[Upstage AI Lab] 4주차 - CS
[Upstage AI Lab] 4주차 - CS 학습 내용

들어가며
이번 주는 컴퓨터 공학(CS)에 대한 내용을 바탕으로, 4주차 학습이 마무리되었다.
이번 포스팅에서는 이러한 학습 내용을 바탕으로 4주차 학습 내용을 요약 및 정리했다.
📑 목차
01. 자료구조
자료구조란? 여러 데이터(값)들의 묶음을 저장하고, 사용하는 방법(접근, 수정, 삭제 등)을 정의한 것
1. 자료구조와 복잡도
1-1. List: []
- 순서가 있는 변경 가능한(mutable) 데이터 묶음
- 다양한 데이터 타입의 데이터를 저장 가능
- 가장 일반적으로 많이 사용
1
2
3
4
5
6
7
8
9
10
11
my_list = [1, 2, 3, 4, 5]
my_list[0] = 100 # 삽입: [100, 2, 3, 4, 5]
my_list.append(6) # 추가: [100, 2, 3, 4, 5, 6]
my_list.remove(3) # 삭제: [100, 2, 4, 5, 6]
my_list.pop() # 마지막 요소 삭제: [100, 2, 4, 5]
my_list.insert(0, 0) # 삽입: [0, 100, 2, 4, 5]
my_list.sort() # 정렬: [0, 2, 4, 5, 100]
my_list.reverse() # 역순: [100, 5, 4, 2, 0]
my_list.count(4) # 4의 개수: 1
my_list.index(4) # 4의 위치: 2
my_list.clear() # 모두 삭제: []
1-2. Tuple: ()
- 순서가 있는 변경 불가능한(immutable)데이터의 묶음.
- 한번 생성되면 내용 변경 불가. 리스트보다 약간 빠르고 메모리 효율적
1
2
my_tuple = (1, 2, 3, 4, 5)
my_tuple[0] = 100 # 오류: 'tuple' object does not support item assignment
- 집합 (Set): {} 또는 set()
- 순서가 없고 중복을 허용하지 않는 데이터의 묶음.
- 합집합, 교집합 등 집합 연산에 유용. 특정 요소의 존재 여부 빠르게 확인 가능.
1
2
3
4
5
6
# %%
my_set = {1, 2, 3, 4, 5}
my_set.add(6) # 추가: {1, 2, 3, 4, 5, 6}
my_set.remove(3) # 삭제: {1, 2, 4, 5, 6}
my_set.pop() # 임의의 요소 삭제: {2, 4, 5, 6}
my_set.clear() # 모두 삭제: set()
1-3. Dictionary: {}
- 키(Key)-값(Value) 쌍으로 이루어진 데이터의 묶음. 순서가 없음 (Python 3.7+ 부터는 입력 순서 유지).
- 키를 통해 값을 빠르게 찾아올 수 있음 (해시 테이블 기반)
1
2
3
4
5
6
my_dict = {'apple': 1, 'banana': 2, 'cherry': 3}
my_dict['apple'] = 100 # 값 변경: {'apple': 100, 'banana': 2, 'cherry': 3}
my_dict['orange'] = 4 # 추가: {'apple': 100, 'banana': 2, 'cherry': 3, 'orange': 4}
my_dict.pop('banana') # 삭제: {'apple': 100, 'cherry': 3, 'orange': 4}
my_dict.popitem() # 임의의 요소 삭제: {'apple': 100, 'cherry': 3}
my_dict.clear() # 모두 삭제: {}
1-4. 추상 자료형 (ADT), 구현 (Implementation)
추상 자료형 (ADT)
- “무엇(What)” 에 초점: 데이터와 그 데이터에 수행될 수 있는 연산들의 명세
- 내부적으로 어떻게 동작하는지는 정의하지 않음
구현 (Implementation)
- “어떻게(How)” 에 초점: ADT에서 정의된 명세를 실제로 구현하는 방식.
- 구체적인 자료구조와 알고리즘을 사용하여 ADT의 연산을 실제로 만듦
관계: ADT는 설계도, 구현은 그 설계도를 바탕으로 실제로 지은 건물
1-5. 알고리즘
알고리즘이란? 어떤 문제를 해결하기 위한 단계적인 절차나 방법
복잡도
- 알고리즘의 성능을 나타내는 척도.
- 입력 데이터의 크기가 증가함에 따라 알고리즘이 얼마나 많은 시간과 공간(메모리) 을 사용하는지를 분석.
시간 복잡도 (Time Complexity)
- 정의: 입력 데이터의 크기(n)에 대해 알고리즘의 실행 시간이 어떻게 변하는지를 나타냄.
- 측정 기준: 실제 실행 시간(초)이 아닌, 연산의 실행 횟수를 기준으로 측정.
- 왜? 실제 시간은 하드웨어, 프로그래밍 언어, 컴파일러 등 환경에 따라 달라지기 때문.
