[Upstage AI Lab] 15주차 - CV Advanced
[Upstage AI Lab] 15주차 - Computer Vision 심화 학습

들어가며
이번 포스팅에서는 Computer Vision(CV)의 심화 내용을 다룬다.
Object Detection 과 Semantic Segmentation 같은 분야에서 Transformer 기반의 최신
모델 아키텍처들을 중점적으로 알아보고 이후 발전된 방법론들까지 살펴볼 예정이다.
Transformer
1. Transformer 란?
Transformer는 2017년 ‘Attention Is All You Need’ 논문에서 제안된 모델로
Attention을 활용하여 데이터 요소 간의 관계를 학습한다. 원래 자연어 처리 분야에서 혁신을 가져왔는데
최근에는 컴퓨터 비전(CV) 분야에서도 Transformer 기반 모델들이 주목받고 있다.
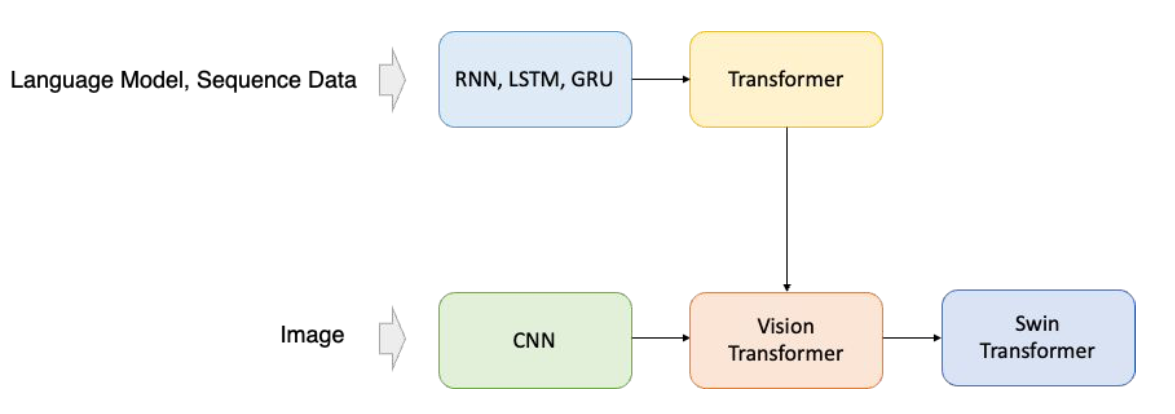
Transformer 등장 배경
- Long-term dependency를 해결하고 Attention을 고려하기 위한 transformer 개발
- Natural Language Processing (NLP)에서 생기는 문제점을 해결하기 위해 고안
- Attention: Next token을 예측할 때, sequence 내의 다른 위치에 있는 정보들과의 상관 관계가 중요
- Long-term dependency
- 기존 모델들은 sequence data를 처리할 때 데이터를 순차적으로 처리
- 데이터 길이가 길어지면 정보 손실이 발생
CNN 한계
- Computer vision 분야에서도 NLP와 같은 문제에 발생
- Long-range dependency: 멀리 떨어진 두 물체에 대한 context를 학습하기 힘듦
- Attention: 이미지 내의 여러 object들에 대한 상관 관계를 알 수가 없음
- Transformer가 기존 NLP의 문제점을 어떻게 해결했는지 분석
- 이후, 동일한 메커니즘을 computer vision에도 적용 (ViT)
2. Transformer 구조
Transformer의 핵심은 Encoder와 Decoder 스택으로 구성된 시퀀스-투-시퀀스 아키텍처에 있다.
각 인코더와 디코더 블록은 Multi-Head Attention과 Feed-Forward Network을 포함하며
입력 데이터의 순서 정보를 반영하기 위한 위치 인코딩(Positional Encoding)을 사용한다.
