[Upstage AI Lab] 14주차 - CV Basic
[Upstage AI Lab] 14주차 - Computer Vision 학습 내용
들어가며
이번 포스팅에서는 Computer Vision(CV) 분야의 기본 이론과 핵심 개념을 정리했다.
고전 Computer Vision
1. 고전 Computer Vision 이란?
고전 CV 란 규칙 기반의 image 처리 알고리즘 (OpenCV)이다.
대표적으로는 image 의 색상, 밝기, 경계, 형태 등을 기반으로 추출하는 알고리즘들이 있다.
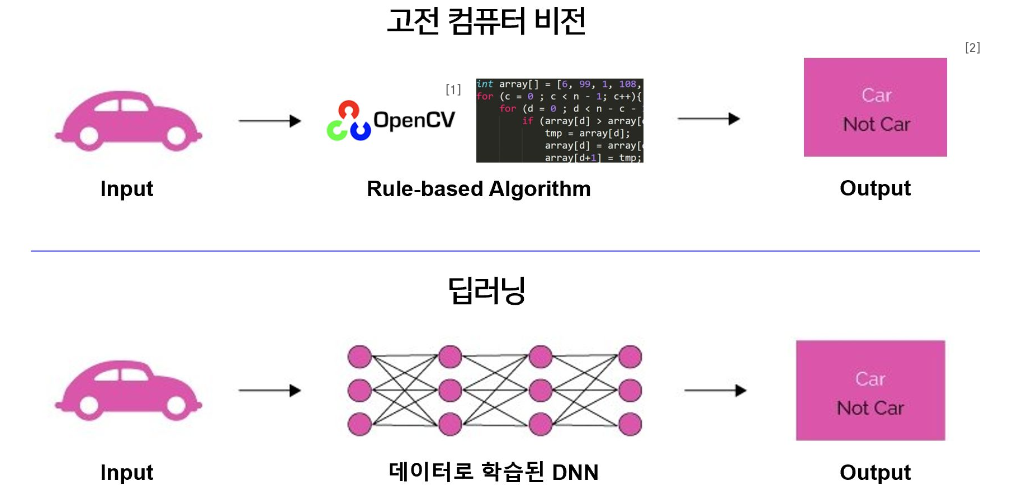
- 딥러닝이 등장하기 전까지 사람이 직접 정의한 규칙과 수학적 연산을 통해 이미지를 처리하고 분석하던 방식
- 대표적인 알고리즘: Canny Edge Detection, Hough Transform, Histogram Equalization 등
- 일반적으로 OpenCV 라이브러리 등을 통해 구현
- 활용 사례
- 로보틱스에서의 물체 탐지
- AR/VR에서의 경계 추출
- 딥러닝 모델의 전처리 또는 후처리 단계
2. Morphological Transform
Morphological Transform은 이미지에 기반한 연산이며
주로 흑백 이미지에서 객체의 모양을 분석하고 강조하는 데 사용된다.
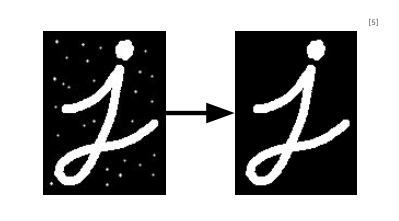
- 기본 개념
- 픽셀 단위의 연산을 통해 객체의 형태를 유지하거나 제거함
- 대표적인 연산으로 침식(Erosion), 팽창(Dilation), 열림(Opening), 닫힘(Closing) 등이 있음
- 커널 종류
- Erosion: 물체의 경계를 침식, 이미지의 특징을 축소할 때도 사용 가능
- Dilation: Erosion과는 정반대로 동작, 사물의 크기를 팽창할 때도 사용 가능
- Opening: Erosion > Dilation 순서대로 동작되는 연산
- Closing: Dilation > Erosion 순서대로 동작되는 연산
- Morphological gradient: 팽창과 침식의 차이(차집합)를 계산
- Top hat: 원본 이미지에서 Opening 연산 결과를 뺀 이미지
- 활용 예시
- 문자 인식 전처리 (노이즈 제거, 윤곽 정리)
- 의료 영상에서 병변 영역 강조
- 객체 경계 개선 및 마스크 정제
- code 구현
- Erosion:
cv2.erode(image, kernel, iterations=1) - Dilation:
cv2.dilate(image, kernel, iterations=1)
- Erosion:
3. Contour Detection
Contour 란 이미지에서 동일한 밝기 또는 색상 값을 가진 픽셀들이 연결되어 형성된 경계선을 말한다.
고전 컴퓨터 비전을 활용하여 raw image에서 객체의 contour 를 추출

- 활용
- 딥러닝 모델 학습을 위한 데이터 가공 시 활용 가능
- 처리 과정
- Edge Detection → (Optional) Dilation → Contour Detection
- Canny Edge Detector 과정
- 노이즈 제거
- 이미지 내의 높은 미분값 찾기
- 최대값이 아닌 픽셀을 0으로 치환 (Non-Maximum Suppression)
- 하이퍼파라미터 조정을 통한 세밀한 엣지 검출
Computer Vision
1. Computer Vision (CV) 이란?
AI 의 한 종류로, Vision 데이터들에서 의미 있는 정보를 추출하고
이를 해결한 것을 바탕으로 여러가지 작업을 수행하는 것 (ex: image)
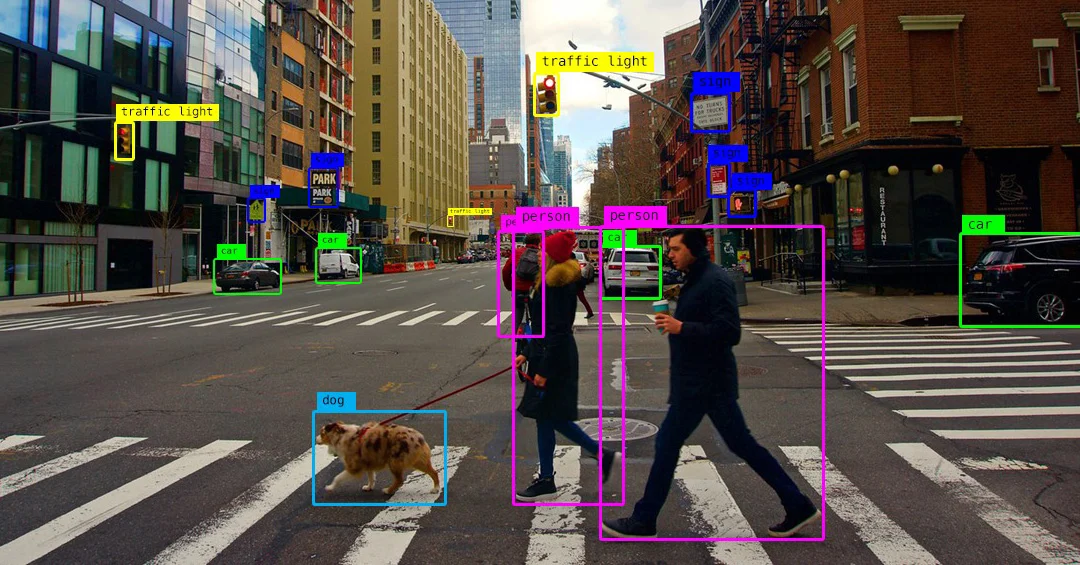
활용 사례
- Pose Estimation: 사람의 관절 위치를 추정하여 동작 인식 및 스포츠 분석 등에 활용됨
- OCR: 이미지 내 문자 정보를 추출하여 문서 스캔, 자동 문서화 등에 사용됨
- Medical Image Analysis: X-ray, MRI 등의 의료 영상을 분석하여 질병 진단 및 이상 탐지에 활용
- Gen AI: Text를 이미지로 생성하거나 이미지를 다른 스타일로 변환하는 작업에 사용됨
- NeRF: CV와 CG가 결합된 기술로, 2D 이미지를 활용해 3D 공간 정보를 복원하는 방법
2. Backbone
image 에서 중요한 Visual Feature을 추출해주는 기본 네트워크 구조
다양한 비전 Task 에서 공통적으로 사용되며, 해당 Task에 맞게 학습됨
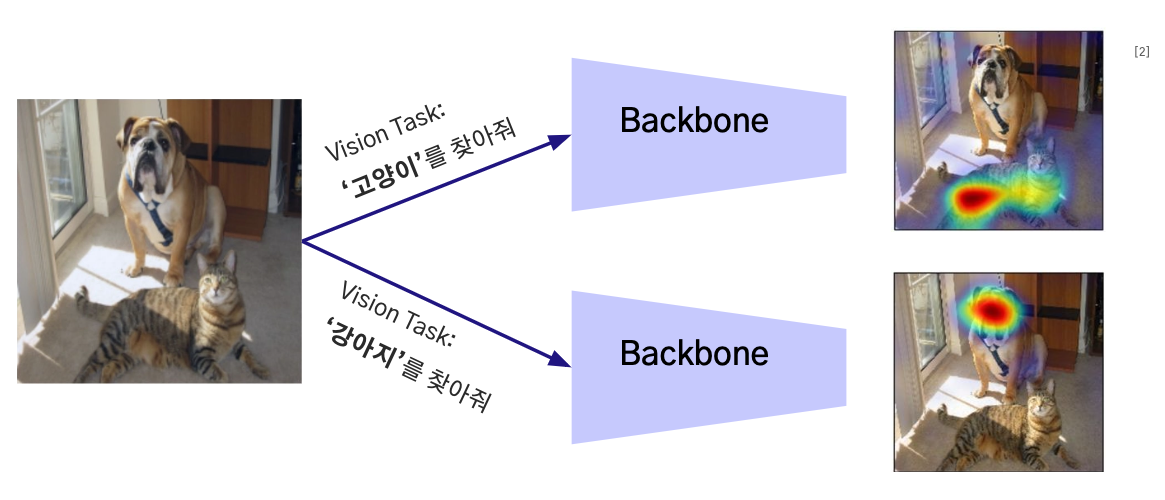
Visual Feature 란?