- 목표: 입력 크기 n이 커질수록 실행 시간이 얼마나 빠르게 증가하는가
공간 복잡도 (Space Complexity)
- 정의: 입력 데이터의 크기(n)에 대해 알고리즘이 사용하는 메모리 공간이 어떻게 변하는지를 나타냄.
- 측정 기준: 알고리즘 실행에 필요한 총 메모리 양.
- 고정 공간: 입력 크기와 상관없이 항상 필요한 공간 (코드 저장 공간, 단순 변수 등)
- 가변 공간: 입력 크기에 따라 변하는 공간 (데이터 저장을 위한 동적 할당 메모리, 재귀 호출 스택 등)
- 최근 경향: 메모리 용량이 커지면서 시간 복잡도만큼 중요하게 다루지는 않지만, 대규모 데이터를 다루거나 메모리 제약 환경(임베디드 시스템 등)에서는 여전히 중요.
1-6. Big-O 표기법
복잡도를 표현하는 수학적인 표기법. 입력 크기 n이 무한히 커질 때의 복잡도 증가율(성장률) 을 나타냄.
- 가장 영향력이 큰 항(최고차항) 만 남기고, 계수(상수) 는 무시.
- ex
- 3n² + 5n + 100 → 최고차항은 n². 계수 3 무시. → O(n²)
- log n + n → 최고차항은 n. → O(n)
- 50 (상수 시간) → O(1)
2. 선형 자료구조
데이터 요소들을 순차적인(sequential) 방식으로 저장하는 자료구조.
마치 데이터를 한 줄로 늘어놓은 것과 같은 형태
특징
- 각 요소는 자신의 이전(previous) 요소와 다음(next) 요소 (있다면)를 가진다.
- 데이터 간의 관계가 1:1 인 구조.
종류
- 정적(Static) 선형 자료구조: 크기가 고정됨 (예: 배열)
- 동적(Dynamic) 선형 자료구조: 크기가 변할 수 있음 (예: 연결 리스트, 파이썬 리스트)
- 선형 자료구조: 리스트, 튜플, 문자열, 데크 등
2-1. 시퀀스(Sequence) 자료구조
데이터 요소들이 정해진 순서(order) 를 가지며 나열되어 있는 자료구조.
특징
- 순서 유지: 요소들이 저장된 순서가 그대로 유지됨.
- 인덱싱: 각 요소는 고유한 위치 번호(인덱스)를 가지며, 이를 통해 특정 요소에 직접 접근 가능 my_sequence[i]
- 슬라이싱: 특정 범위의 요소들을 잘라내어 새로운 시퀀스를 만들 수 있음. my_sequence[start:end:step]
대표적인 시퀀스 타입
- 리스트 (List): 변경 가능 (mutable)
- 튜플 (Tuple): 변경 불가능 (immutable)
- 문자열 (String): 변경 불가능 (immutable)
- range() 객체: 특정 범위의 정수 시퀀스 (변경 불가능)
- bytes, bytearray 등
3. Hash Table
해시 테이블 이란? Key를 Value에 매핑하여, 키를 통해 값을 빠르게 찾거나 저장할 수 있는 자료구조
조건
- 결정론적: 동일한 키에 대해서는 항상 동일한 해시 값을 반환해야 함. hash(“apple”)은 언제나 같은 값
- 빠른 계산: 해시 값 계산 자체가 오래 걸리면 안 됨
- 해시 값이 버킷 배열 전체에 최대한 균등하게 분포되어야 함 (충돌 최소화)
파이썬의 hash()
- 파이썬 객체를 정수 해시 값으로 변환해주는 내장 함수
- 불변 객체만 해시 가능. (list, dict, set 등 변경 가능한 객체는 hash() 불가 ❌ - TypeError 발생)
- 왜 불변 객체만? → 객체가 변경되면 해시 값도 달라질 수 있어, 해시 테이블에서 위치를 찾을 수 없게 됨
3-1. 해시 충돌
서로 다른 키(Key) 를 해시 함수에 넣었더니 동일한 해시 값(인덱스) 이 나오는 경우
발생 이유
- 키의 종류는 거의 무한하지만, 해시 값(배열 인덱스)의 개수는 유한하기 때문
- 아무리 좋은 해시 함수라도 충돌을 완벽하게 피할 수는 없다.
3-2. 집합(Set)
순서가 없고, 중복된 요소를 허용하지 않는(unique) 변경 가능한(mutable) 데이터 요소들의 묶음.
