[Upstage AI Lab] 6주차 - ML Basic
[Upstage AI Lab] 6주차 - Machine Learning 학습 내용
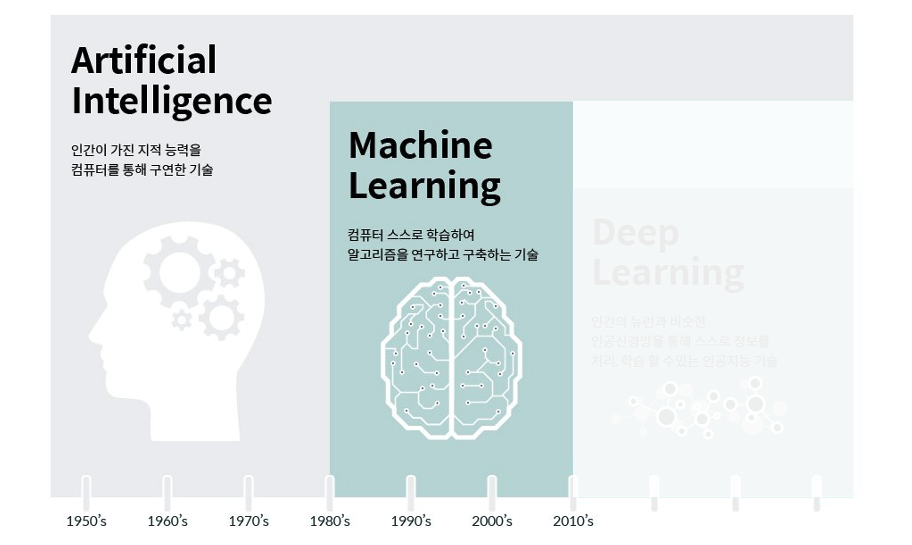
들어가며
이번 주차부터 Machine Learning에 대한 강의가 시작됐다. 이번 포스팅은 해당 강의에서 학습한 머신러닝에 기본적인 개념과 전체적인 프로세스를 다룰 예정이다.
데이터 구조와 속성
1. 정형 & 비정형 데이터
데이터를 형태에 따라 분류하면 정형 데이터와 비정형 데이터로 나뉜다.

정형 데이터
- 명확한 열과 행으로 구성된 구조화된 데이터셋
- 각 열(변수)은 의미를 가지며, 수치나 범주 등으로 정량화됨
- 주로 테이블 형태로 저장됨
- 예시:
- 엑셀 스프레드시트
- CSV 파일
반정형 데이터
- 일부 구조화는 되어 있지만, 완전히 테이블 형태는 아닌 데이터
- 데이터 간의 관계나 구조를 표현하는 태그나 구분자가 포함됨
- 수치나 범주 등의 정량적 정보는 포함될 수 있지만, 고정된 스키마는 없음
- 예시:
- HTML 문서
- JSON, XML 파일
- 로그 파일, 센서 데이터 스트림 등
비정형 데이터
- 열과 행으로 구조화되어 있지 않고, 정성적인 정보를 포함하는 데이터
- 컴퓨터가 직접 해석하기 어려우며 전처리가 중요함
- 예시:
- 텍스트 데이터
- 이미지, 동영상 파일
- 음성, 녹음 파일 등
2. 범주형 vs 수치형
변수는 크게 범주형과 수치형으로 나뉘며, 각 범주에 따라 전처리 방식과 모델의 입력 방식이 달라진다.
