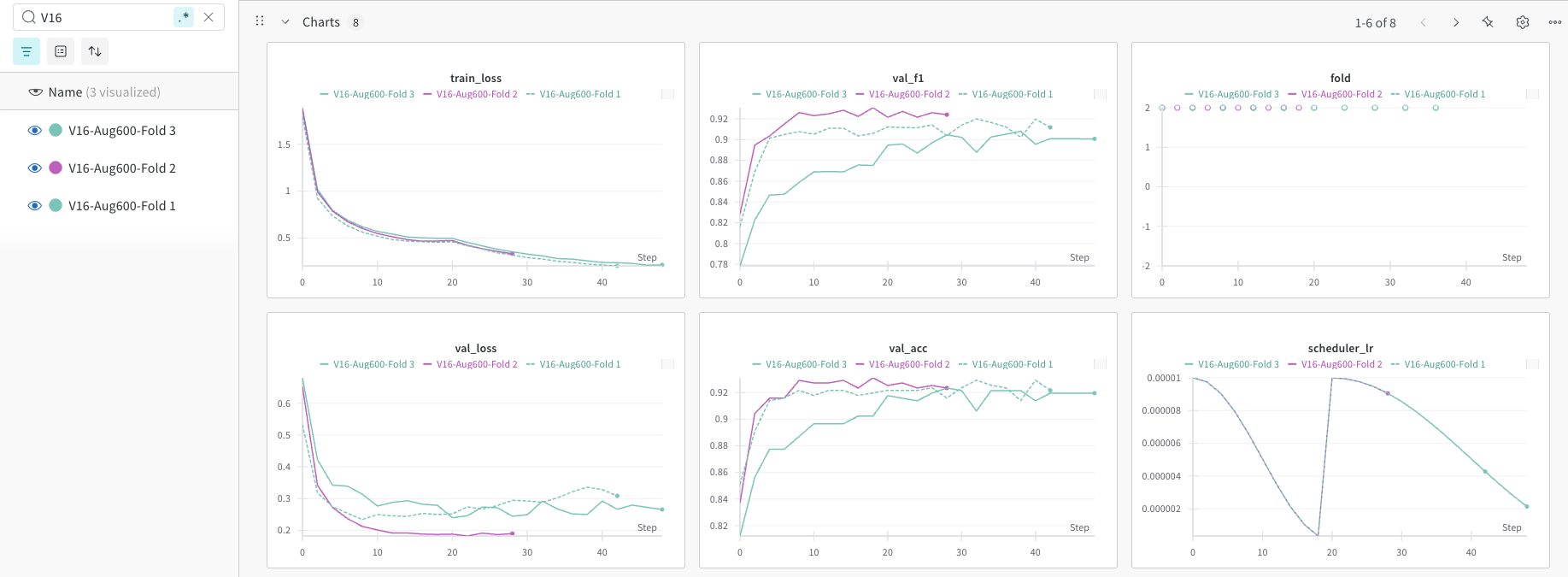 WandB
WandB
- Modeling
- 본 프로젝트에서는 EfficientNet, Convnext 계열 모델을 주로 사용
- K-Fold를 사용하여 모델 학습 (fold=3)
- Model Architecture
- EfficientNetV2-L: 대용량 모델로 성능 개선
- EfficientNetV2-XL: 최고 성능을 위한 초대형 모델
- ConvNeXt-Base: 기본 ConvNeXt 모델로 균형잡힌 성능
- ConvNeXt-XLarge: 대용량 ConvNeXt 모델로 높은 성능
- ConvNeXtV2-Large: 개선된 ConvNeXt 아키텍처의 대용량 모델
- 최종 제출 전략
- K-Fold 교차 검증으로 학습한 각 Fold의 모델들을 활용한 Soft Voting 앙상블을 적용
- TTA(Test-Time Augmentation)를 병행하여 예측 안정성 극대화
3. DataSet
경진대회에서 제공된 Dataset는 다음과 같았다.
- Train
- 총 1,570장
- Class: 17개
train.csv파일에 ID와 클래스 라벨(target)이 포함meta.csv파일에는 클래스 번호(target)와 클래스 이름(class_name) 정보가 담겨 있음
- Test
- 총 3,140장
sample_submission.csv파일에 ID가 포함되어 있으며, 예측 결과를 제출할 때 사용- Test 데이터는 회전, 반전 등 다양한 변형과 훼손이 포함되어 있어, 실제 환경과 유사한 조건을 반영
4. 최종 결과
최종적으로 10개 팀 중 9위로 대회를 마무리했다.
순위는 아쉽지만, 다양한 모델과 증강 기법을 실험하는 과정에서 많은 것을 배울 수 있었다고 생각한다.