- Computer Vision 의 Task 를 해결할 떄 필요한 이미지의 특성을 담고 있는 정보
- ex: 코끼리의 특징: 긴 코, 큰 귀, 회색빛 피부 등

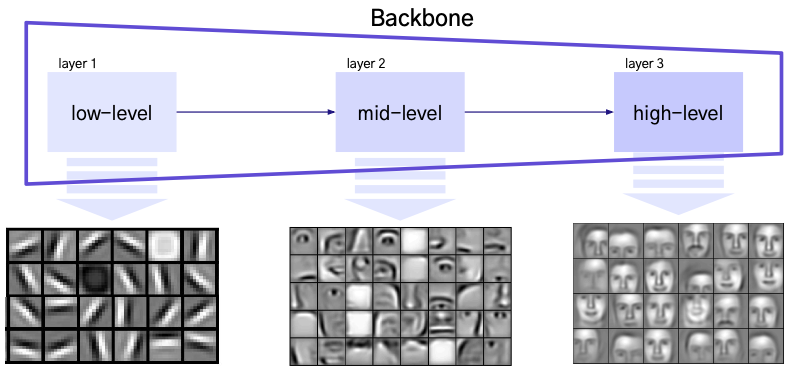
Backbone 구조
- Layer: Input 이미지에서 Feature 를 추출하기 위한 연산을 하는 층
- Backbone 은 여러 개의 Layer로 이루어져 있고, 이를 통해 다양한 Level의 Feature를 추출할 수 있음
3. Decoder
압축된 Feature 를 목표하는 Task (분류, 마스크, 텍스트)등 의 출력 형태로 만드는 과정을 수행
즉, 의미 있는 Feature 를 활용해 최종 결과를 생성하는 역할
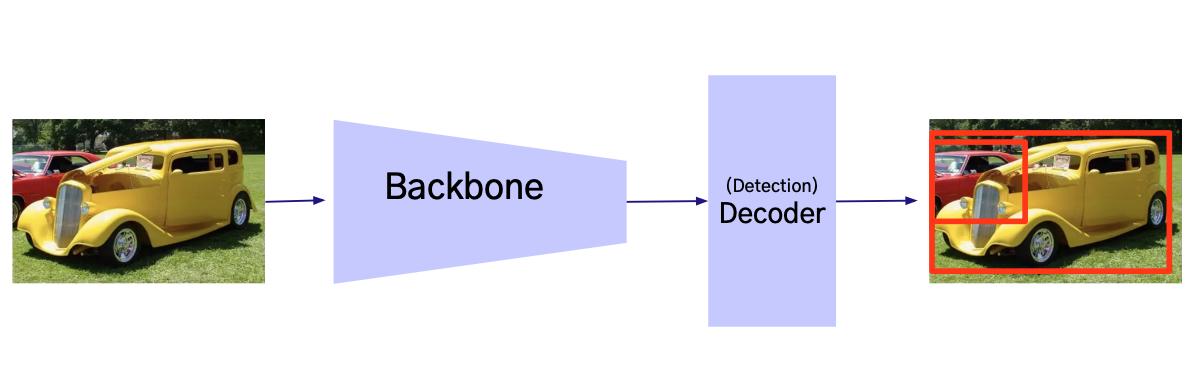
- Decoder의 주요 역할
- Backbone 을 통해 추출·압축된 Feature를 입력 받아, Task별 정답 형식에 맞춰 출력을 변환
- Task에 따라 구조와 방식이 달라지며, 대표적인 Task로는 분류, 탐지, 분할 이 있음
- Task별 예시
- Classification: Fully Connected Layer → Softmax를 통해 각 클래스 확률 출력
- Detection: 객체 위치 (bounding box 좌표) + 클래스 확률을 함께 출력
- Segmentation: 픽셀 단위로 클래스를 예측하여, 물체의 경계를 영역으로 분리해 출력
- 핵심 개념
- Backbone 은 Task 종류가 다르더라도 동일한 Backbone을 사용할 수 있음
- Decoder 의 경우에는 Task 가 바뀌면 그에 맞게 구조를 변경해줘야 함
4. Object Detection 이란?
Object Detection(객체 탐지) 은 이미지나 영상 내에서 여러 개의 객체를 찾고,
각 객체가 어디에 위치했는지(좌표)와 무엇인지(클래스)를 동시에 예측하는 Task를 의미한다.