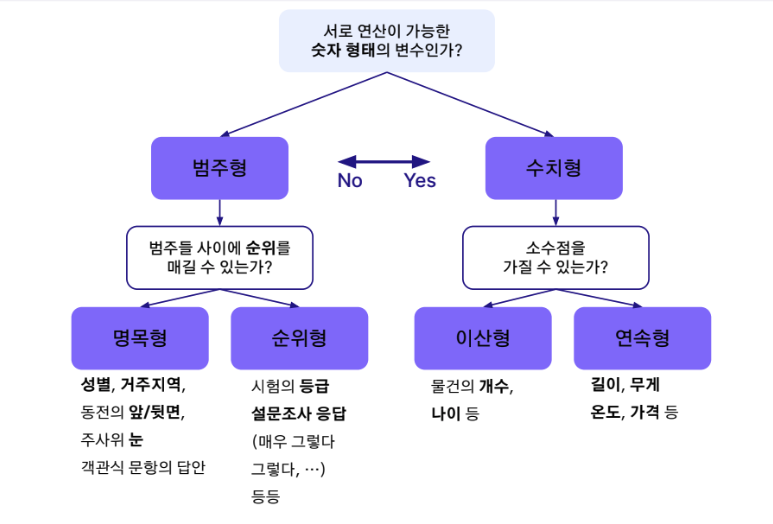
범주형 (Categorical)
- 명목형 (Nominal)
- 순서 없음, 단순 구분
- 예시: 성별, 지역, 눈 색깔, 동전의 앞/뒷면 등
- 순위형 (Ordinal)
- 순서 존재, 수치 간 간격은 불명확
- 예시: 시험 등급, 만족도 설문 (매우 그렇다 ~ 아니다)
수치형 (Numerical)
- 이산형 (Discrete)
- 정수 값만 가짐, 개수를 셀 수 있음
- 예시: 나이, 개수, 횟수 등
- 연속형 (Continuous)
- 소수점 표현 가능, 연속된 수치
- 예시: 키, 무게, 가격, 온도 등
머신러닝 방법론
머신러닝은 학습 방식에 따라 크게 지도 학습, 비지도 학습, 강화 학습으로 나뉘며
각 방식은 데이터에 대한 사전 정보(정답 유무)와 목표하는 학습 목적에 따라 구분된다.
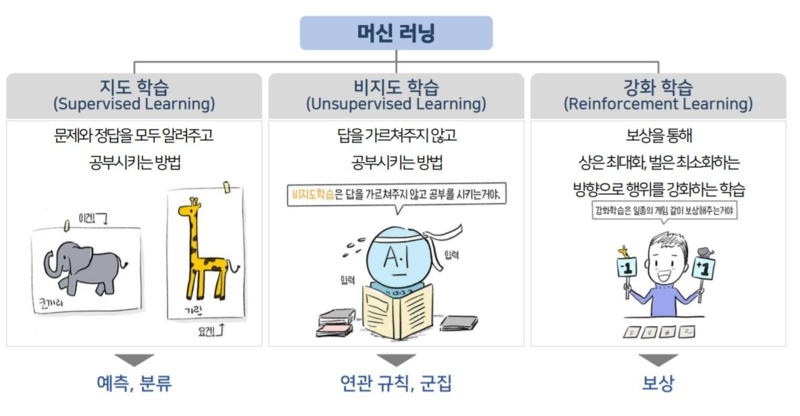
1. 지도 학습 (Supervised Learning)
정답(Label)이 있는 데이터를 기반으로 입력(Input)과 출력(Output)의 매핑 관계를 학습
- 지도학습은 크게 회귀 문제와 분류 문제로 나눌 수 있다.
- 대표적인 목적: 분류, 회귀
- 예시
- 스팸 메일 분류
- 집값 예측
- 이미지 분류 등
회귀 문제 (Regression)
- 연속적인 수치값을 예측하는 문제
- 입력 변수로부터 출력값(실수)을 예측
- 대표 알고리즘: 선형 회귀, 결정 트리 회귀, XGBoost 회귀 등
- 예시
- 내일의 기온 예측
- 주택 가격 예측
- 주식 종가 예측 등
평가 지표
회귀 문제는 예측값과 실제값 사이의 오차를 측정한다.
