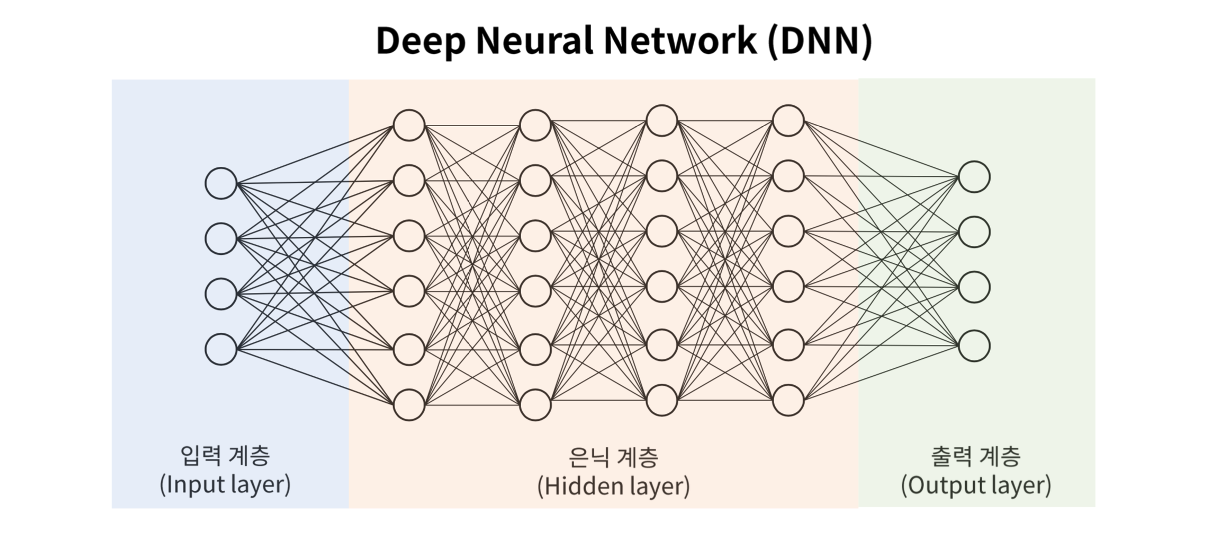
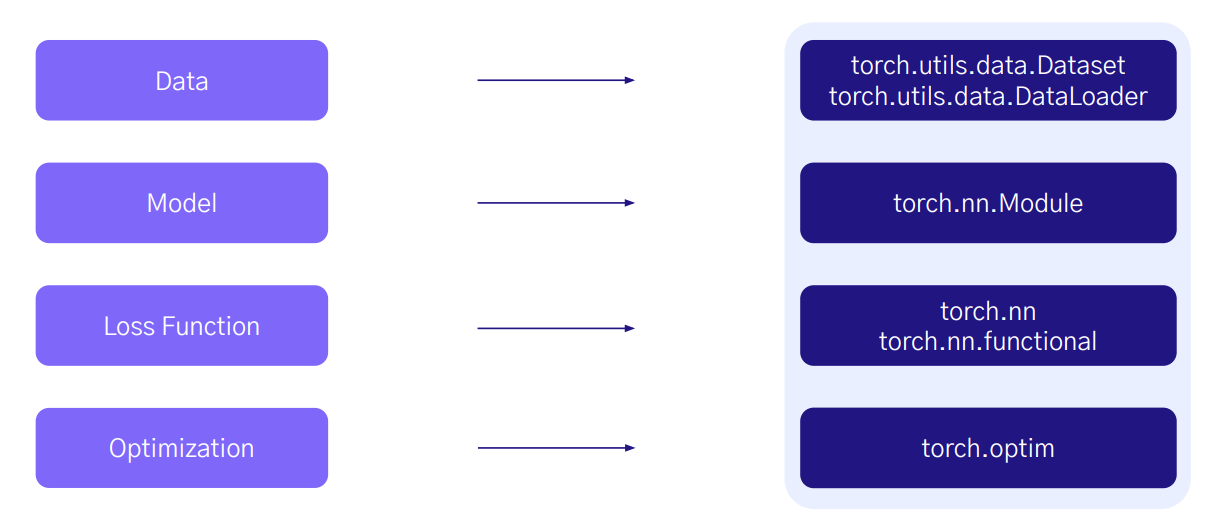
들어가며
이번 글은 Upstage AI Lab 과정 중 위키라이더 담당자로 선정되어 강의 내용을 요약한 내용이다.