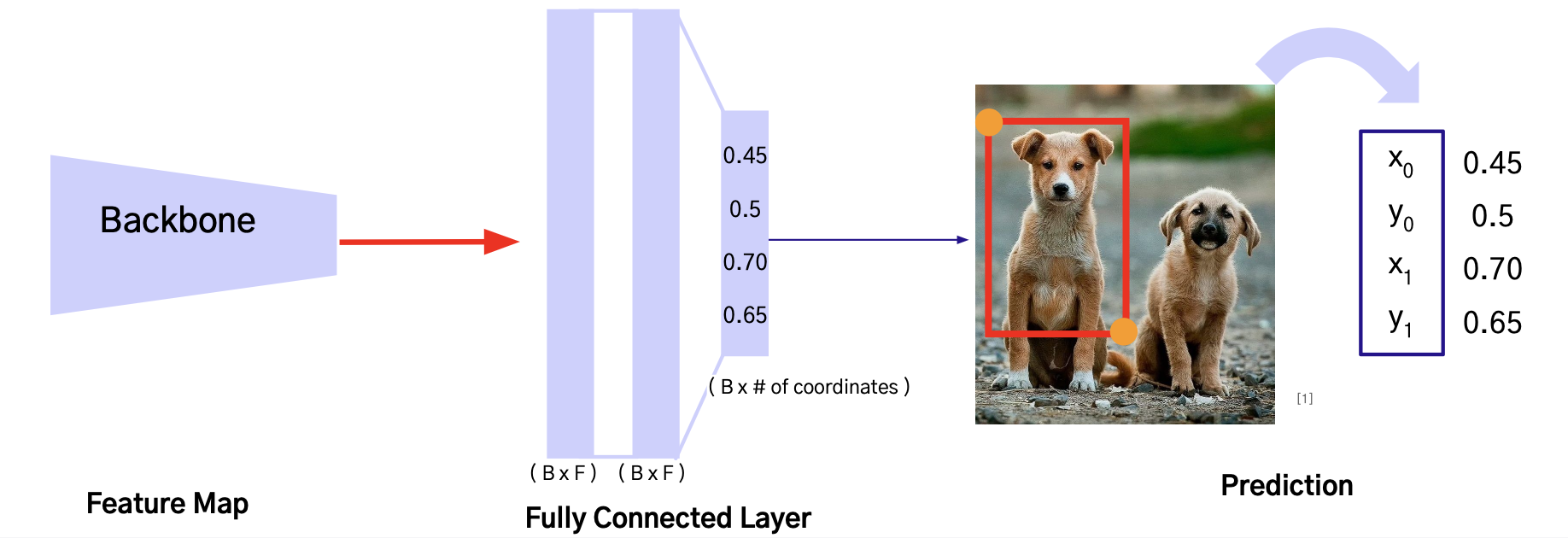
- Image Classification: 이미지 내에 어떤 물체가 있는지 분류
- Object Detection: 이미지 내의 각 Bbox 마다 객체의 클래스 분류 및 Bbox의 위치 추론
- Bounding Box: {x0, y0, x1, y1} 죄표 예측
- Category: 사물의 class label 예측
- Localization: Bounding Box Regression으로도 불리며, 각 Bounding Box의 {x0, y0, x1, y1} 예측
2 Stage Detector
2-Stage Detector는 Object Detection을 위해 2단계로 나누어 처리하는 방식으로,
Regional Proposal과 Classification 이 순차적으로 이루어진다.
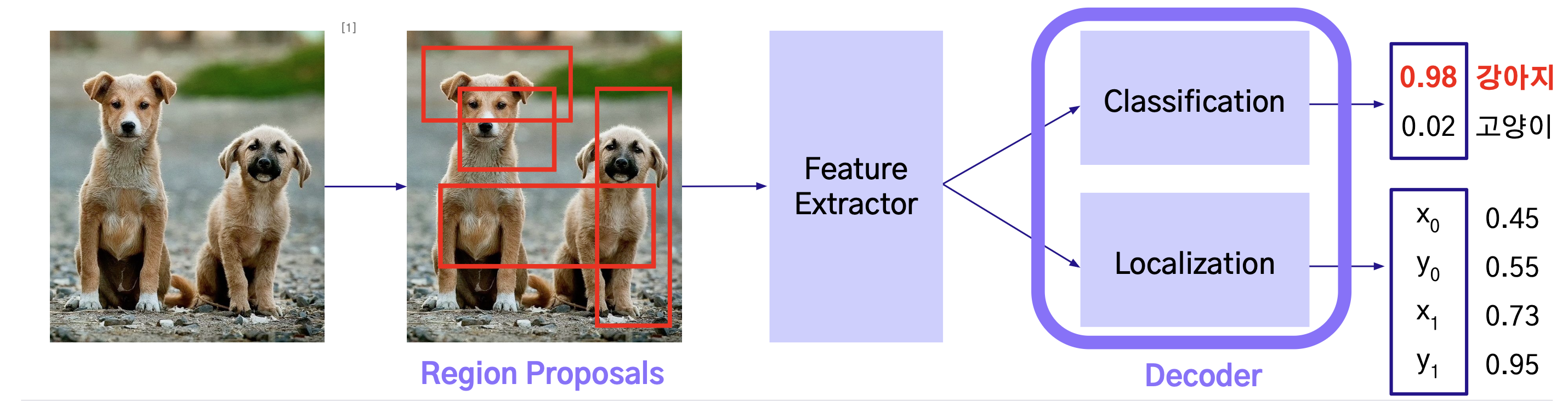
- Region Proposals 및 Feature Extractor를 거치며 object detection 수행
- Region Proposals: 다양한 크기와 모양의 Bounding Box로 물체의 위치를 제안
- Feature Extractor: 제안한 Region (Bounding Box)에 대하여 물체의 특성 추출
Regional Proposal 이란?
- 기존에는 이미지에서 Object Detection을 위해 Sliding Window 방식을 이용했었다.
- Sliding Window 방식은 이미지에서 모든 영역을 다양한 크기의 Window로 탐색하는 것
- 이러한 비효율성을 개선하기 위해 ‘물체가 있을’ 영역을 빠르게 찾아내는 알고리즘이 Regional Proposal 이다.
- 즉, Regional Proposal 은 Object 의 위치를 찾는 Localization 문제다.
 Sliding Window 예시
Sliding Window 예시
1-Stage Detector
2-Stage Detector와 반대로 regional proposal와 classification이 동시에 이루어진다.
즉, classification과 localization 문제를 동시에 해결하는 방법이다.
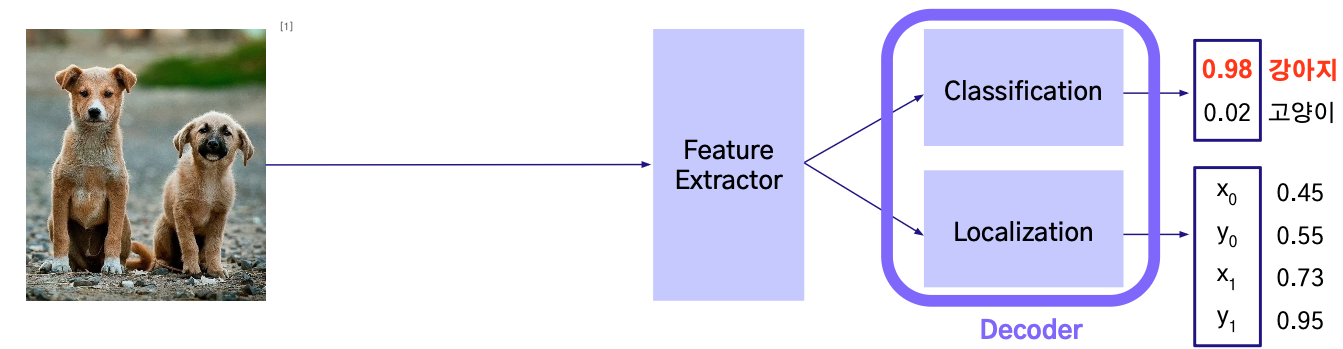
- Region Proposals 없이, Feature Extractor만을 이용한 object detection 수행
- Feature Extractor
- 입력 이미지를 특성으로 변환
- 해당 특성을 이용하여 추후 Classification 및 Bounding Box를 예측하는 작업 수행
1-Stage Detector 는 빠르지만 정확도가 낮고 2-Stage Detector 는 느리지만 정확도가 높다.
5. Detection Metrics
Object Detection 모델의 성능을 평가하는 지표는 대표적으로 IoU, mAP 등이 사용된다.