- MAE (Mean Absolute Error)
- 절댓값 기준의 평균 오차
- 해석이 직관적이지만, 이상치에 덜 민감함
- MSE (Mean Squared Error)
- 제곱 오차의 평균
- 큰 오차에 더 큰 패널티를 주므로 이상치에 민감함
- RMSE (Root Mean Squared Error)
- MSE의 제곱근으로, 단위를 맞춰 직관적인 해석 가능
- R² (결정 계수)
- 예측값이 실제값을 얼마나 잘 설명하는지를 나타냄
- 1에 가까울수록 설명력 우수, 0 이하일 경우 성능 나쁨
분류 문제 (Classification)
- 카테고리(클래스)를 예측하는 문제
- 결과값이 이산형 (Discrete), 즉 정해진 범주 중 하나를 예측
- 대표 알고리즘: 로지스틱 회귀, SVM, 랜덤 포레스트, 신경망 등
- 예시
- 이메일이 스팸인지 여부 판단
- 이미지 속 사물이 고양이인지 개인지 분류
- 질병 진단 (양성/음성 등)
평가 지표
분류 문제에서는 모델이 각 클래스를 얼마나 정확히 예측했는지를 다양한 지표로 측정할 수 있다.
| 지표 | 설명 | 공식 |
|---|---|---|
| 정확도 (Accuracy) | 전체 샘플 중에서 맞춘 비율 | (TP + TN) / (TP + TN + FP + FN) |
| 정밀도 (Precision) | Positive로 예측한 것 중 실제 Positive의 비율 | TP / (TP + FP) |
| 재현율 (Recall) | 실제 Positive 중에서 잘 맞춘 비율 | TP / (TP + FN) |
| F1 Score | 정밀도와 재현율의 조화 평균 | 2 × (Precision × Recall) / (Precision + Recall) |
| ROC-AUC | 임계값 변화에 따른 TPR vs FPR 곡선의 면적 | 0.5~1 사이, 1에 가까울수록 우수 |
혼동 행렬 (Continuous Matrix)
혼동 행렬은 분류 모델의 예측 결과를 실제 값과 비교하여 맞춘/틀린 개수를 시각화하는 표이다.
TP: True Positive / TN: True Negative
FP: False Positive / FN: False Negative
| 예측 Positive | 예측 Negative | |
|---|---|---|
| 실제 Positive | TP | FN |
| 실제 Negative | FP | TN |
2. 비지도 학습 (Unsupervised Learning)
정답이 없는 데이터로부터 패턴을 찾는 학습 방식, 숨겨진 구조, 군집, 연관성 등을 파악
- 대표적인 목적: 군집화, 차원 축소
- 예시
- 고객 세분화 (Clustering)
- 문서 주제 분류
- 이상치 탐지 등
군집화 (Clustering)
- 유사한 특성을 가진 데이터끼리 묶는 작업
- 사전에 정해진 정답 없이, 데이터 간의 거리나 분포를 기반으로 군집을 형성
- 대표 알고리즘: K-Means, DBSCAN, 계층적 군집화 등
- 예시
- 고객을 소비 패턴에 따라 그룹화
- 뉴스 기사를 주제별로 자동 분류
- 이미지 압축을 위한 색상 군집화 등
차원 축소 (Dimensionality Reduction)
- 고차원의 데이터를 보다 적은 수의 주요 특징들로 요약
- 시각화, 연산 효율성 향상, 노이즈 제거 등을 위해 사용
- 대표 알고리즘: PCA, t-SNE, UMAP 등
- 예시
- 고차원 이미지 데이터를 2D로 시각화
- 텍스트 임베딩 데이터를 저차원으로 축소
- 노이즈 제거 및 주요 정보 추출
비지도학습의 평가 방법
비지도학습은 정답(Label)이 없기 때문에 성능 평가 역시 내부 구조나 통계적 특성을 기반으로 수행된다.
하지만 지표 해석은 상대적이며, EDA와 결합한 해석이 중요하다.