PyTorch를 활용해 DNN 구현하면서 모델의 내부 동작 원리를 이해하는 데 초점을 맞췄다.
PyTorch 실습
1. PyTorch 작동 구조
PyTorch로 딥러닝 모델을 구성할 때는 크게 4가지 핵심 구성 요소를 중심으로 작동한다.
각각은 PyTorch 내부의 특정 모듈과 연결되어 있으며, 이 구조를 이해하면 전체 흐름이 훨씬 명확해진다.
- Data:
torch.utils.data.Dataset 클래스를 상속받아 정의 - Model:
torch.nn.Module을 상속하여 구현 - Loss Function:
torch.nn 또는 torch.nn.functional 내에서 선택하여 사용 - Optimization:
torch.optim 모듈에서 수행
Data
- 이 데이터를 batch 단위로 묶어주는 역할은 DataLoader가 수행하며
- 학습에 필요한 데이터를 효율적으로 불러오고 전처리할 수 있도록 구성
Custom Dataset
PyTorch가 기본으로 제공하는 Dataset 클래스를 그대로 쓰면 기능에 제한이 있다.
그래서 직접 데이터셋을 정의하는 경우, Dataset을 상속받아 새로운 클래스를 만들어야 한다.
이때 반드시 아래 3가지 메서드를 구현해야 한다.
__init__: 객체가 처음 생성될 때 실행되며, 파일 경로 설정, 전처리 등 초기 준비 작업을 수행__getitem__: 특정 Index를 받아 해당 위치의 데이터 샘플 하나를 반환__len__: 전체 데이터셋의 샘플 개수 반환
1
2
3
4
5
6
7
8
9
10
11
| from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self):
pass
def __getitem__(self, idx):
pass
def __len__(self):
pass
|
⚠️ Custom Dataset 주의사항
- 데이터 타입
__getitem__ 메서드는 데이터를 반드시 torch.tensor 형태로 반환해야 한다.- list, tuple, dictionary 형태도 가능하지만, 내부 값들은 모두 tensor여야 함
- 데이터 차원
DataLoader는 데이터를 batch로 묶기 때문에, 모든 데이터의 차원이 같아야 한다.- 예: 이미지 → 동일한 크기 (
height × width × channel) - 예: 텍스트 → 동일한 길이(
max_len)로 패딩 필요
DataLoader
Dataset에서 정의한 데이터를 batch 단위로 묶어 반환하는 역할- 필수 인자로
Dataset을 받고, 주로 자주 설정하는 인자는 다음과 같다.batch_size: 한 번에 불러올 데이터 수shuffle: 학습 시 매 epoch마다 데이터 순서를 섞을지 여부
Model
forward() 메서드 안에 데이터가 어떻게 흐를지(순전파 구조) 정의한다.- 신경망의 뼈대를 구성하는 부분
Torchvision
- Torchvision 라이브러리는 이미지 분석에 특화된 다양한 모델을 제공
- ResNet, VGG, AlexNet, EfficientNet, ViT 같은 대표적인 모델들을 손쉽게 가져와 쓸 수 있다.
- Torchvision에서 여러 가지 모델의 목록을 확인
1
2
3
| # 예시: torchvision에서 ResNet50 모델 불러오기
import torchvision
model1 = torchvision.models.resnet50()
|
PyTorch
- CV, 오디오, 생성 모델, NLP 분야까지 다양한 도메인의 모델이 공개되어 있다.