특징
- 수학의 집합 개념과 유사 (합집합, 교집합, 차집합 등 연산 가능)
- 요소의 존재 여부를 매우 빠르게 확인 가능 (해시 테이블 기반)
- 요소들이 정렬되어 있지 않음. (입력 순서 유지 안됨 - 단, 내부적으로는 해시값 순서 등으로 관리될 수 있음)
- 요소는 반드시 해시 가능 해야 함 (숫자, 문자열, 튜플 등 리스트, 딕셔너리, 다른 집합은 요소로 가질 수 없음 ❌)
02. DataBase
체계적으로 구조화하여 저장된 데이터의 집합, 효율적인 관리 시스템
1. DB 유형
| 유형 | 핵심 개념 | 주요 특징 | AI 활용 예시 (저장 데이터) | 대표 기술 |
|---|---|---|---|---|
| 관계형 (RDB) | 표(Table) 와 관계 | 정형 데이터, SQL, ACID, 무결성 | 사용자 정보, 모델 메타데이터, 정형 학습 데이터 | MySQL, PostgreSQL, SQLite |
| NoSQL | 관계형 외 다양한 모델 | 유연한 스키마, 확장성, 속도 | 로그, 캐싱, 실시간 데이터, 사용자 프로필 | MongoDB, Redis, Cassandra |
| Vector DB | 벡터 유사도 검색 최적화 | 임베딩 저장, 의미 기반 검색 | 문서/이미지 임베딩 (RAG), 추천 정보, 검색 인덱스 | Milvus, Pinecone, FAISS |
핵심 역할
- RDB: 구조화된 데이터의 정확하고 일관된 관리. (예: 사용자 계정)
- NoSQL: 대규모/비정형 데이터의 유연하고 빠른 처리, 확장성 확보. (예: 서비스 로그)
- Vector DB: AI 임베딩 벡터의 효율적 저장 및 의미 기반 유사도 검색. (예: RAG 문서 검색)
1-1. SQL
Table 생성
1
2
3
4
5
6
7
8
9
10
11
CREATE TABLE IF NOT EXISTS ai_models (
model_id INTEGER PRIMARY KEY,
model_name TEXT NOT NULL,
task TEXT,
framework TEXT);
INSERT INTO ai_models (model_id, model_name, task, framework)
VALUES
(1, 'ResNet', 'Image Classification', 'PyTorch'),
(2, 'BERT', 'Natural Language Processing', 'TensorFlow'),
(3, 'LSTM', 'Sequence Modeling', 'PyTorch');
| Column Name | Data Type | Constraints | |-------------|------------|--------------------| | model_id | INTEGER | PRIMARY KEY | | model_name | TEXT | NOT NULL | | task | TEXT | (nullable) | | framework | TEXT | (nullable) | | model_id | model_name | task | framework | |----------|------------|------------------------------|-------------| | 1 | ResNet | Image Classification | PyTorch | | 2 | BERT | Natural Language Processing | TensorFlow | | 3 | LSTM | Sequence Modeling | PyTorch |
SELECT
- Table에서 원하는 데이터를 가져오는 명령어
SELECT *: Table의 모든 열 데이터를 가져오는 명령어- SELECT column1, column2: 특정 열의 데이터를 가져오는 명령어
1
SELECT * FROM ai models;
| model_id | model_name | task | framework | |----------|------------|------------------------------|-------------| | 1 | ResNet | Image Classification | PyTorch | | 2 | BERT | Natural Language Processing | TensorFlow | | 3 | LSTM | Sequence Modeling | PyTorch |
INSERT
- Talbe에 새로운 데이터 행(row)을 추가
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);
1
2
3
4
INSERT INTO ai_models (model_id, model_name, task, framework)
VALUES
(4, 'GPT-3', 'NLP', 'OpenAI'),
(5, 'Transformer', 'Machine Translation', 'PyTorch');
| model_id | model_name | task | framework | |----------|-------------|------------------------------|-------------| | 1 | ResNet | Image Classification | PyTorch | | 2 | BERT | Natural Language Processing | TensorFlow | | 3 | LSTM | Sequence Modeling | PyTorch | | 4 | GPT-3 | NLP | OpenAI | | 5 | Transformer | Machine Translation | PyTorch |
UPDATE
- Table에 있는 기존 데이터 행의 값을 변경
- 주의:
WHERE절로 변경 대상을 명확히 지정 UPDATE table_name SET column1 = new_value1 WHERE condition;
1
2
3
UPDATE ai_models
SET task = 'Language Modeling'
WHERE model_id = 2;
| model_id | model_name | task | framework | |----------|-------------|----------------------|-------------| | 1 | ResNet | Image Classification | PyTorch | | 2 | BERT | Language Modeling | TensorFlow | | 3 | LSTM | Sequence Modeling | PyTorch | | 4 | GPT-3 | NLP | OpenAI | | 5 | Transformer | Machine Translation | PyTorch |
DELETE
- Table에서 특정 데이터 행을 삭제
- 주의:
WHERE절로 삭제 대상을 명확히 지정 DELETE FROM table_name WHERE condition;
1
DELETE FROM ai_models WHERE model_id = 5;
| model_id | model_name | task | framework | |----------|-------------|----------------------|-------------| | 1 | ResNet | Image Classification | PyTorch | | 2 | BERT | Language Modeling | TensorFlow | | 3 | LSTM | Sequence Modeling | PyTorch | | 4 | GPT-3 | NLP | OpenAI |
WHERE
SELECT, UPDATE, DELETE구문에서 처리할 데이터를 특정 조건으로 제한- 비교 연산자
(=, >, <, >=, <=, !=), 논리 연산자(AND, OR, NOT)사용.