IoU
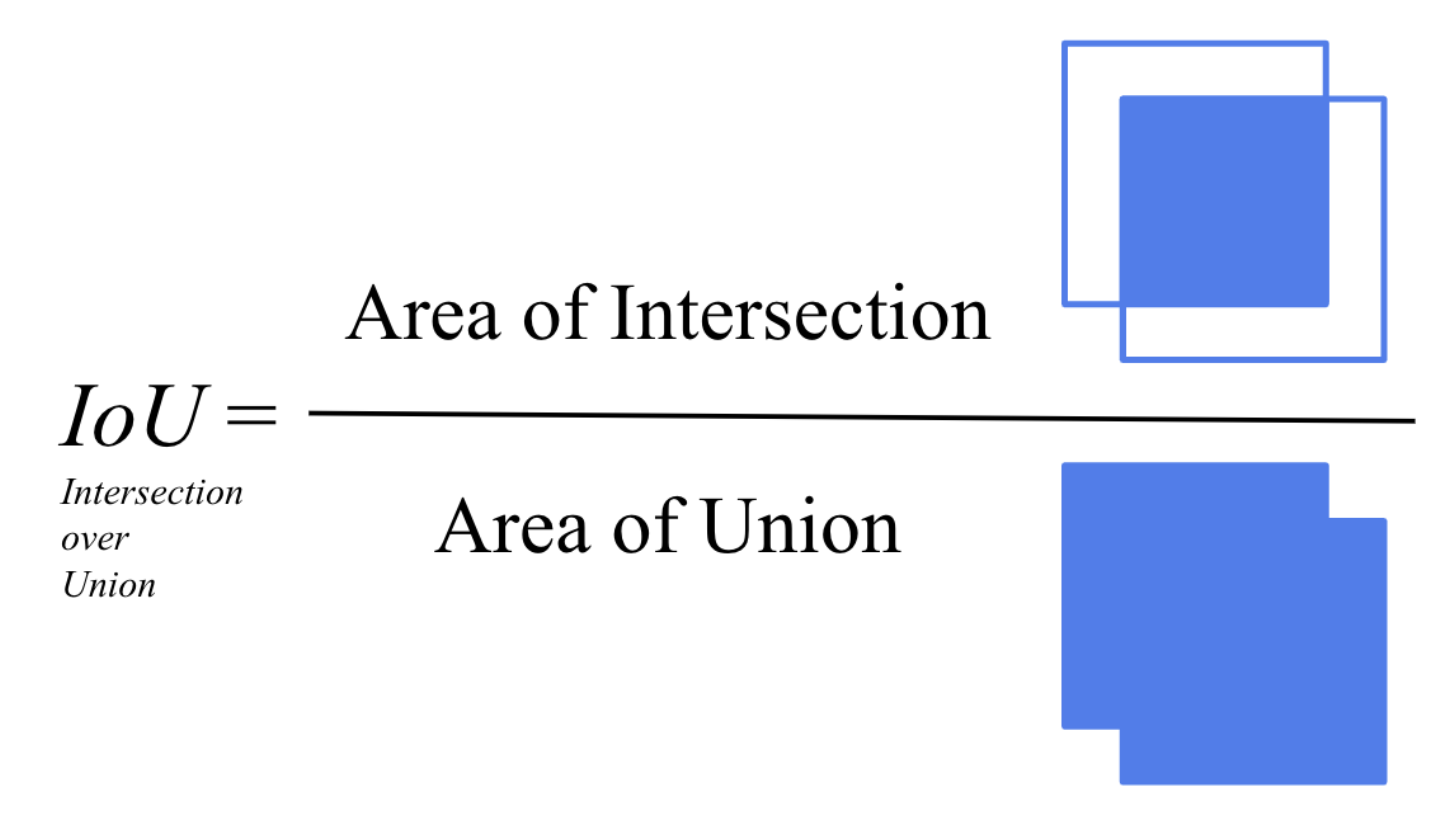 IoU 수식
IoU 수식
- 예측 박스와 실제 박스가 얼마나 겹쳤는지 비율로 나타내며 위치 예측의 정확도를 평가함
- 값이 클수록 모델이 object detection 을 잘한다는 해석을 할 수 있다.
- 특정 threshold 값을 넘긴 Predict Bounding box에 대해서 TP로 판단
- 즉, threshold는 사용자가 모델 평가 기준으로 직접 설정해야 한다.
Precision-Recall
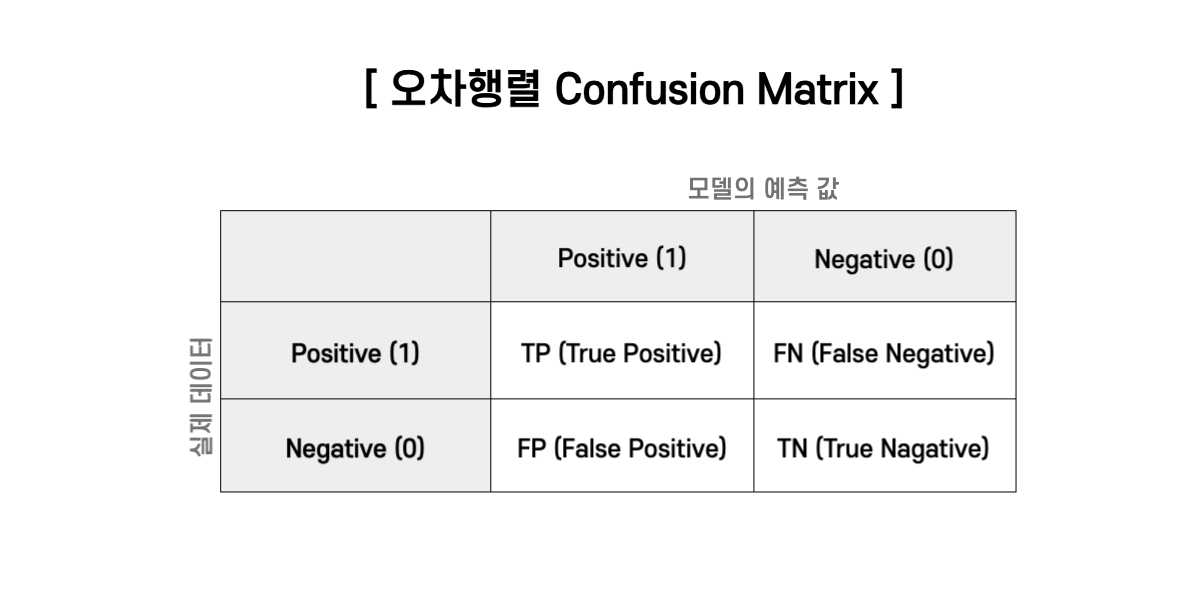
- mAP의 이해를 하기 전 필수 개념인 Confusion Matrix을 알아보자.
- 여기서 Precision이란 예측 결과가 얼마나 정확한지를 나타내는 지표이다.
- Recall은 전체 정답 중 모델이 맞춘 비율을 나타낸다.
- 또한, Precision 과 Recall은 Trade-Off 관계를 갖는다.