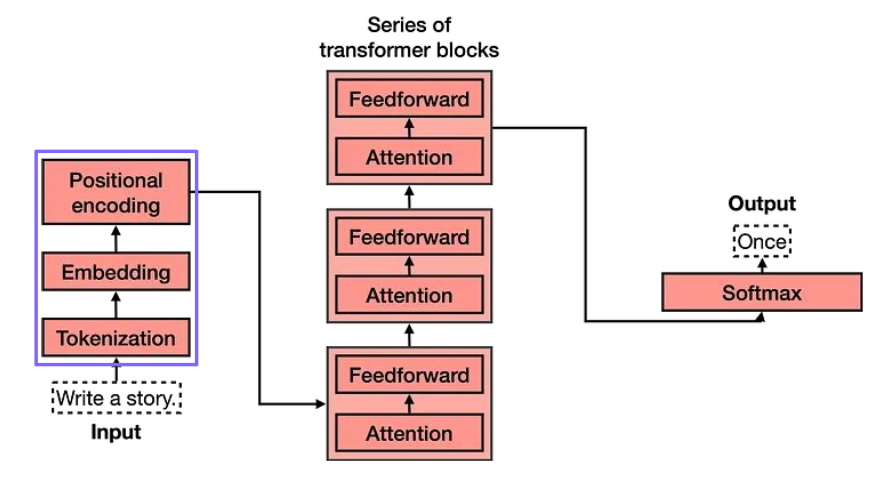
- Sentence to Embedding: 컴퓨터가 처리할 수 있는 벡터 표현(임베딩)으로 변환하는 과정
- Tokenization: 입력 문장을 모델이 처리할 수 있는 더 작은 단위인 token으로 분리하는 과정
- Attention: 시퀀스 내의 모든 위치에 있는 요소들 간의 관련성을 학습하는 메커니즘
- Feed-Forward: 어텐션 레이어에서 추출된 정보를 각 위치별로 독립적으로 비선형 변환하는 부분
3. Vision Transformer
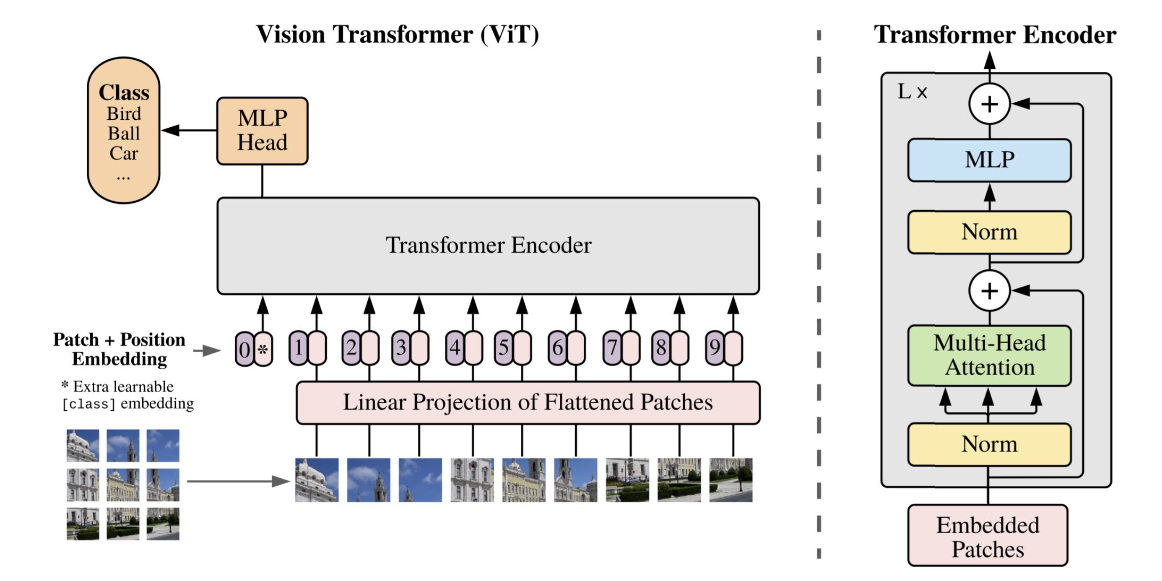
Vision Transformer (ViT)는 기존 Transformer 아키텍처를 이미지 처리에 적용한 모델이다.
이미지를 일정 크기의 패치(patch)로 나눈 뒤, 각 패치를 토큰처럼 임베딩하여 입력으로 사용한다.
이를 통해 NLP 방식으로 이미지를 처리하며, 전역적 정보 학습과 장거리 의존성 처리에 강점을 가진다.
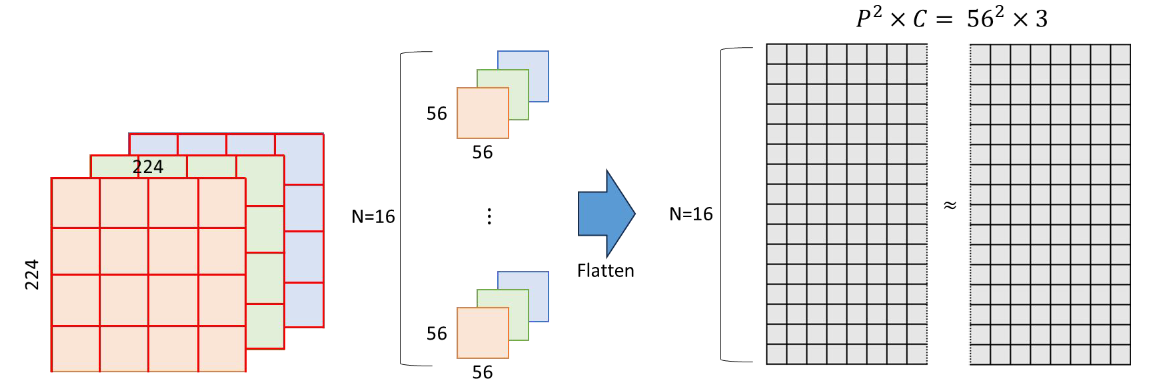
Patching