- PyTorch Hub에서 여러 모델의 목록을 확인
1
2
3
| # 예시: PyTorch Hub에서 ResNet50 모델 불러오기
import torch
model2 = torch.hub.load('pytorch/vision', 'resnet50')
|
Optimizer
optimizer.zero_grad(): 이전 gradient를 0으로 설정model(data): 데이터를 모델을 통해 연산loss_function(output, label): loss 값 계산loss.backward(): loss 값에 대한 gradient 계산optimizer.step(): gradient를 이용하여 모델의 파라미터 업데이트
Inference & Evaluation
model.eval() : 모델을 평가 모드로 전환 → 특정 레이어들이 학습과 추론 과정 각각 다르게 작동해야 하기 때문torch.no_grad() : 추론 과정에서는 gradient 계산이 필요하지 않음- Pytorch를 이용하여 평가산식을 직접 구현 or scikit-learn을 이용하여 구현
2. DNN 구현
이번 파트에서는 기본적인 DNN(Deep Neural Network) 모델을 직접 구현해봤다.
Jutyer 파일을 MarkDown으로 변환하는게 궁금하다면 테디노트를 이용하자 (매우 편함)
전체 코드는 GitHub에서 확인할 수 있다.
Library
1
2
3
4
5
6
7
8
9
10
11
12
13
| import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as T
import torchvision.utils as vutils
import torch.backends.cudnn as cudnn
import matplotlib.pyplot as plt
import random
import numpy as np
from torch.utils.data import Dataset, DataLoader
from tqdm.notebook import tqdm
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| # seed 고정
import random
import torch.backends.cudnn as cudnn
def random_seed(seed_num):
torch.manual_seed(seed_num)
torch.cuda.manual_seed(seed_num)
torch.cuda.manual_seed_all(seed_num)
cudnn.benchmark = False
cudnn.deterministic = True
random.seed(seed_num)
random_seed(42)
|
Data Load
1
2
3
4
5
6
| # Tensor 형태로 변환
mnist_transform = T.Compose([T.ToTensor()])# 이미지를 정규화하고 C, H, W 형식으로 바꿈
download_root = "../data/MNIST_DATASET" # 경로 지정
train_dataset = torchvision.datasets.MNIST(download_root, transform=mnist_transform, train=True, download=True)
test_dataset = torchvision.datasets.MNIST(download_root, transform=mnist_transform, train=False, download=True)
|
1
2
3
| for image, label in train_dataset:
print(image.shape, label) # 여기서 image의 shape은 [C, H, W]로 구성
break
|
torch.Size([1, 28, 28]) 5
1
2
3
4
5
6
| # train/val 분리
total_size = len(train_dataset)
train_num, valid_num = int(total_size * 0.8), int(total_size * 0.2) # 8 : 2 = train : valid
print(f"Train dataset: {train_num}")
print(f"Validation dataset: {valid_num}")
train_dataset, valid_dataset = torch.utils.data.random_split(train_dataset, [train_num, valid_num]) # train - valid set 나누기
|
Train dataset: 48000
Validation dataset: 12000
1
2
3
4
5
6
7
8
9
10
| batch_size = 32
# DataLoader 선언
train_dataloader = DataLoader(train_dataset, batch_size = batch_size, shuffle = True)
valid_dataloader = DataLoader(valid_dataset, batch_size = batch_size, shuffle = False)
test_dataloader = DataLoader(test_dataset, batch_size = batch_size, shuffle = False)
for images, labels in train_dataloader:
print(images.shape, labels.shape)
break
|
torch.Size([32, 1, 28, 28]) torch.Size([32])
1
2
3
4
5
6
7
8
| grid = vutils.make_grid(images, nrow=8) # 각 행마다 8개의 이미지 배치하여 격자로 구성
# 시각화
plt.figure(figsize=(12,12))
plt.imshow(grid.numpy().transpose((1,2,0)))
plt.title("mini batch visualization")
plt.axis('off')
plt.show()
|
Model
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| class DNN(nn.Module):
def __init__(self, hidden_dims, num_classes, dropout_ratio, apply_batchnorm, apply_dropout, apply_activation, set_super):
if set_super:
super().__init__()
self.hidden_dims = hidden_dims
self.layers = nn.ModuleList()
for i in range(len(self.hidden_dims) - 1):
self.layers.append(nn.Linear(self.hidden_dims[i], self.hidden_dims[i+1]))
if apply_batchnorm:
self.layers.append(nn.BatchNorm1d(self.hidden_dims[i+1]))
if apply_activation:
self.layers.append(nn.ReLU())
if apply_dropout:
self.layers.append(nn.Dropout(dropout_ratio))
self.classifier = nn.Linear(self.hidden_dims[-1], num_classes)
self.softmax = nn.LogSoftmax(dim = 1)
def forward(self, x):
"""
Input and Output Summary
Input:
x: [batch_size, 1, 28, 28]
Output:
output: [batch_size, num_classes]
"""
x = x.view(x.shape[0], -1) # [batch_size, 784]
for layer in self.layers:
x = layer(x)
x = self.classifier(x) # [batch_size, 10]
output = self.softmax(x) # [batch_size, 10]
return output
|
1
2
3
4
| hidden_dim = 128
hidden_dims = [784, hidden_dim * 4, hidden_dim * 2, hidden_dim]
model = DNN(hidden_dims = hidden_dims, num_classes = 10, dropout_ratio = 0.2, apply_batchnorm = True, apply_dropout = True, apply_activation = True, set_super = True)
output = model(torch.randn((32, 1, 28, 28)))
|
Weight Initialization
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| # 가중치 초기화
def weight_initialization(model, weight_init_method):
for m in model.modules():
if isinstance(m, nn.Linear):
if weight_init_method == 'gaussian':
nn.init.normal_(m.weight)
elif weight_init_method == 'xavier':
nn.init.xavier_normal_(m.weight)
elif weight_init_method == 'kaiming':
nn.init.kaiming_normal_(m.weight)
elif weight_init_method == 'zeros':
nn.init.zeros_(m.weight)
nn.init.zeros_(m.bias)
return model
|
1
2
3
4
5
6
7
| init_method = 'zeros' # gaussian, xavier, kaiming, zeros
model = weight_initialization(model, init_method)
for m in model.modules():
if isinstance(m, nn.Linear):
print(m.weight.data)
break
|
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
Final Model
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| # 최종 모델 코드
class DNN(nn.Module):
def __init__(self, hidden_dims, num_classes, dropout_ratio, apply_batchnorm, apply_dropout, apply_activation, set_super):
if set_super:
super().__init__()
self.hidden_dims = hidden_dims
self.layers = nn.ModuleList()
for i in range(len(self.hidden_dims) - 1):
self.layers.append(nn.Linear(self.hidden_dims[i], self.hidden_dims[i+1]))
if apply_batchnorm:
self.layers.append(nn.BatchNorm1d(self.hidden_dims[i+1]))
if apply_activation:
self.layers.append(nn.ReLU())
if apply_dropout:
self.layers.append(nn.Dropout(dropout_ratio))
self.classifier = nn.Linear(self.hidden_dims[-1], num_classes)
self.softmax = nn.LogSoftmax(dim = 1)
def forward(self, x):
"""
Input and Output Summary
Input:
x: [batch_size, 1, 28, 28]
Output:
output: [batch_size, num_classes]
"""
x = x.view(x.shape[0], -1) # [batch_size, 784]
for layer in self.layers:
x = layer(x)
x = self.classifier(x) # [batch_size, 10]
output = self.softmax(x) # [batch_size, 10]
return output
def weight_initialization(self, weight_init_method):
for m in self.modules():
if isinstance(m, nn.Linear):
if weight_init_method == 'gaussian':
nn.init.normal_(m.weight)
elif weight_init_method == 'xavier':
nn.init.xavier_normal_(m.weight)
elif weight_init_method == 'kaiming':
nn.init.kaiming_normal_(m.weight)
elif weight_init_method == 'zeros':
nn.init.zeros_(m.weight)
nn.init.zeros_(m.bias)
def count_parameters(self):
return sum(p.numel() for p in self.parameters() if p.requires_grad) # numel()은 텐서의 원소 개수를 반환하는 함수
|
1
2
3
4
| model = DNN(hidden_dims = hidden_dims, num_classes = 10, dropout_ratio = 0.2, apply_batchnorm = True, apply_dropout = True, apply_activation = True, set_super = True)
init_method = 'gaussian' # gaussian, xavier, kaiming, zeros
model.weight_initialization(init_method)
print(f'The model has {model.count_parameters():,} trainable parameters')
|
The model has 569,226 trainable parameters
Loss Function
1