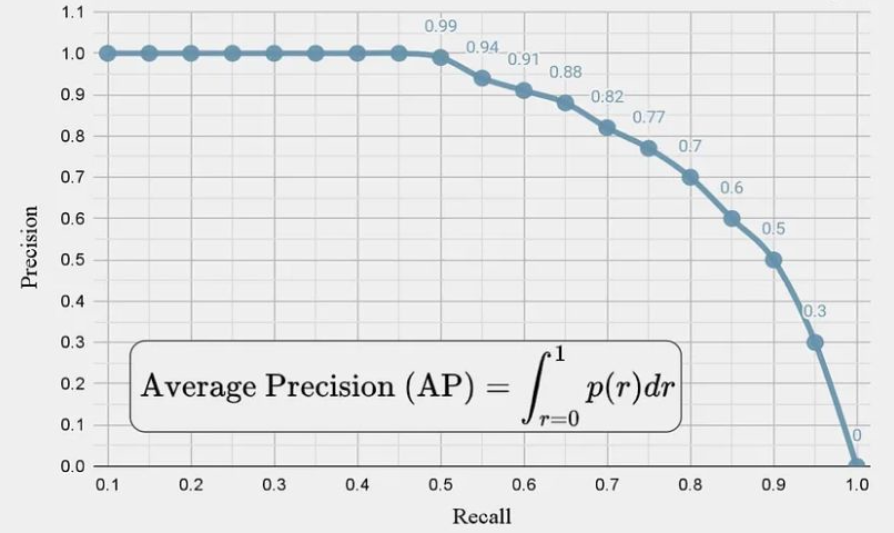 Precision Recall (PR) Curve
Precision Recall (PR) Curve
Average Precision (AP)
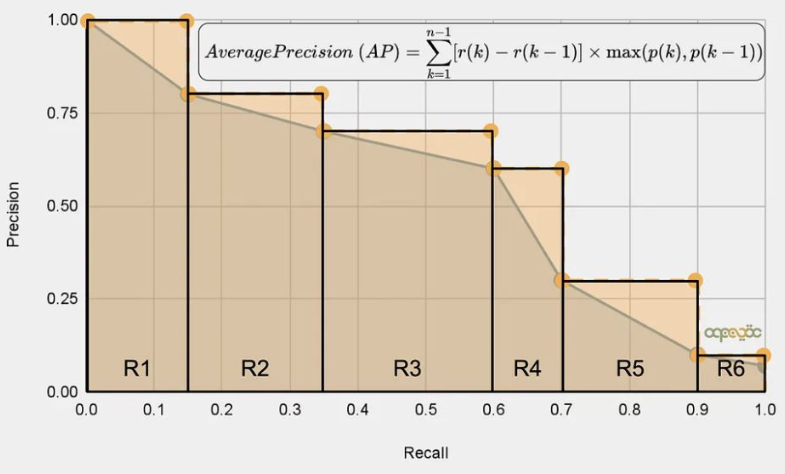
- Precision과 Recall의 Curve 넓이를 계산 (AP 라고도 함)
- AP는 PR Curve의 아래 영역이 된다. AUC가 ROC curve의 아래 영역을 의미하는 것과 동일
- 쉽게 말하자면 PR Curve 에서 계단 형식으로 다시 그린 그래프의 밑넓이를 Average Precision 라고 한다.
- 이 때 11점 보간법이 사용되는데 11점 보간법이란 ?
- Precision-Recall 곡선을 계산할 때 사용되는 방식으로, 곡선의 넓이를 근사적으로 구하기 위해 등장한 방법
- PR Curve 상에서 Recall을 총 11개의 지점으로 나눈 후
- 각 구간에서 해당 Recall 이상에서의 최대 Precision 값을 샘플링해 평균을 낸다.
mAP (mean Average Precision)
- Object Detection task 에서는 Class가 여러개 있을텐데 각 Class마다 AP를 구하고
- 모든 Class에 대해 더한 뒤 Class의 개수로 나누는게 mAP 이다.
- 즉, 여러 Class의 예측 성능을 종합적으로 평가할 수 있는 지표다.
6. R-CNN 이란?
R-CNN은 설정한 Region을 CNN의 입력값으로 활용하여 Object Detection을 수행하는 신경망이다.
2-Stage Detector로 Region Proposals 단계를 수행
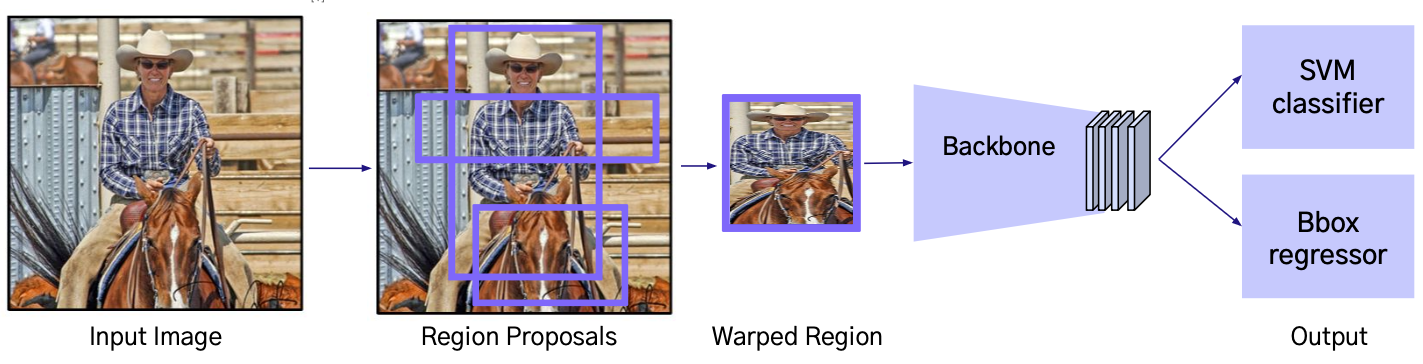
- 2014년에 CNN을 Object Detection 분야에 최초로 적용시킨 모델이며
- CNN을 이용한 검출 방식이 Classification 뿐만 아닌 Object Detection 분야에도
- 높은 수준의 성능을 이끌어 낼 수 있다는 것을 보여준 의미 있는 모델이다.
- Fast R-CNN, Faster R-CNN 모델의 기반이 됨
Process
- Region Proposals: Selective Search 기법으로 2,000개의 ROI를 추출
- RoI(Region of Interest): 이미지에서 물체가 있을 법한 관심 영역을 나타내는 후보 영역
- Selective Search: 인접한 영역 (Region)끼리 유사성을 측정해 큰 영역으로 통합
- Warped Region: 각 RoI 에 대하여 동일한 크기의 이미지로 변환
- Backbone: Region Proposals마다 각각의 Backbone (CNN)에 넣어서 결과를 계산
- Output: 각 Region Proposals마다 SVM으로 Class 분류 결과를 예측
- Bbox Regression: Backbone의 Feature를 Regression으로 Bounding Box 위치 예측
즉, Selective Search로 2,000개의 RoI 를 뽑고 각 RoI 를 동일 크기로 Warped Region 해서 CNN에 입력
이때 Warped Region은 다양한 크기의 RoI를 CNN이 처리할 수 있도록 모두 같은 크기로 맞추기 위한 과정이다.
CNN이 각 RoI 의 특징을 추출 > SVM으로 객체 분류 > Bbox Regression으로 위치를 예측하는 방식으로 동작한다.