1
2
3
SELECT model_name, task
FROM ai_models
WHERE framework = 'PyTorch';
| model_name | task | |-------------|----------------------| | ResNet | Image Classification | | LSTM | Sequence Modeling | | Transformer | Machine Translation |
COUNT
- 조건 만족 행의 개수를 계산
SELECT COUNT(*) AS alias FROM table WHERE condition;(AS로 별칭 지정)
1
2
3
SELECT COUNT(*) AS tf_count
FROM ai_models
WHERE framework = 'TensorFlow';
| tf_count | |----------| | 1 |
LIMIT
SELECT조회 결과의 개수를 제한- Pandas 의 head() 비슷
SELECT ... FROM ... WHERE ... LIMIT N;
1
2
SELECT * FROM ai_models
LIMIT 2;
| model_id | model_name | task | framework | |----------|-------------|----------------------|-------------| | 1 | ResNet | Image Classification | PyTorch | | 2 | BERT | Language Modeling | TensorFlow |
📊 기본 SQL 명령어 요약
| 명령어 | 주요 기능 | 기본 사용법 (예시) | 비고 |
|---|---|---|---|
SELECT | 데이터 조회 | SELECT col1, col2 FROM tbl; | 가장 기본, 중요 |
INSERT | 데이터 추가 | INSERT INTO tbl (col1) VALUES (val1); | commit() 필요 |
UPDATE | 데이터 수정 | UPDATE tbl SET col1 = val1 WHERE condition; | WHERE, commit() 중요 |
DELETE | 데이터 삭제 | DELETE FROM tbl WHERE condition; | WHERE, commit() 중요 |
WHERE | 조회/수정/삭제 조건 지정 | ... WHERE col1 > 10 AND col2 = 'val'; | 필터링 핵심 |