- (H, W, C) 크기의 이미지를 크기가 (P, P)인 패치 N개로 자름
- N=HW/P² 로 계산되며, 논문에서는 P=14, 16, 32 를 사용
- 이후 각각의 패치를 Flatten
 Patching
Patching
Linear Projection
- Linear projection으로 D 크기의 feature로 변환 (D= 768, 1024, 1280)
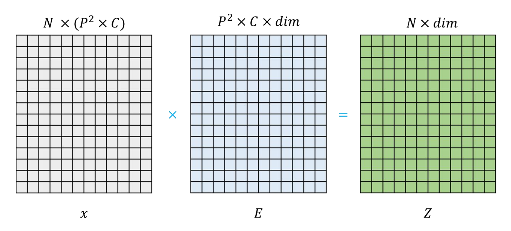 Linear Projection
Linear Projection
CLS Token
- Projection 된 이미지 embedding 앞에 cls token을 하나 추가
- 마찬가지로 학습 가능한 embedding
- 추후 이미지 전체에 대한 representation을 나타냄
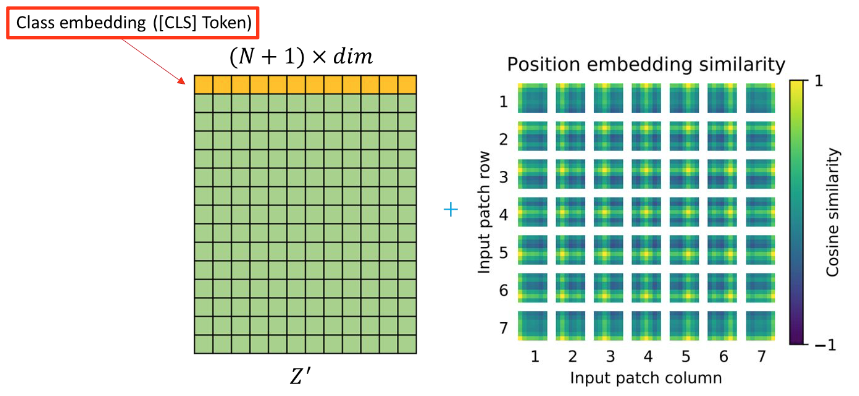 CLS Token
CLS Token
Positional Embedding
- Flatten된 이미지가 위치 정보를 가질 수 있도록 위치 정보 추가
- Positional encoding or positional embedding