한계
- CPU 기반의 Selective Search 기법으로 인해 많은 시간이 필요
- 2,000개의 RoI로 인하여, 2,000번의 CNN 연산이 필요하며 많은 시간이 필요
Fast R-CNN
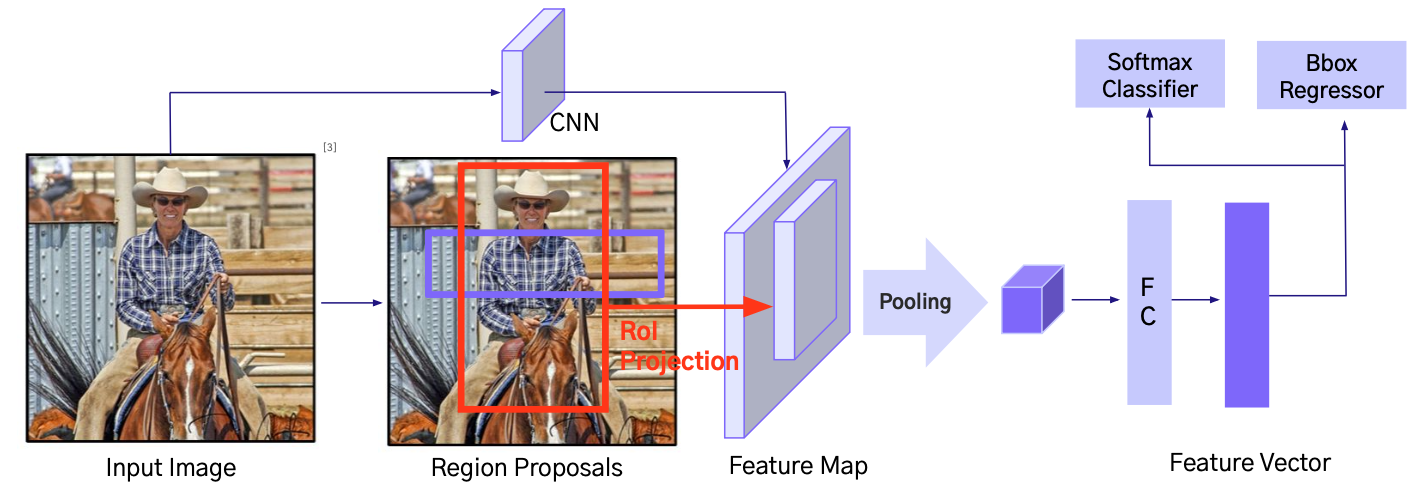
- ICCV 2015에 출판된 논문으로, R-CNN 모델에 비해 속도와 성능 면에서 큰 개선을 이룸
- R-CNN 과 다르게 Input Image를 한 번만 CNN에 넣어 Feature Map 생성
Process
- RoI Pooling: RoI를 고정된 크기의 grid로 나눈 뒤 max pooling으로 feature를 일정 크기로 변환
- Output: Pooling layer 와 FC layer를 거쳐, Feature Vector 생성
- Softmax Classifier: 각 RoI의 Class를 추론
- Bbox Regressor: 각 RoI의 Bounding Box 크기 및 위치를 조정
- Loss: Classification Loss와 Bounding Box Regression Loss를 동시에 계산
즉, 입력 이미지를 한 번만 CNN에 통과시켜 Feature Map을 생성하고
Region Proposal로 얻은 각 RoI를 Feature Map에 매핑해 RoI Pooling을 수행
RoI마다 고정 크기의 Feature Vector를 생성
FC Layer를 거쳐 Softmax Classifier로 클래스 예측 + Bbox Regressor로 위치 보정
Classification Loss와 Bounding Box Regression Loss를 동시에 계산하여 학습한다.
한계
- CPU 기반의 Selective Search 기법으로 인해 처리 속도 느림
- RoI Pooling 정확도 떨어짐
Faster R-CNN
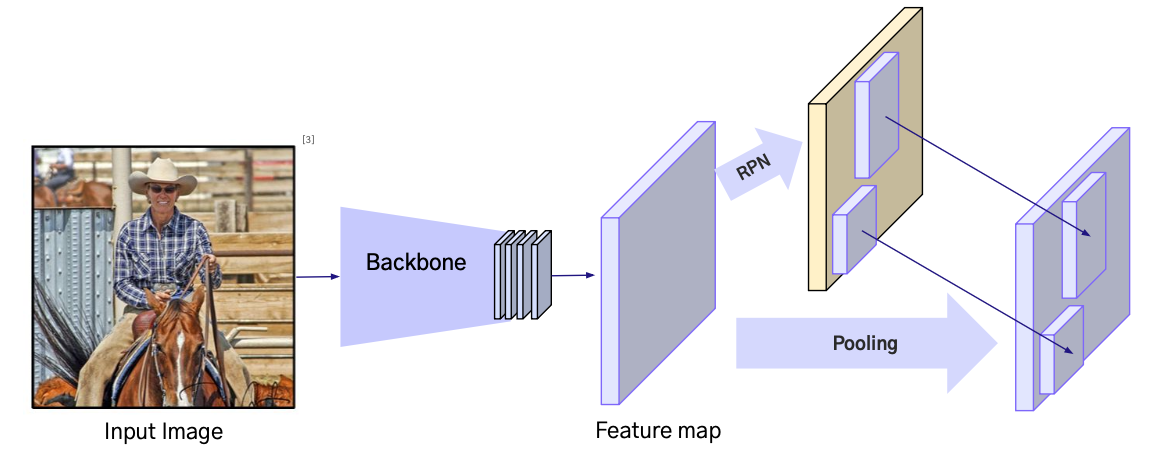
- NIPS 2015에 출판된 논문으로, R-CNN과 Fast R-CNN 모델에 비해 속도와 성능 면에서 큰 개선을 이룸
- Fast R-CNN + Region Proposal Network(RPN)의 구조
- RPN으로 기존 CPU연산을 GPU 연산으로 변환
Process
- RPN: Backbone에서 얻은 Feature Map 위에서 Anchor Box를 이용해 객체가 있을 확률과 위치를 예측
- RoI Proposal: RPN이 생성한 제안 영역(Region Proposal) 중 일정 기준 이상의 영역을 선택
- RoI Pooling: 선택된 RoI를 고정 크기의 grid로 변환하여 FC Layer에 입력할 Feature Vector로 만듬
- FC Layer: RoI Pooling 결과를 전결합층에 전달하여 특징을 추출
- Softmax Classifier: 각 RoI의 Class를 예측
- Bbox Regressor: RoI의 Bounding Box 위치를 보정
- Loss: RPN Loss + Classification Loss + Bounding Box Regression Loss를 동시에 계산
즉, Feature Map에서 RPN이 객체 후보 영역(RoI)을 생성하고
선택된 RoI는 RoI Pooling을 거쳐 FC Layer에 전달
FC Layer 이후 Softmax로 클래스 예측 + Bbox Regressor로 위치 보정
이 모든 과정이 CNN 한 번의 연산으로 엔드투엔드(end-to-end)로 학습 및 추론되며
기존 CPU 기반 Selective Search 병목을 RPN으로 대체해 속도와 정확도를 동시에 향상시켰다.
한계
- 2-Stage Detector로 연산량이 많아, 실시간 사용에 부적합
- 1-Stage Detector인 YOLO는 실시간 사용 가능
7. YOLO 란?
YOLO 는 1-Stage Detector의 대표적인 모델로 입력 이미지를 단 한 번의 CNN 연산으로
객체의 위치(좌표)와 클래스를 동시에 예측하는 End-to-End 방식의 단일 신경망 아키텍처를 사용한다.
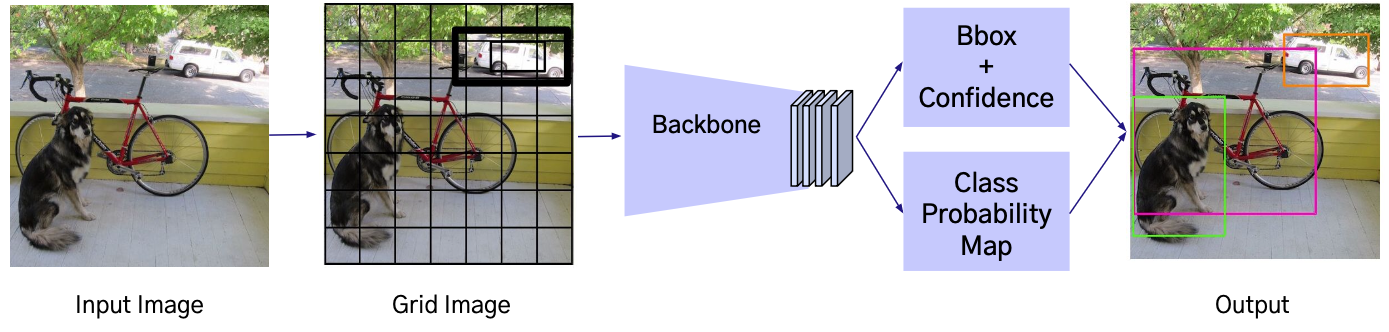
- CVPR 2016에 출판된 논문으로, 1-Stage Detector 분야의 초기 모델
- Single Shot Architecture: YOLO는 객체 감지를 위한 단일 신경망 아키텍처를 사용
- 이미지를 그리드로 나누고, 그리드 셀 별로 Bounding Box와 해당 객체의 클래스 확률 예측
Process
- Grid Image: 이미지를 SxS grid로 분할
- Confidence: grid cell의 bounding box에 객체가 있을 확률과 예측한 박스의 정확도(IoU)를 함께 나타낸 값
- Bounding Box + Confidence: 각 grid cell에서 bounding box 좌표와 confidence score 예측
- Class Probability Map: 각 grid cell에서 Class의 조건부 확률을 예측
- Output: 예측한 Bbox, Confidence, Class Probability로, Object Detection 결과 산출
- 낮은 Confidence의 Bbox를 제거
- 중복된 박스를 NMS(Non-Maximum Suppression)로 정리해 최종 Detection 결과를 생성
8. Semantic Segmentation 이란?
Pixel-wise 로 각각의 Class 를 예측하여 물체 Category 별로 분할하는 Task 이다.