COUNT() | 조건 만족 행 개수 계산 | SELECT COUNT(*) AS cnt FROM tbl WHERE condition; | 집계 함수 기초 |
LIMIT | 조회 결과 개수 제한 | SELECT * FROM tbl LIMIT N; | 미리보기 등 활용 |
CREATE TABLE | 새로운 테이블 생성 (DDL) | CREATE TABLE tbl (col1 type, col2 type); | 데이터 구조 정의 |
1-2. 관계형 DB 설계 기초
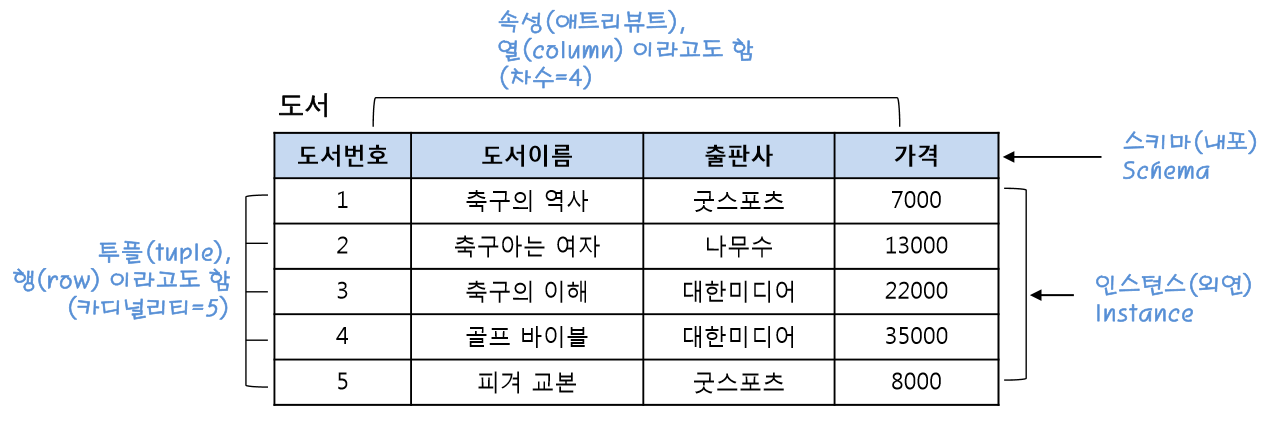
- RDB: 데이터를 표 형식(행과 열)으로 저장하고 관계(연결)를 통해 구조화하는 데이터베이스
- Table: 관계형 데이터베이스에서 데이터를 저장하는 기본 단위. 행과 열로 구성된 2차원 구조
Table 설계
- 데이터를 체계적으로 저장하고 관리하기 위한 청사진
- 데이터 중복을 막고 일관성을 유지하는 기반
- 나중에 데이터를 효율적으로 검색하고 활용하는 데 큰 영향
- AI 앱 스키마 설계 예시 (이미지 분류 모델용 메타데이터)
- 상황: 이미지 분류 AI 모델 학습을 위해 이미지 파일 경로와 해당 이미지의 레이블(정답)을 저장해야 함
- 테이블 설계 (예:
image_metadata테이블):
| Column Name | Data Type | Description | PK? |
|---|---|---|---|
image_id | INTEGER | 이미지 고유 ID | ✅ |
file_path | TEXT | 이미지 파일 저장 경로 | |
label | TEXT | 이미지 정답 레이블 (예: ‘cat’) | |
dataset_source | TEXT | 데이터셋 출처 (예: ‘ImageNet’) |
키(Key)
- Table에서 행을 고유하게 식별하거나 테이블 간의 관계를 맺는 데 사용되는 특별한 열
- 데이터의 무결성(Integrity) 을 지키는 데 핵심적인 역할
- 무결성: 데이터가 정확하고 일관되게 유지되는 것을 의미하며, 잘못된 데이터나 중복된 데이터가 없도록 보장
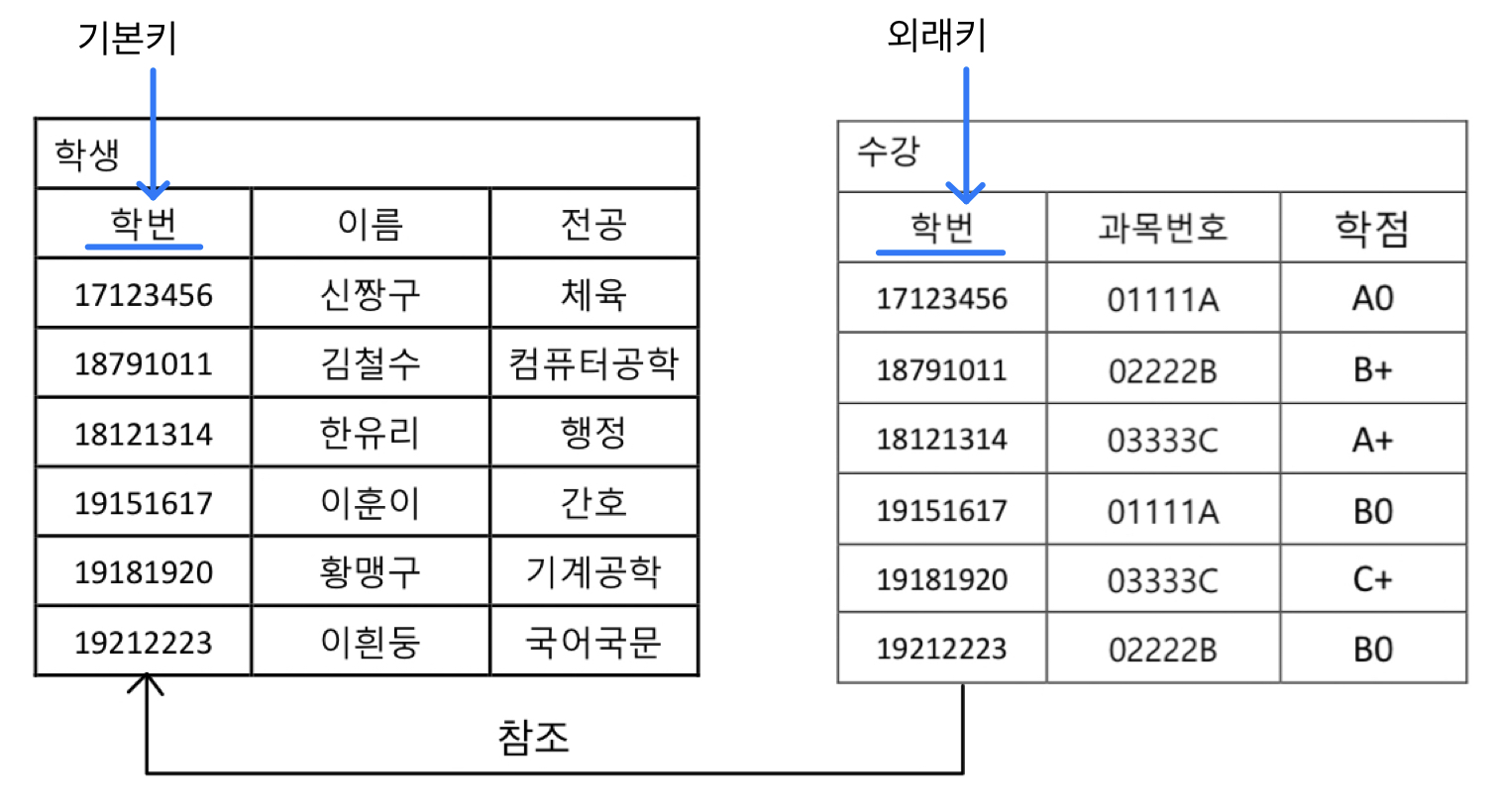
기본 키 (Primary Key, PK)
- 각 행을 고유하게 식별할 수 있는 하나 이상의 열
- 특정 데이터를 정확하게 찾아 수정하거나 삭제하는 기준. 다른 테이블과의 관계 설정 기준
- 특징
- 유일성: PK 값은 테이블 내에서 중복될 수 없음 ❌
- 최소성: 꼭 필요한 최소한의 열로 구성됨.