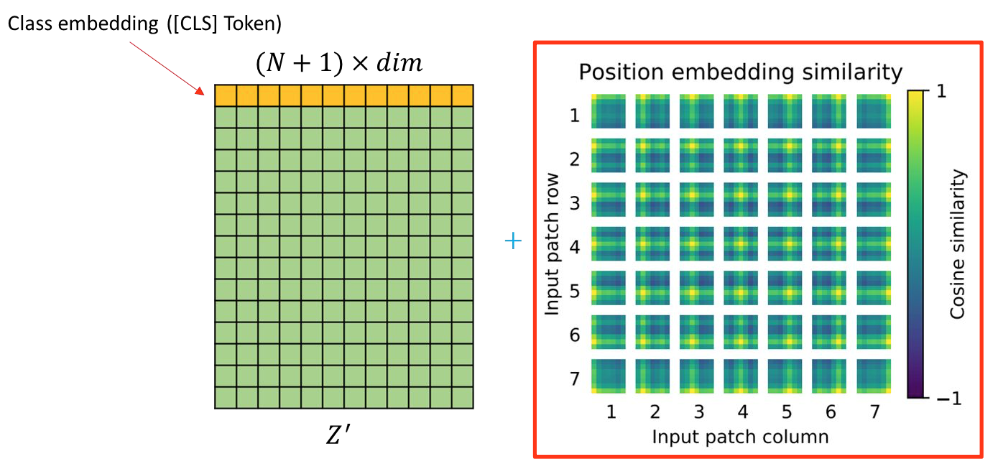 Positional Embedding
Positional Embedding
Transformer Encoder
- 기존 Transformer와 동일한 방식으로 encoding
- Transformer와 동일한 방식으로 self-attention 계산 및 multi-head 적용
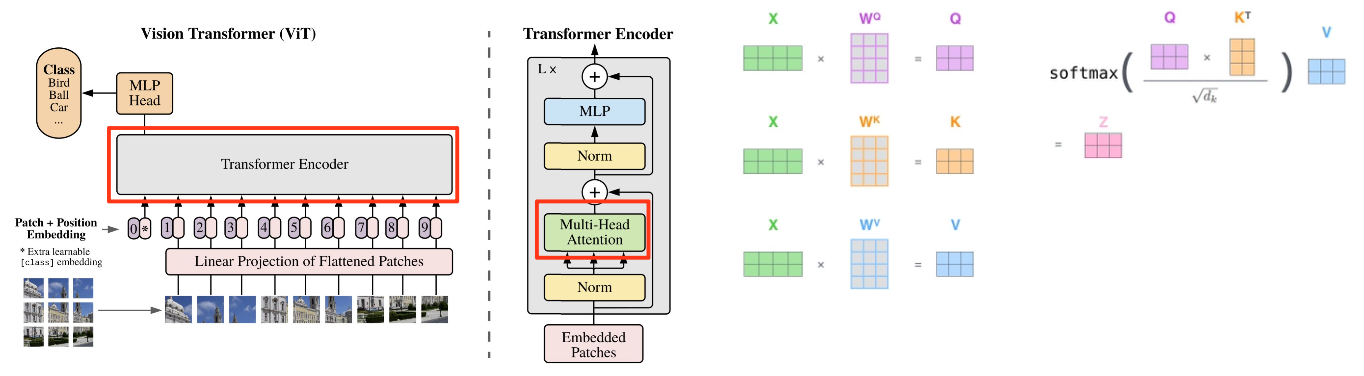 Transformer Encoder
Transformer Encoder
MLP Head
- 2개의 hidden layer와 GELU activation function으로 구성
- CLS 토큰에 대해 classification head 적용
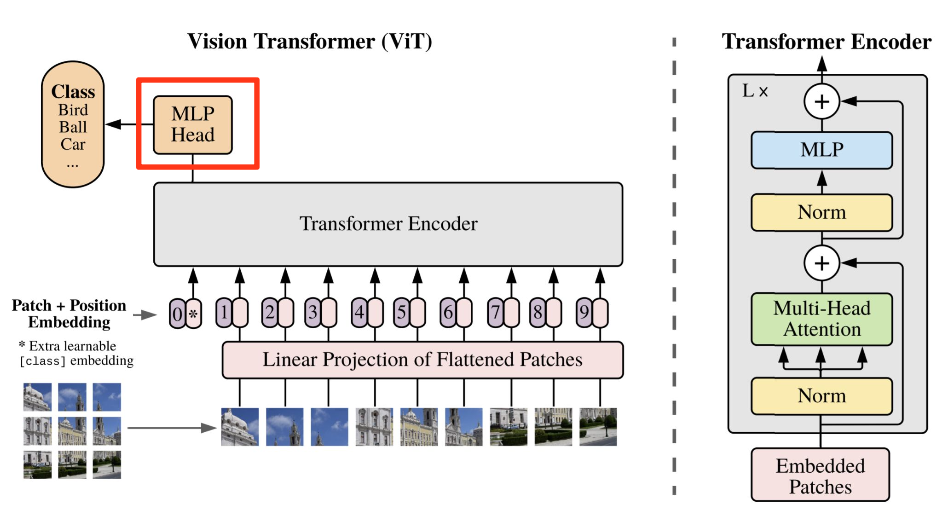 MLP Head
MLP Head
Recap
- 위 순서들을 짤로 보면 이런식이다.
- 즉, 전체 파이프라인은 아래와 같다.
- 이미지를 패치로 분할 후 Flatten
- 선형 변환으로 임베딩
- CLS 토큰 추가
- 위치 정보 부여
- Transformer 인코딩
- MLP로 분류