즉, 이미지 내 모든 픽셀에 대해 어떤 Class에 속하는지 분류하여 사물의 경계와 형태를 구분할 수 있다.
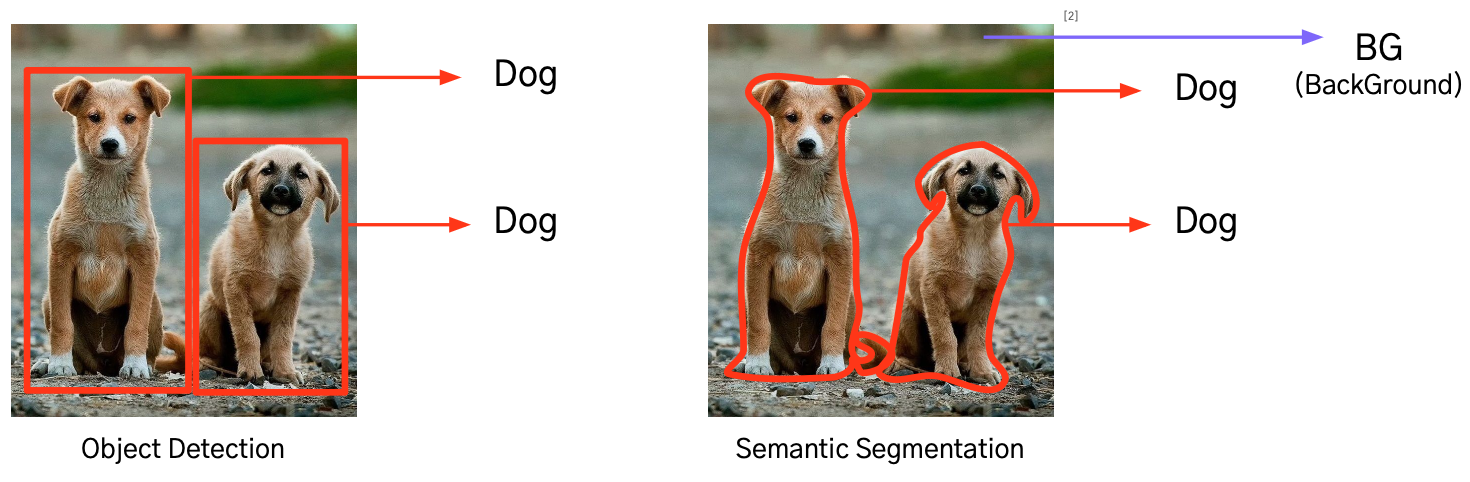
특징
- 이미지 내 동일한 Class의 객체들을 하나로 구분함
- ex: 사람 3명이 있어도 ‘사람’ 이라는 Class 하나로 구분
- Object Detection 과 달리 Box 단위가 아닌 Pixel 단위로 예측하기에 정밀한 구분 가능
- 대표 모델: FCN, U-Net, DeepLab 등
활용 사례
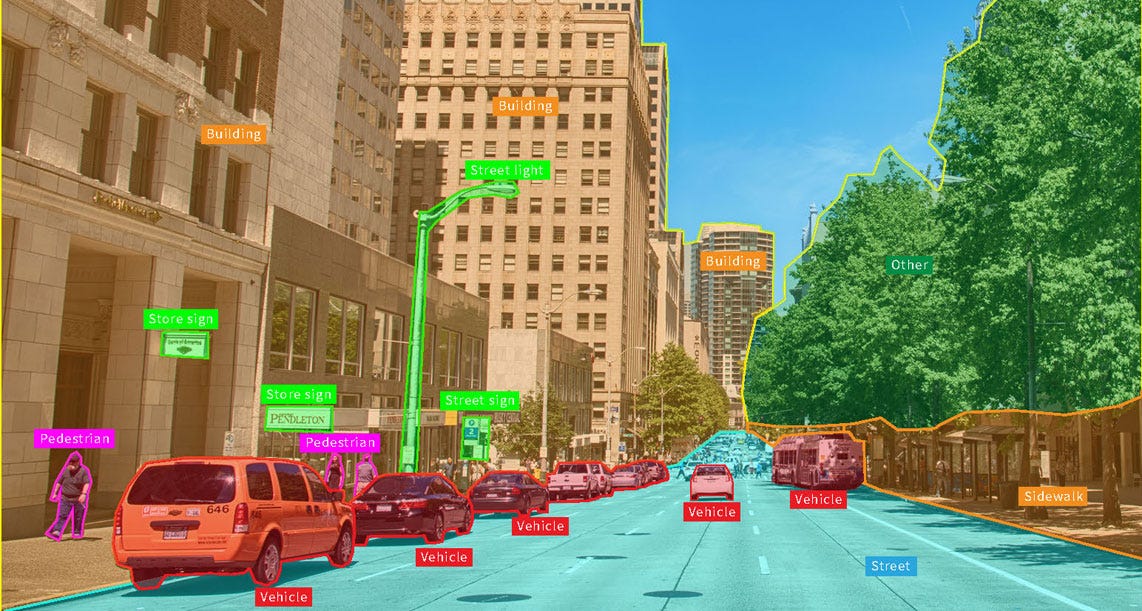
- 자율주행: 도로, 차선, 보행자 등을 픽셀 단위로 분할해 주행 판단에 활용
- 의료영상: CT/MRI 등에서 병변 영역의 정밀 탐지
- 위성/항공 이미지 분석: 건물, 도로, 산림 등 지형 요소 구분
 자율주행 예시
자율주행 예시
Segmentation의 종류
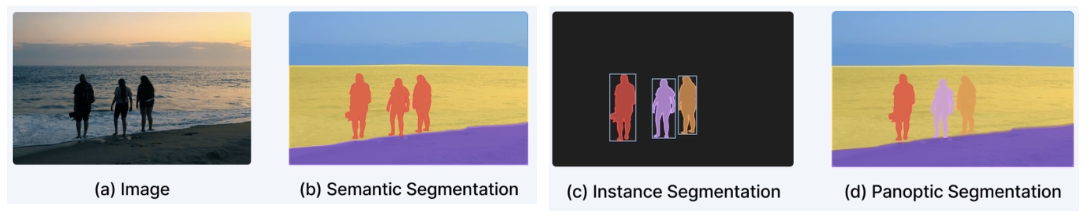
- Instance Segmentation: 같은 클래스라도 객체마다 다른 인스턴스로 구분해 픽셀 단위로 표시
- ex: 사람 여러 명이 있다면 각각 사람1, 사람2 로 분리해 인식
- Panoptic Segmentation
- Semantic + Instance Segmentation을 결합한 방법으로
- 배경 클래스는 Semantic Segmentation으로 처리하고
- 객체 클래스는 Instance Segmentation으로 처리해 모든 픽셀을 완전히 설명
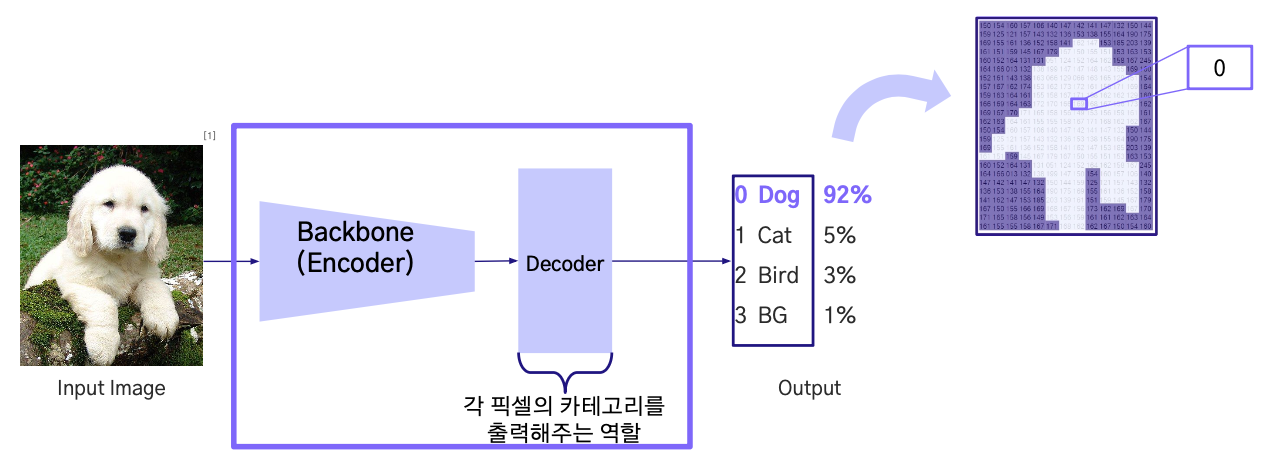
Semantic Segmentation 구조
Semantic 의 Backbone(Encoder)-Decoder는 다양한 방식으로 구성할 수 있으며
각 방법은 Receptive Field 확보와 정밀도 측면에서 장단점을 가진다.