| criterion = nn.NLLLoss()
|
Optimizer
1
2
3
4
5
| lr = 0.001
hidden_dim = 128
hidden_dims = [784, hidden_dim * 4, hidden_dim * 2, hidden_dim]
model = DNN(hidden_dims = hidden_dims, num_classes = 10, dropout_ratio = 0.2, apply_batchnorm = True, apply_dropout = True, apply_activation = True, set_super = True)
optimizer = optim.Adam(model.parameters(), lr = lr)
|
Train
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
| def training(model, dataloader, train_dataset, criterion, optimizer, device, epoch, num_epochs):
model.train() # 모델을 학습 모드로 설정
train_loss = 0.0
train_accuracy = 0
tbar = tqdm(dataloader)
for images, labels in tbar:
images = images.to(device)
labels = labels.to(device)
# 순전파
outputs = model(images)
loss = criterion(outputs, labels)
# 역전파 및 weights 업데이트
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 손실과 정확도 계산
train_loss += loss.item()
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs, 1)
train_accuracy += (predicted == labels).sum().item()
# tqdm의 진행바에 표시될 설명 텍스트를 설정
tbar.set_description(f"Epoch [{epoch+1}/{num_epochs}], Train Loss: {loss.item():.4f}")
# 에폭별 학습 결과 출력
train_loss = train_loss / len(dataloader)
train_accuracy = train_accuracy / len(train_dataset)
return model, train_loss, train_accuracy
def evaluation(model, dataloader, valid_dataset, criterion, device, epoch, num_epochs):
model.eval() # 모델을 평가 모드로 설정
valid_loss = 0.0
valid_accuracy = 0
with torch.no_grad(): # model의 업데이트 막기
tbar = tqdm(dataloader)
for images, labels in tbar:
images = images.to(device)
labels = labels.to(device)
# 순전파
outputs = model(images)
loss = criterion(outputs, labels)
# 손실과 정확도 계산
valid_loss += loss.item()
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs, 1)
valid_accuracy += (predicted == labels).sum().item()
# tqdm의 진행바에 표시될 설명 텍스트를 설정
tbar.set_description(f"Epoch [{epoch+1}/{num_epochs}], Valid Loss: {loss.item():.4f}")
valid_loss = valid_loss / len(dataloader)
valid_accuracy = valid_accuracy / len(valid_dataset)
return model, valid_loss, valid_accuracy
def training_loop(model, train_dataloader, valid_dataloader, criterion, optimizer, device, num_epochs, patience, model_name):
best_valid_loss = float('inf') # 가장 좋은 validation loss를 저장
early_stop_counter = 0 # 카운터
valid_max_accuracy = -1
for epoch in range(num_epochs):
model, train_loss, train_accuracy = training(model, train_dataloader, train_dataset, criterion, optimizer, device, epoch, num_epochs)
model, valid_loss, valid_accuracy = evaluation(model, valid_dataloader, valid_dataset, criterion, device, epoch, num_epochs)
if valid_accuracy > valid_max_accuracy:
valid_max_accuracy = valid_accuracy
# validation loss가 감소하면 모델 저장 및 카운터 리셋
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), f"./model_{model_name}.pt")
early_stop_counter = 0
# validation loss가 증가하거나 같으면 카운터 증가
else:
early_stop_counter += 1
print(f"Epoch [{epoch + 1}/{num_epochs}], Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.4f} Valid Loss: {valid_loss:.4f}, Valid Accuracy: {valid_accuracy:.4f}")
# 조기 종료 카운터가 설정한 patience를 초과하면 학습 종료
if early_stop_counter >= patience:
print("Early stopping")
break
return model, valid_max_accuracy
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| num_epochs = 100
patience = 3
scores = dict()
device = 'cpu' # cpu 설정 (Mac Loacal 진행)
model_name = 'exp1'
init_method = 'kaiming' # gaussian, xavier, kaiming, zeros
model = DNN(hidden_dims = hidden_dims, num_classes = 10, dropout_ratio = 0.2, apply_batchnorm = True, apply_dropout = True, apply_activation = True, set_super = True)