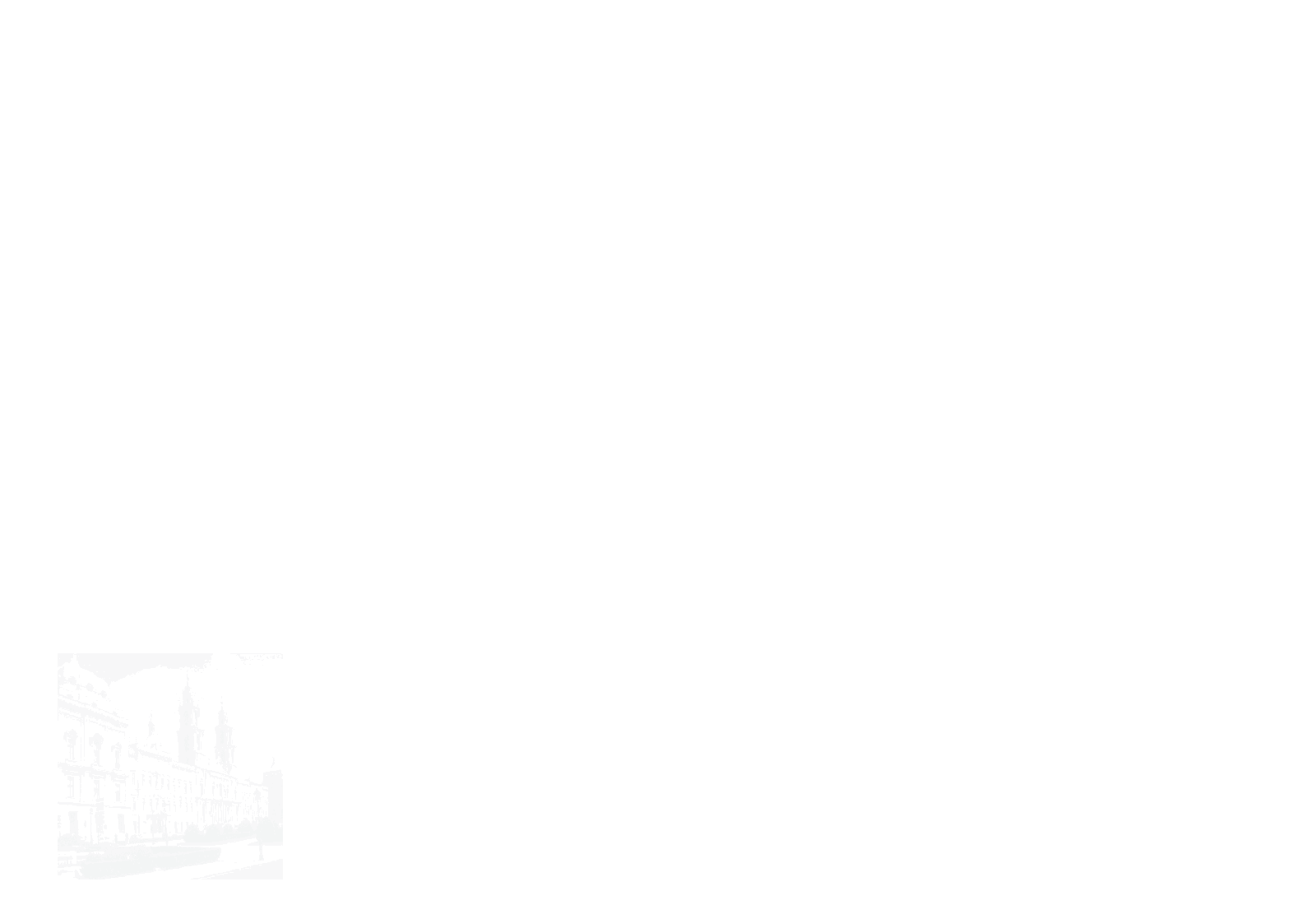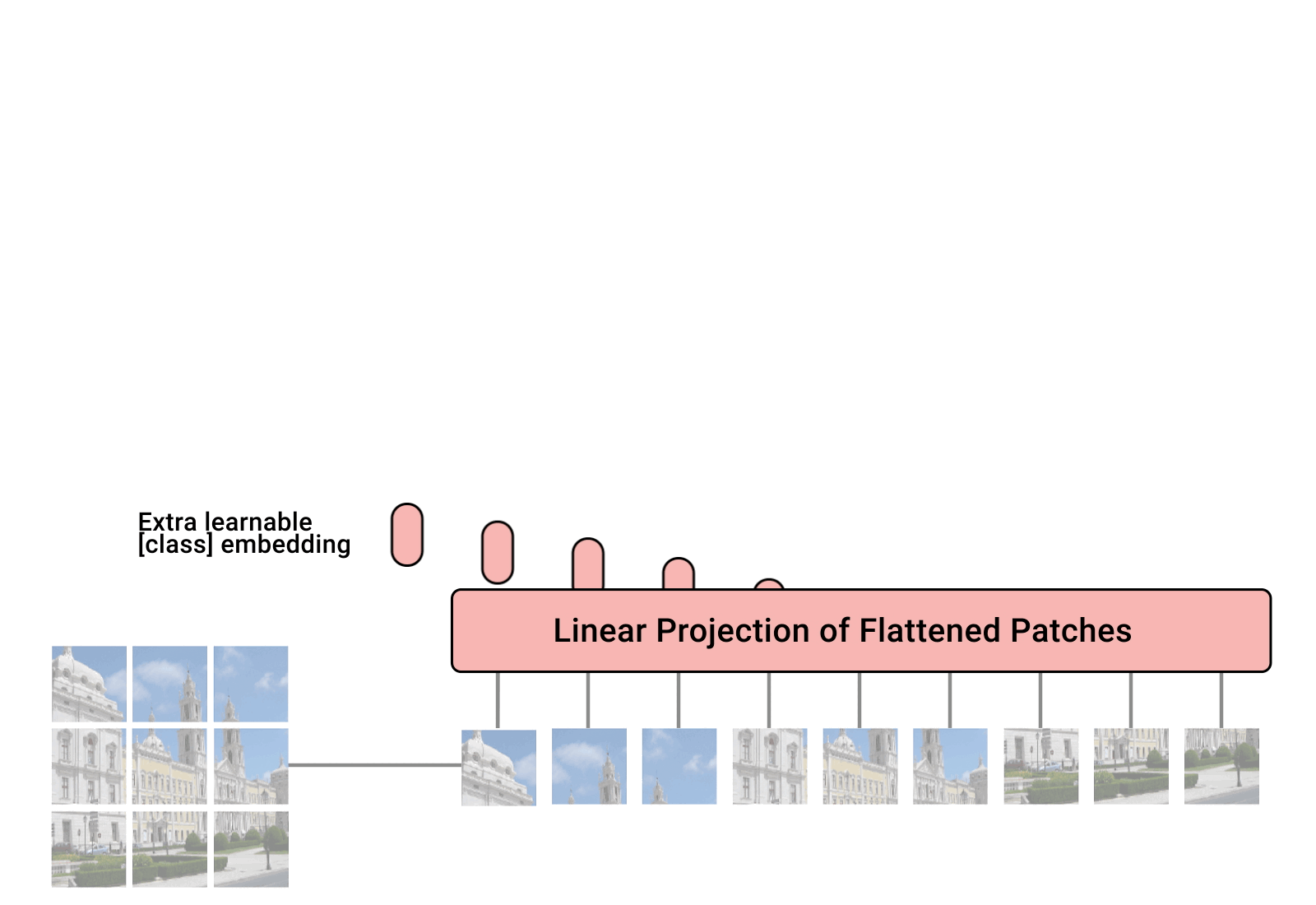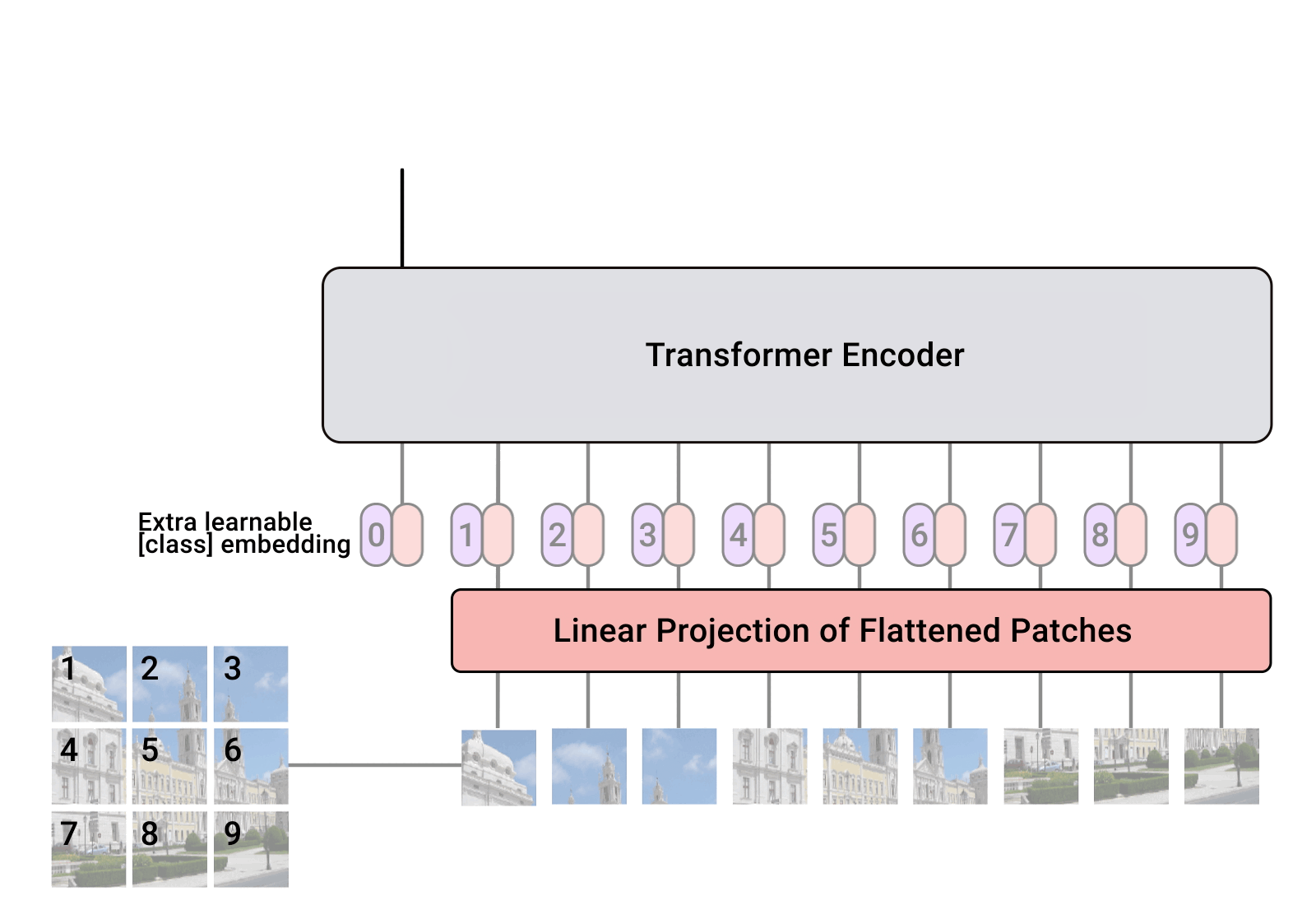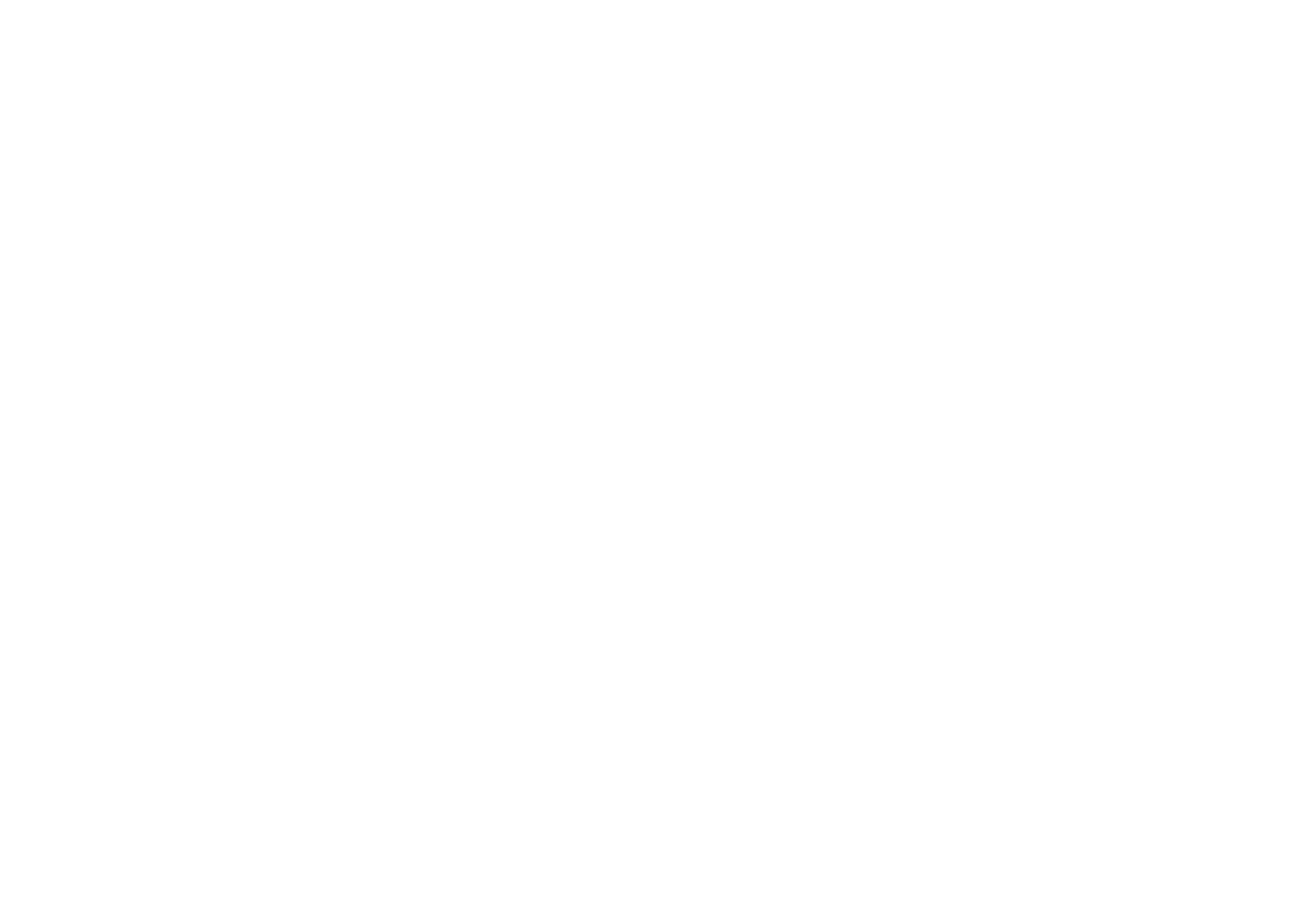
4. Swin Transformer
Swin Transformer는 Shifted Window 방식을 사용해 기존 ViT의 한계를 개선한 모델이다.
ViT와 달리 계층적 구조를 가지며, 윈도우 기반 attention으로 계산 복잡도를 줄였다.
다양한 크기의 객체 검출과 밀집 예측 작업에 적합하며, CNN의 장점과 Transformer의 장점을 결합했다.
Vit의 문제점
- 이미지 해상도가 증가: Self-attention을 계산해야하는 patch 당 픽셀 갯수가 매우 많아짐
- Patch의 크기가 크면 세밀한 representation을 생성하기 어려움
- Image에 대한 inductive bias가 많이 사라짐
Swin Transformer 구조
- Hierarchical 구조: 작은 단위의 patch부터 시작해서 점점 merge 해나가는 방식