Sliding Window 방식
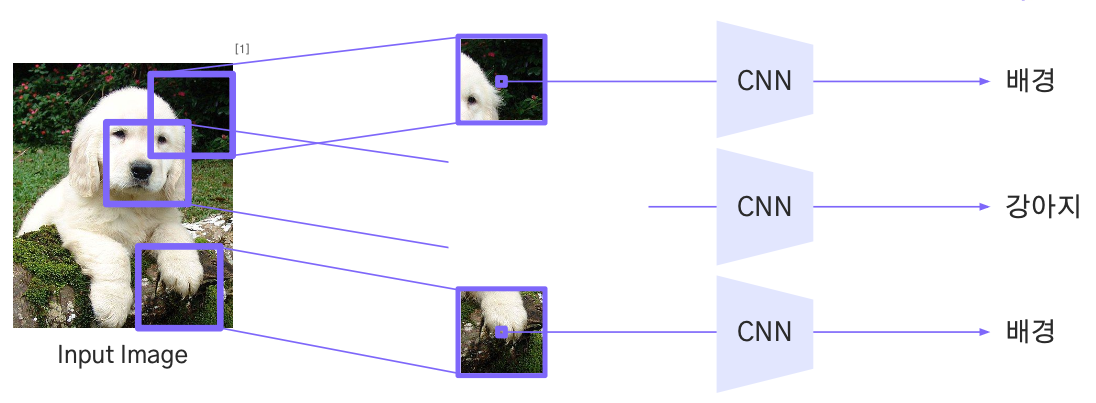
- 입력 이미지의 작은 패치 단위로 CNN을 적용해 각 패치별로 클래스를 예측하는 방식
- 문제점
- 픽셀 주변의 정보만 반영되며, 전역적 정보 부족
- 많은 패치가 중복되어 연산 비용이 커짐
- 개선 방법
- CNN 전체 입력에 대해 Feature Map을 한 번에 생성하여 중복 연산을 제거하고
- 더 넓은 문맥 정보를 반영할 수 있는 방법을 사용
Size Preserving Convolutional Layers
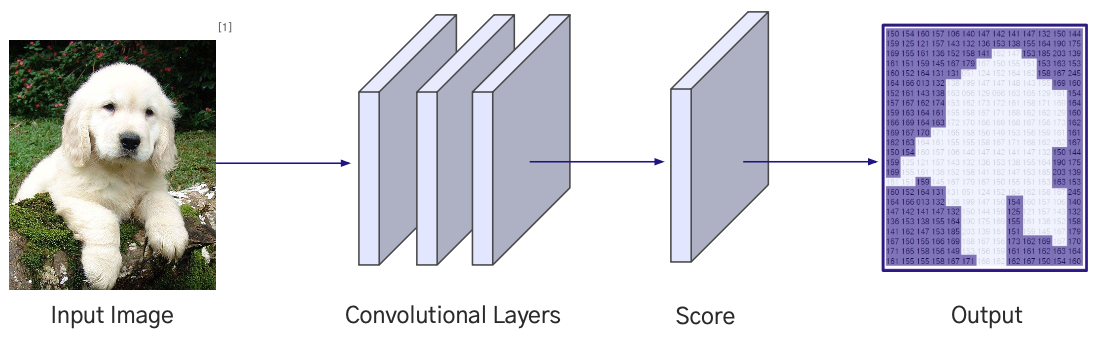
- 이미지 크기를 유지하며 Convolution Layer를 거쳐 Feature를 생성하고, 각 위치별로 Class Score를 예측하는 방식
- 문제점
- Receptive Field가 제한적으로 넓은 문맥 정보를 반영하기 어려움
- 개선 방법
- Downsampling 과 Upsampling 을 결합한 구조를 사용하여 Receptive Field를 확장
Downsampling + Upsampling 구조
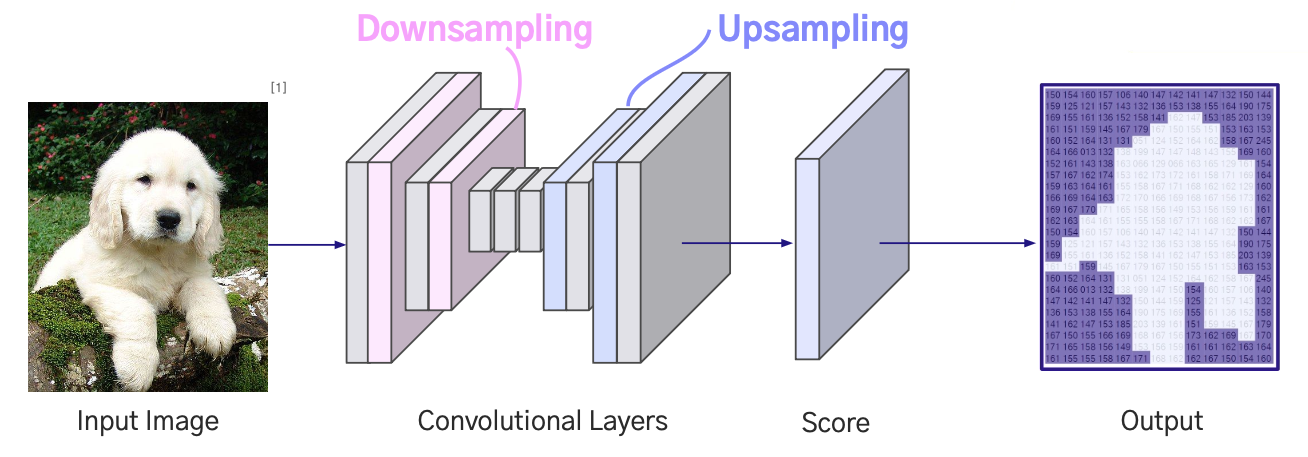
- Convolution과 Pooling으로 Downsampling해 Feature를 압축한 뒤, Upsampling을 통해 원래 크기로 복원
- 장점
- 큰 Receptive Field 확보로 이미지의 전역 정보 활용 가능
- 복잡한 형태의 객체 경계까지 정밀하게 예측 가능
- 대표 모델: FCN, U-Net, DeepLab 등이 해당 구조를 사용