- NULL 값 불가 (Not Null): PK 값은 비어 있을 수 없음 ❌
외래 키 (Foreign Key, FK)
- 한 테이블의 열이 다른 테이블의 기본 키(PK) 를 참조하는 것. 테이블 간의 관계를 표현
- 여러 테이블에 분산된 정보를 연결하여 의미 있는 데이터 조회 가능 (JOIN의 기반)
- 특징
- 참조하는 테이블(부모 테이블)의 PK에 존재하는 값만 허용 (또는 NULL)
- 참조 무결성을 보장. → 잘못된 데이터 연결 방지
Key 요약
| 종류 | 역할 | 특징 | 예시 (orders 테이블 기준) |
|---|---|---|---|
| 기본 키 (PK) | 행 고유 식별 | 유일성, 최소성, Not Null | order_id (주문 번호) |
| 외래 키 (FK) | 다른 테이블 PK 참조 (관계) | 참조 무결성 | user_id (users 테이블 참조) |
2. 정규화 & ERD
2-1. 정규화 (Normalization)
테이블 설계를 잘 못하면 데이터 중복이 발생하고, 수정/삭제 시 문제가 생길 수 있는데
정규화는 데이터 중복을 최소화하고 일관성 및 무결성을 높이는 방향으로 테이블 구조를 분해하는 과정
과도하면 성능 저하 가능성 (반정규화 고려)
- 목표: 잘 구조화된 관계 스키마(테이블 구조)를 만드는 것
- 핵심 원리: 하나의 데이터는 한 곳에만 저장 (정보 중복 배제)
- 주요 정규형: 단계별 규칙 집합. 차수가 높아질수록 제약 조건이 엄격해짐
- 제1정규형 (1NF - First Normal Form)
- 제2정규형 (2NF - Second Normal Form)
- 제3정규형 (3NF - Third Normal Form)
부분 종속 vs 이행 종속
| 구분 | 정의 | 발생 위치 | 해결 정규형 |
|---|---|---|---|
| 부분 종속 | 복합 기본 키의 일부에만 종속된 속성 | 1NF → 2NF | 2NF |
| 이행 종속 | 기본 키 → 중간 속성 → 종속 속성 | 2NF → 3NF | 3NF |
단계 요약
| 정규형 | 조건 | 목표 |
|---|---|---|
| 1NF | 모든 열의 값이 원자값(Atomic Value) 이어야 함. | 다중값 속성 제거 |
| 2NF | 1NF 만족 + 부분 함수 종속 제거. (PK 전체에 완전 종속) | 부분 종속 속성 분리 |
| 3NF | 2NF 만족 + 이행 함수 종속 제거. (PK 외 일반 열 간 종속 X) | 이행 종속 속성 분리 |
정규화 전 상태(1NF)
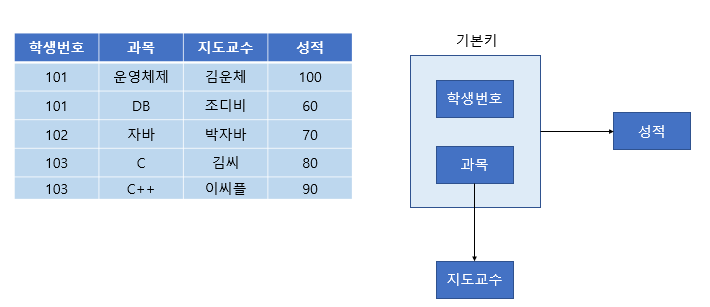
- 정규화 전 Table이며 학생번호, 과목, 지도교수, 성적 정보를 하나의 테이블에 모두 포함하고 있음
- 이 구조는 제1정규형(1NF)은 만족하지만, 여러 문제가 존재
- 문제점
- 과목마다 동일한 지도교수 정보가 반복되며 데이터 중복이 발생