- 계층적 구조로 각 단계마다 다른 representation을 가져 다양한 크기의 객체를 다뤄야 하는 태스크에 유리
ViT vs Swin Transformer 주요 차이점
- 패치 처리 방식
- ViT: 고정된 크기의 패치로 분할 후 전체 이미지에 대해 attention 계산
- Swin: 작은 패치부터 시작해서 단계적으로 merge하는 계층적 처리
- Attention 범위
- ViT: 모든 패치 간 global attention (계산량 많음)
- Swin: 윈도우 내에서만 local attention + shifted window로 정보 교환
- 계산 복잡도
- ViT: 이미지 크기에 따라 quadratic하게 증가
- Swin: 윈도우 크기에 따라 linear하게 증가 (효율적)
- 적용 분야
- ViT: 주로 이미지 분류에 특화
- Swin: 객체 검출, 세그멘테이션 등 다양한 dense prediction 태스크에 적합
- 특징 추출
- ViT: 단일 스케일의 feature만 생성
- Swin: 다양한 해상도의 hierarchical feature 생성 (CNN과 유사)
Semantic Segmentation
1. Semantic Segmentation 이란?
전 포스팅에서 Semantic Segmentation에 대해 간략히 살펴봤다.
하여 이번 섹션에서는 좀 더 자세한 내용을 다룬다.
Semantic Segmentation Process
- 이미지에서 각각의 픽셀마다 클래스 레이블을 예측하는 작업
- 즉, 클래스 레이블만으로 이루어진 출력 이미지를 얻음
- 입력: (H, W, 3) → 출력: (H, W, 1) or (H, W, 클래스 개수)
- 픽셀 단위로 분류하므로 픽셀 수준의 이해(pixel-level understanding)가 필요
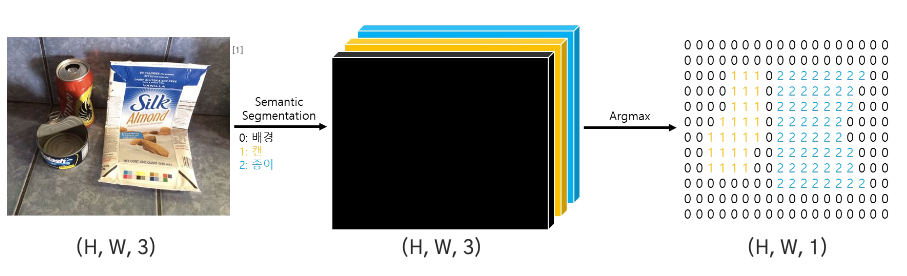 Semantic Segmentation Process
Semantic Segmentation Process
2. Segmentation 기본 개념들
Segmentation을 이해하기 위해서는 몇 가지 기본 개념들을 알아야 한다.
Encoder-Decoder 구조, Transposed Convolution, Dilated Convolution, Unpooling 등이 핵심이다.