model.weight_initialization(init_method)
model = model.to(device)
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr = lr)
model, valid_max_accuracy = training_loop(model, train_dataloader, valid_dataloader, criterion, optimizer, device, num_epochs, patience, model_name)
scores[model_name] = valid_max_accuracy
|
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [1/100], Train Loss: 0.3178, Train Accuracy: 0.9046 Valid Loss: 0.1260, Valid Accuracy: 0.9615
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [2/100], Train Loss: 0.1622, Train Accuracy: 0.9505 Valid Loss: 0.1015, Valid Accuracy: 0.9678
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [3/100], Train Loss: 0.1314, Train Accuracy: 0.9590 Valid Loss: 0.0897, Valid Accuracy: 0.9729
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [4/100], Train Loss: 0.1116, Train Accuracy: 0.9646 Valid Loss: 0.0775, Valid Accuracy: 0.9753
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [5/100], Train Loss: 0.0981, Train Accuracy: 0.9687 Valid Loss: 0.0673, Valid Accuracy: 0.9797
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [6/100], Train Loss: 0.0857, Train Accuracy: 0.9730 Valid Loss: 0.0696, Valid Accuracy: 0.9787
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [7/100], Train Loss: 0.0772, Train Accuracy: 0.9754 Valid Loss: 0.0697, Valid Accuracy: 0.9784
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [8/100], Train Loss: 0.0674, Train Accuracy: 0.9785 Valid Loss: 0.0634, Valid Accuracy: 0.9823
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [9/100], Train Loss: 0.0609, Train Accuracy: 0.9801 Valid Loss: 0.0631, Valid Accuracy: 0.9809
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [10/100], Train Loss: 0.0586, Train Accuracy: 0.9815 Valid Loss: 0.0669, Valid Accuracy: 0.9803
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [11/100], Train Loss: 0.0544, Train Accuracy: 0.9821 Valid Loss: 0.0630, Valid Accuracy: 0.9831
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [12/100], Train Loss: 0.0554, Train Accuracy: 0.9821 Valid Loss: 0.0662, Valid Accuracy: 0.9807
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [13/100], Train Loss: 0.0461, Train Accuracy: 0.9846 Valid Loss: 0.0597, Valid Accuracy: 0.9825
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [14/100], Train Loss: 0.0431, Train Accuracy: 0.9865 Valid Loss: 0.0610, Valid Accuracy: 0.9823
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [15/100], Train Loss: 0.0442, Train Accuracy: 0.9854 Valid Loss: 0.0617, Valid Accuracy: 0.9816
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [16/100], Train Loss: 0.0393, Train Accuracy: 0.9869 Valid Loss: 0.0616, Valid Accuracy: 0.9828
Early stopping
Batch normalization 제외
1
2
3
4
5
6
7
8
9
10
11
| # Batch normalization을 제외하고 학습 진행
model_name = 'exp2'
init_method = 'kaiming' # gaussian, xavier, kaiming, zeros
model = DNN(hidden_dims = hidden_dims, num_classes = 10, dropout_ratio = 0.2, apply_batchnorm = False, apply_dropout = True, apply_activation = True, set_super = True)
model.weight_initialization(init_method)
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr = lr)
model, valid_max_accuracy = training_loop(model, train_dataloader, valid_dataloader, criterion, optimizer, device, num_epochs, patience, model_name)
scores[model_name] = valid_max_accuracy
|
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [1/100], Train Loss: 0.2839, Train Accuracy: 0.9134 Valid Loss: 0.1365, Valid Accuracy: 0.9599