군집화 평가 지표
- 실루엣 계수 (Silhouette Score)
- 군집 내 거리(응집도)와 군집 간 거리(분리도)를 비교
- -1 ~ 1 사이의 값을 가지며, 1에 가까울수록 군집 품질이 좋음
- 엘보우 기법 (Elbow Method)
- 군집 수(k)를 정할 때, SSE(오차 제곱합)의 기울기 변화점을 기준으로 선택
- DB Index, Dunn Index 등
- 다양한 군집 간/내 거리 기반의 품질 평가 지표
3. 강화 학습 (Reinforcement Learning)
강화학습은 에이전트(Agent)가 환경(Environment)과 상호작용하며, 행동(Action)에 대한 보상(Reward)을 통해 학습하는 방식이다.
- 지도/비지도 학습과 달리, 데이터셋이 아닌 경험을 통해 학습
- 시행착오를 거치며 보상을 최대화하는 방향으로 학습
- 대표적인 목적: 의사결정 최적화
- 예시
- 게임 에이전트
- 로봇 제어
- 자율주행 등
주요 구성 요소
| 구성 요소 | 설명 |
|---|---|
| 에이전트 (Agent) | 학습을 수행하는 주체 |
| 환경 (Environment) | 에이전트가 행동하는 공간 |
| 상태 (State) | 현재 환경의 정보 |
| 행동 (Action) | 에이전트가 선택할 수 있는 행위 |
| 보상 (Reward) | 행동 결과로 받는 점수 또는 신호 |
| 정책 (Policy) | 상태에서 어떤 행동을 선택할지 결정하는 전략 |
| 가치 함수 (Value Function) | 특정 상태/상태-행동 쌍의 기대 보상 |
추천 시스템과 시계열 데이터
1. 추천 시스템의 세부 유형
추천 시스템은 사용자에게 개인화된 콘텐츠를 제공하기 위한 핵심 기술로, 다양한 필터링 방식과 알고리즘을 기반으로 구성되며 크게 아래 4가지 방식으로 분류된다.
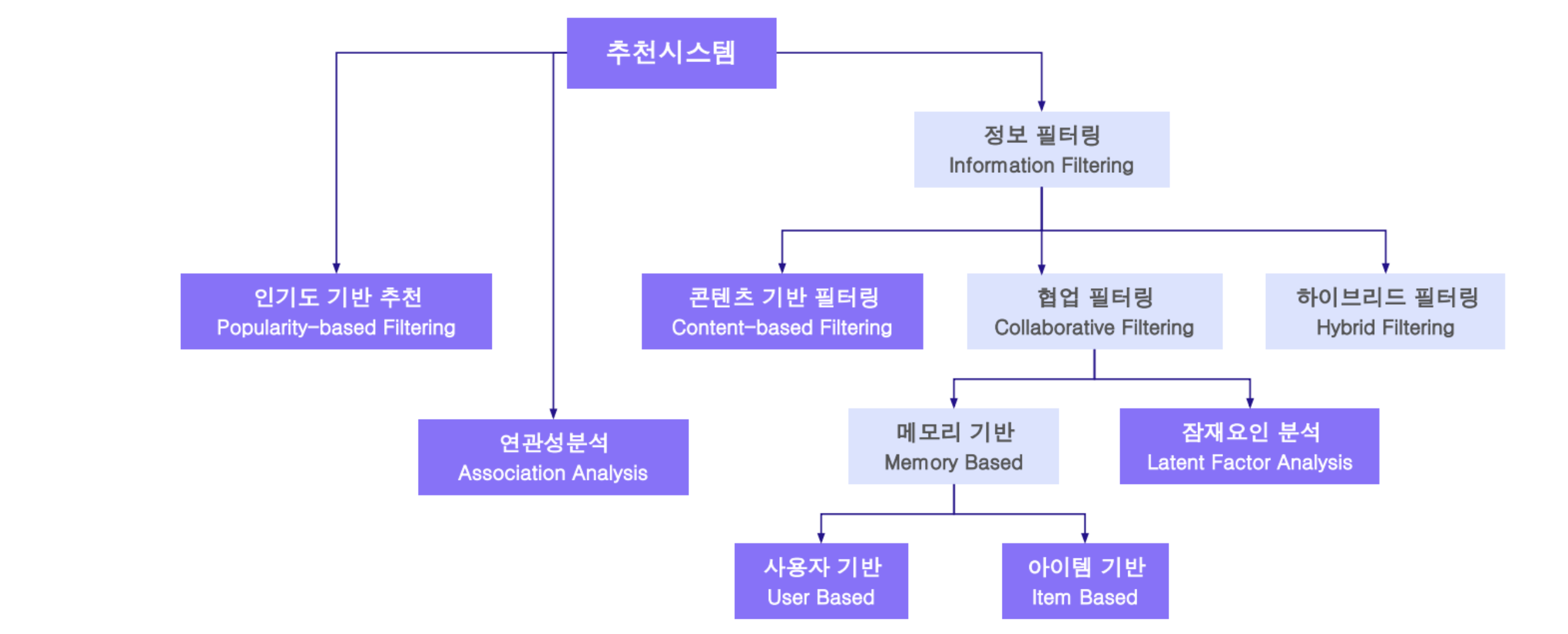
인기 기반 추천 (Popularity-based Filtering)