- 지도교수가 변경되면 여러 행을 동시에 수정해야 하며, 수정 이상이 발생할 수 있음
- 새로운 과목을 추가할 때 학생 정보가 없으면 삽입이 어려운 문제 발생
정규화 후 상태(2NF)
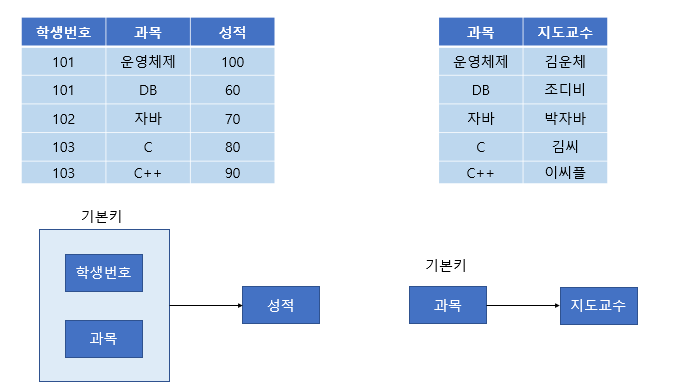
- 정규화 과정을 통해 하나의 Table을 두 개로 분리
학생번호 + 과목 + 성적Table과목 + 지도교수Table- 해결 방식 및 효과
- 과목에 대한 지도교수 정보를 별도 테이블로 분리함으로써 중복을 제거
- 과목만 수정해도 자동으로 해당 교수 정보가 반영되므로 수정 이상을 방지
- 새로운 과목이나 학생 정보를 독립적으로 관리할 수 있어 삽입/삭제 이상도 해소
2-2. ERD
ERD는 데이터베이스 구조를 시각적으로 표현하는 도구
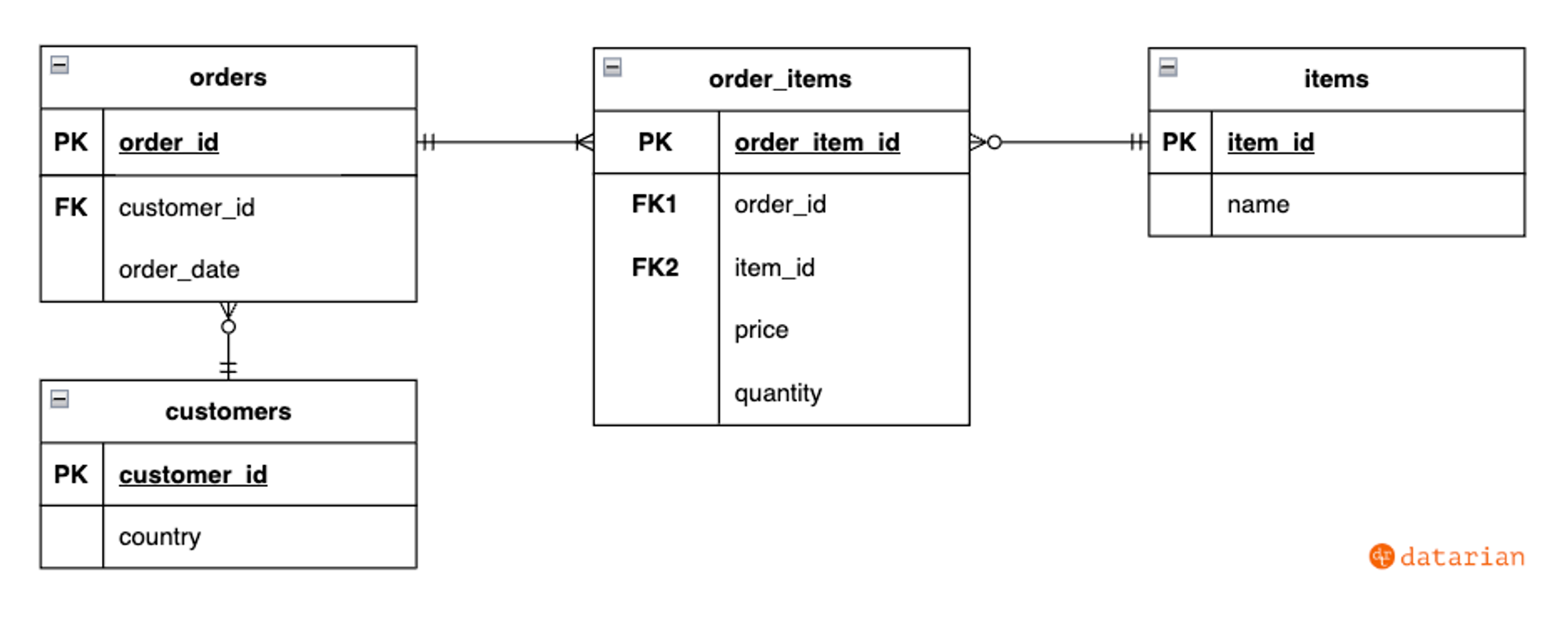
- 구성요소
- 개체 (Entity): 저장할 데이터 대상. 사각형으로 표현. (예: 사용자, 주문)
- 속성 (Attribute): 개체의 특성. 타원형 또는 개체 내부에 표기. (예: 이름, 주문일자)
- 관계 (Relationship): 개체 간의 연결. 마름모 또는 선으로 표현. (예: 사용자가 주문을 한다)
3. 고급 SQL
3-1. JOIN
정규화를 통해 여러 테이블로 분리된 데이터를 필요에 따라 연결하여 함께 조회해야 할 때 사용
두 테이블 간의 관련 있는 열(보통 PK-FK 관계) 을 기준으로 데이터를 합칩
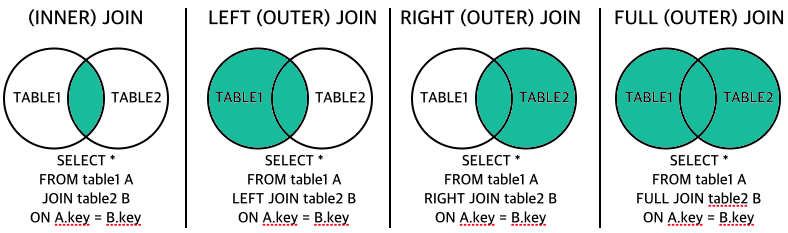 JOIN 종류
JOIN 종류
INNER JOIN
- 두 테이블 모두에 연결 조건이 일치하는 행만 결과에 포함. 가장 흔히 사용
1
2
3
SELECT l.log_id, u.name, l.action
FROM user_logs l
INNER JOIN users u ON l.user_id = u.id;
| log_id | name | action | |--------|--------|----------| | 1 | 민수 | login | | 2 | 지우 | view | | 3 | 민수 | post | | 4 | 철수 | login | | 5 | Alice | view | | 6 | 민수 | logout | | 7 | 지우 | comment | | 8 | Bob | login | | 9 | 준호 | login |
LEFT JOIN
- 왼쪽 테이블의 모든 행을 결과에 포함시키고, 오른쪽 테이블은 연결 조건이 일치하는 경우에만 데이터를 가져옴
- 일치하는 데이터가 없으면 오른쪽 테이블의 열은 NULL로 표시
1
2
3
SELECT l.log_id, u.name, l.action
FROM user_logs l
LEFT JOIN users u ON l.user_id = u.id;