Encoder-Decoder Architecture
- Encoder: 이미지의 semantic을 이해하는 과정
- 주로 convolution 연산으로 압축된 latent space를 가짐
- 예: (256, 256) → (32, 32)
- Decoder: 압축된 정보를 다시 원래 이미지 크기로 확장
- Semantic segmentation을 위해 필요한 과정
- 예: (32, 32) → (256, 256)
Transposed Convolution
- Decoding 과정에서 필요한 딥러닝 연산
- 일반 convolution과 달리 해상도의 크기를 키움
- Learnable kernel을 통해 upsampling 수행
- Deconvolution이라고도 불리지만, 수학적으로 정확한 역연산은 아님
Dilated Convolution (Atrous Convolution)
- 커널 사이의 각 원소 간격을 키울 수 있음 (dilation rate)
- Receptive field size를 키울 수 있음
- 파라미터 수 증가 없이 더 넓은 영역의 정보 획득
- 고해상도 이미지의 segmentation에 적합
Unpooling
- Pooling의 역연산으로 이미지 해상도를 다시 키우는 방법
- 방법 1: 0으로 채우기 (Zero padding)
- 방법 2: Pooling 시 위치 정보를 저장했다가 복원 (Max unpooling)
- Decoder에서 세밀한 위치 정보 복원에 활용
3. FCN (Fully Convolutional Network)
FCN은 Semantic Segmentation의 가장 기초가 되는 모델로,
기존 분류 네트워크의 FC layer를 1x1 convolution으로 대체한 것이 핵심이다.
FCN의 주요 특징
- Fully Connected Layer 제거
- FC layer는 위치 정보를 잃음 (flatten 과정)
- 1x1 convolution으로 대체하여 위치 정보 보존
- 다양한 입력 크기에 대응 가능
- VGG 백본 사용
- Pre-trained VGG 네트워크를 encoder로 활용
- FC layer를 convolutional layer로 변경
- Transposed Convolution
- Decoder에서 해상도를 원본 크기로 복원
- Pixel-wise prediction 수행
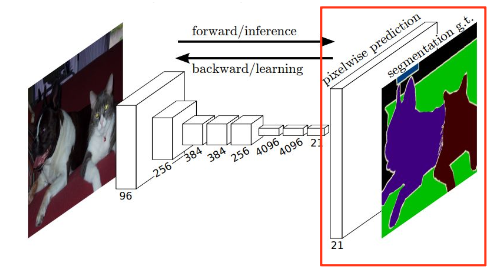 FCN 아키텍처
FCN 아키텍처
Skip Architecture
- 더 세밀한 segmentation map을 얻기 위한 기법
- 최종 feature map만 사용하지 않고 중간 feature map도 활용
- 세 가지 버전:
- FCN-32s: 최종 레이어만 사용 (32배 upsampling)
- FCN-16s: Pool4 레이어 추가 활용 (16배 upsampling)
- FCN-8s: Pool3 레이어까지 활용 (8배 upsampling)
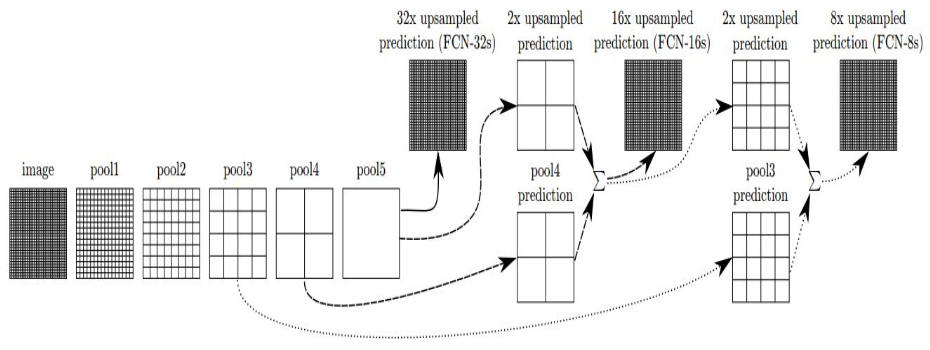 Skip Architecture
Skip Architecture
FCN의 한계점
- 객체의 크기가 매우 크거나 작으면 예측 정확도 저하
- 세밀한 경계선 표현이 어려움
- 전역적 문맥 정보 활용 부족
FCN 이후 발전된 모델들
- U-Net: 의료 영상 분석에 특화, 대칭적 encoder-decoder 구조
- DeepLab: Atrous convolution과 CRF 활용
- SegNet: Pooling indices를 활용한 효율적인 unpooling
- DeconvNet: 깊은 deconvolution 네트워크
- DilatedNet: Dilated convolution을 적극 활용
4. 최신 Segmentation 모델들
최근에는 Transformer 기반 모델들이 Segmentation 분야에서도 주목받고 있다.
Self-attention 메커니즘을 통해 전역적 문맥 정보를 효과적으로 활용한다.
Transformer 기반 Segmentation
- SETR (SEgmentation TRansformer)
- Pure transformer를 encoder로 사용
- ViT 구조를 그대로 활용
- Swin Transformer for Segmentation
- Hierarchical feature를 활용
- 다양한 스케일의 정보 통합
- SegFormer
- 효율적인 transformer encoder
- 간단한 MLP decoder