- 전체 사용자에게 인기 있는 항목을 동일하게 추천
- 개인화는 없지만 간단하고 빠르게 적용 가능
콘텐츠 기반 필터링 (Content-based Filtering)
- 사용자가 선호한 아이템의 속성(콘텐츠)과 유사한 항목을 추천
- 사용자-아이템 특성 간 유사도 분석 기반
협업 필터링 (Collaborative Filtering)
- 다른 사용자들의 행동 패턴을 기반으로 추천
- 유형:
- 메모리 기반
- 사용자 기반(User-based)
- 아이템 기반(Item-based)
- 잠재 요인 기반 (Latent Factor)
- 예: 행렬 분해(Matrix Factorization), SVD, Autoencoder 등
- 메모리 기반
하이브리드 필터링 (Hybrid Filtering)
- 콘텐츠 기반 + 협업 필터링의 장점을 결합
- 성능 향상 및 단점 보완을 위한 혼합 방식
2. 시계열 데이터 처리
시간에 따라 변화하는 데이터를 다루는 시계열 분석은, 미래 예측뿐 아니라 패턴 이해에도 중요한 역할을 함
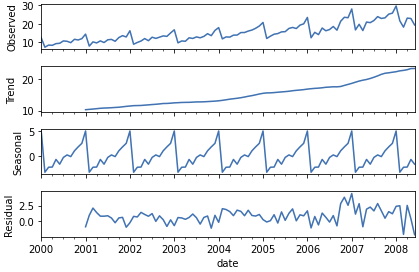
구성 성분 분해 (Decomposition)
- 시계열 데이터를 세 가지 구성 요소로 분해하여 분석
- Trend (추세): 데이터의 장기적인 상승/하강 경향
- Seasonality (계절성): 일정 주기로 반복되는 패턴
- Residual (잔차): 추세/계절성을 제거한 불규칙 요인
이동 평균 (Moving Average)
- 단기 변동을 제거하고 데이터의 전반적 흐름을 파악
- 주로 노이즈 제거, 이상치 완화, 신호 스무딩 등에 사용
- 종류:
- 단순 이동 평균 (SMA)
- 지수 이동 평균 (EMA)
자기회귀 모델 (Auto Regressive, AR)
- 과거 데이터를 기반으로 미래 값을 예측
- 시차(lag) 값을 기반으로 자기 자신의 과거 값을 입력으로 사용
- 시계열 예측 모델의 기초: AR, MA, ARMA, ARIMA 등