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [2/100], Train Loss: 0.1316, Train Accuracy: 0.9611 Valid Loss: 0.1105, Valid Accuracy: 0.9678
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [3/100], Train Loss: 0.1022, Train Accuracy: 0.9704 Valid Loss: 0.0892, Valid Accuracy: 0.9738
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [4/100], Train Loss: 0.0855, Train Accuracy: 0.9745 Valid Loss: 0.1010, Valid Accuracy: 0.9711
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [5/100], Train Loss: 0.0743, Train Accuracy: 0.9772 Valid Loss: 0.0817, Valid Accuracy: 0.9782
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [6/100], Train Loss: 0.0636, Train Accuracy: 0.9808 Valid Loss: 0.0889, Valid Accuracy: 0.9778
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [7/100], Train Loss: 0.0575, Train Accuracy: 0.9824 Valid Loss: 0.0840, Valid Accuracy: 0.9780
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [8/100], Train Loss: 0.0523, Train Accuracy: 0.9838 Valid Loss: 0.0817, Valid Accuracy: 0.9785
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [9/100], Train Loss: 0.0465, Train Accuracy: 0.9863 Valid Loss: 0.0806, Valid Accuracy: 0.9801
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [10/100], Train Loss: 0.0450, Train Accuracy: 0.9868 Valid Loss: 0.0900, Valid Accuracy: 0.9786
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [11/100], Train Loss: 0.0421, Train Accuracy: 0.9875 Valid Loss: 0.0995, Valid Accuracy: 0.9778
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [12/100], Train Loss: 0.0393, Train Accuracy: 0.9883 Valid Loss: 0.0861, Valid Accuracy: 0.9792
Early stopping
Dropout을 제외
1
2
3
4
5
6
7
8
9
10
11
| # Dropout을 제외하고 학습 진행
model_name = 'exp3'
init_method = 'kaiming' # gaussian, xavier, kaiming, zeros
model = DNN(hidden_dims = hidden_dims, num_classes = 10, dropout_ratio = 0.2, apply_batchnorm = True, apply_dropout = False, apply_activation = True, set_super = True)
model.weight_initialization(init_method)
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr = lr)
model, valid_max_accuracy = training_loop(model, train_dataloader, valid_dataloader, criterion, optimizer, device, num_epochs, patience, model_name)
scores[model_name] = valid_max_accuracy
|
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [1/100], Train Loss: 0.2168, Train Accuracy: 0.9348 Valid Loss: 0.1049, Valid Accuracy: 0.9667
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [2/100], Train Loss: 0.1039, Train Accuracy: 0.9671 Valid Loss: 0.0888, Valid Accuracy: 0.9737
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [3/100], Train Loss: 0.0786, Train Accuracy: 0.9747 Valid Loss: 0.0842, Valid Accuracy: 0.9748
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [4/100], Train Loss: 0.0646, Train Accuracy: 0.9802 Valid Loss: 0.0718, Valid Accuracy: 0.9777
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [5/100], Train Loss: 0.0522, Train Accuracy: 0.9828 Valid Loss: 0.0698, Valid Accuracy: 0.9792
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [6/100], Train Loss: 0.0422, Train Accuracy: 0.9864 Valid Loss: 0.0738, Valid Accuracy: 0.9783
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [7/100], Train Loss: 0.0381, Train Accuracy: 0.9878 Valid Loss: 0.0729, Valid Accuracy: 0.9799
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [8/100], Train Loss: 0.0373, Train Accuracy: 0.9876 Valid Loss: 0.0803, Valid Accuracy: 0.9790
Early stopping
Activation Function 제외
1
2
3
4
5
6
7
8
9
10
11
| # 활성화 함수(activation function)를 제외하고 학습을 진행합니다.