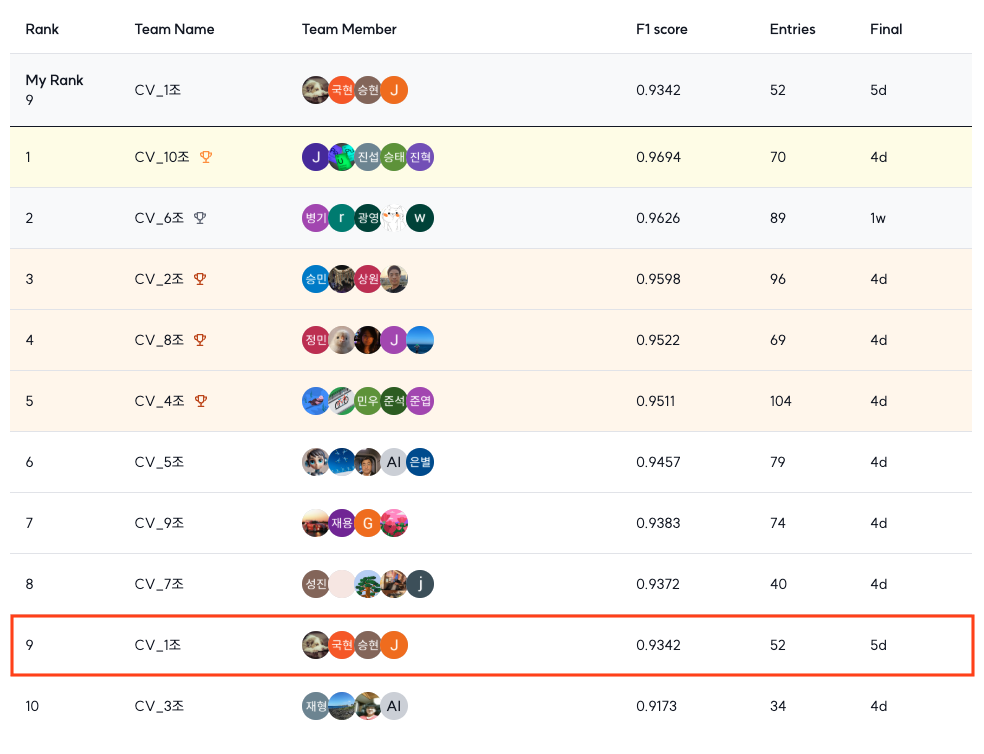
- Public Score: 0.9418
- Private Score: 0.9342
회고
이 섹션은 Upstage AI Lab CV 경진대회를 통해 경험한 문제와 해결과정에 대한 회고를 담았다.
문제 & 해결 과정
문제
이번에도 역시 대회 초반, Validation Score 는 높게 나왔지만, 실제 제출 점수는 그에 미치지 못하는 현상이 발생했다.
그래서 이 갭 차이를 줄이기 위해 성능이 좋은 대형 모델(L, XL 모델 등) 위주로 실험을 진행하다 보니
한 번의 K-Fold 학습에 너무 많은 시간이 소요되는 문제가 있었다.
해결 과정
학습 시간이 오래걸려 다양한 실험을 막고 있다고 판단했기에 ‘가설 수립 → 빠른 실험 → 검증’ 의 순서를 도입해봤다. 먼저 “데이터 증강을 늘리면 성능이 향상될 것이다” 라는 가설을 세우고, 이를 빠르게 검증하기 위해
XL 모델 대신 ConvNeXt-Base 같은 경량 모델을 선택해서 실험을 진행했다.
Class 별 증강 수를 300개, 400개, 600개, 800개로 늘려가며 실험을 반복한 결과
600개까지는 성능이 유의미하게 향상되지만 그 이상에서는 오히려 성능이 떨어진다는 결과를 얻었다.
이 결과를 토대로 적합한 증강 수와 다양한 증강 기법을 적용해 성능을 끌어올릴 수 있었던 거 같다.
인사이트
아쉬웠던 점
대회 초반에 나는 단순히 최고 성능을 내겠다는 생각으로 무작정 가장 크고 무거운 모델부터 돌렸다.
하지만 한 번 실험할 때마다 반나절 이상씩 걸리는 바람에 다양한 증강 기법이나 하이퍼파라미터 튜닝 같은
시도를 제대로 해볼 시간이 없었다. 시간이 지나고서야 가벼운 모델로 빠르게 실험하는 게 중요한지 깨달았지만
이미 너무 많은 시간을 날려버린 후였기에 다양한 실험과 기법들을 적용하지 못한 부분이 가장 아쉽다.
알게 된 점
모델 성능을 끌어올리는 것만큼이나 ‘빠른 실험과 검증의 반복’이 중요하다는 걸 깨달았다.
가벼운 모델로 아이디어를 빠르게 테스트해서 먼저 효과적인 전략을 찾고, 검증된 전략을 최종 모델에 적용
이게 한정된 시간 안에서 최고의 결과를 내는 핵심이라고 생각한다.
아무리 좋은 모델이라도 제대로 된 전략 없이는 그 성능을 온전히 발휘할 수 없다는 걸 체험했다.