model_name = 'exp4'
init_method = 'kaiming' # gaussian, xavier, kaiming, zeros
model = DNN(hidden_dims = hidden_dims, num_classes = 10, dropout_ratio = 0.2, apply_batchnorm = True, apply_dropout = True, apply_activation = False, set_super = True)
model.weight_initialization(init_method)
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr = lr)
model, valid_max_accuracy = training_loop(model, train_dataloader, valid_dataloader, criterion, optimizer, device, num_epochs, patience, model_name)
scores[model_name] = valid_max_accuracy
|
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [1/100], Train Loss: 0.4584, Train Accuracy: 0.8641 Valid Loss: 0.3394, Valid Accuracy: 0.9050
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [2/100], Train Loss: 0.3789, Train Accuracy: 0.8898 Valid Loss: 0.3528, Valid Accuracy: 0.8998
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [3/100], Train Loss: 0.3584, Train Accuracy: 0.8947 Valid Loss: 0.3263, Valid Accuracy: 0.9114
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [4/100], Train Loss: 0.3506, Train Accuracy: 0.8959 Valid Loss: 0.3134, Valid Accuracy: 0.9120
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [5/100], Train Loss: 0.3430, Train Accuracy: 0.9010 Valid Loss: 0.3208, Valid Accuracy: 0.9101
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [6/100], Train Loss: 0.3347, Train Accuracy: 0.9025 Valid Loss: 0.3184, Valid Accuracy: 0.9096
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [7/100], Train Loss: 0.3344, Train Accuracy: 0.9024 Valid Loss: 0.3160, Valid Accuracy: 0.9113
Early stopping
Weight Initialization 0으로
1
2
3
4
5
6
7
8
9
10
| model_name = 'exp5'
init_method = 'zeros' # gaussian, xavier, kaiming, zeros
model = DNN(hidden_dims = hidden_dims, num_classes = 10, dropout_ratio = 0.2, apply_batchnorm = True, apply_dropout = True, apply_activation = True, set_super = True)
model.weight_initialization(init_method)
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr = lr)
model, valid_max_accuracy = training_loop(model, train_dataloader, valid_dataloader, criterion, optimizer, device, num_epochs, patience, model_name)
scores[model_name] = valid_max_accuracy
|
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [1/100], Train Loss: 2.3017, Train Accuracy: 0.1118 Valid Loss: 2.3007, Valid Accuracy: 0.1133
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [2/100], Train Loss: 2.3015, Train Accuracy: 0.1121 Valid Loss: 2.3007, Valid Accuracy: 0.1133
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [3/100], Train Loss: 2.3015, Train Accuracy: 0.1121 Valid Loss: 2.3008, Valid Accuracy: 0.1133
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [4/100], Train Loss: 2.3015, Train Accuracy: 0.1121 Valid Loss: 2.3008, Valid Accuracy: 0.1133
0%| | 0/1500 [00:00<?, ?it/s]
0%| | 0/375 [00:00<?, ?it/s]
Epoch [5/100], Train Loss: 2.3015, Train Accuracy: 0.1121 Valid Loss: 2.3007, Valid Accuracy: 0.1133
Early stopping
Inference & Evaluation
1
2
3
4
| # BatchNorm, Dropout을 사용한 모델을 로드
model = DNN(hidden_dims = hidden_dims, num_classes = 10, dropout_ratio = 0.2, apply_batchnorm = True, apply_dropout = True, apply_activation = True, set_super = True)
model.load_state_dict(torch.load("..models/model_exp1.pt"))
model = model.to(device)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| model.eval()
total_labels = []
total_preds = []
total_probs = []
with torch.no_grad():
for images, labels in test_dataloader:
images = images.to(device)
labels = labels
outputs = model(images)
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs.data, 1)
total_preds.extend(predicted.detach().cpu().tolist())
total_labels.extend(labels.tolist())
total_probs.append(outputs.detach().cpu().numpy())
total_preds = np.array(total_preds)
total_labels = np.array(total_labels)
total_probs = np.concatenate(total_probs, axis= 0)
|
1
2
3
4
5
6
7
8
9
10
| # precision, recall, f1를 계산
precision = precision_score(total_labels, total_preds, average='macro')
recall = recall_score(total_labels, total_preds, average='macro')
f1 = f1_score(total_labels, total_preds, average='macro')
# AUC를 계산
# 모델의 출력으로 nn.LogSoftmax 함수가 적용되어 결과물이 출력
total_probs = np.exp(total_probs)
auc = roc_auc_score(total_labels, total_probs, average='macro', multi_class = 'ovr')
print(f'Precision: {precision}, Recall: {recall}, F1 Score: {f1}, AUC: {auc}')
|
Precision: 0.9852826409260971, Recall: 0.9851242188042052, F1 Score: 0.985192726704814, AUC: 0.9997577614547168