| id | name | log_id | action | |----|--------|--------|----------| | 1 | 민수 | 1 | login | | 1 | 민수 | 6 | logout | | 1 | 민수 | 3 | post | | 2 | 지우 | 7 | comment | | 2 | 지우 | 2 | view | | 3 | 철수 | 4 | login | | 4 | Alice | 5 | view | | 5 | Bob | 8 | login | | 6 | 준호 | 9 | login |
3-2. Subquery
다른 SQL 쿼리 내부에 포함된 또 다른 SELECT 쿼리. 괄호 () 로 감싸서 사용
활용
- WHERE 절에서 비교 값으로 사용 (예: 평균 나이보다 많은 사용자 조회)
- FROM 절에서 임시 테이블처럼 사용 (인라인 뷰 Inline View)
- SELECT 절에서 스칼라 값(단일 값) 조회
- 장점: 복잡한 로직을 단계적으로 표현 가능
- 단점: 너무 복잡하거나 비효율적으로 사용 시 성능 저하. JOIN으로 해결 가능하면 JOIN이 더 나을 수도 있음
1
2
3
4
-- 평균 나이 이상 사용자
SELECT name
FROM users
WHERE age > (SELECT AVG(age) FROM users);
| name | |--------| | 지우 | | Alice | | Bob |
3-3. 집계 함수
여러 행의 데이터를 바탕으로 하나의 요약된 값을 계산하는 함수. SELECT 절이나 HAVING 절에서 주로 사용
📊 주요 집계 함수
| 함수 | 설명 | 예시 |
|---|---|---|
COUNT() | 행의 개수 계산. | COUNT(*) (전체 행), COUNT(column) (NULL 제외) |
SUM() | 숫자 열의 합계 계산. | SUM(price) |
AVG() | 숫자 열의 평균 계산. | AVG(age) |
MAX() | 열의 최대값 계산. | MAX(score) |
MIN() | 열의 최소값 계산. | `MIN(timestamp) |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
-- users 테이블 생성
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT
);
-- 데이터 삽입
INSERT INTO users (id, name, age) VALUES
(1, '민수', 25),
(2, '지우', 28),
(3, '철수', 30),
(4, 'Alice', 27),
(5, 'Bob', 24),
(6, '준호', 29);
SELECT * FROM users;
| id | name | age | |----|--------|-----| | 1 | 민수 | 25 | | 2 | 지우 | 28 | | 3 | 철수 | 30 | | 4 | Alice | 27 | | 5 | Bob | 24 | | 6 | 준호 | 29 |
1
2
3
4
5
6
-- 집계 함수
SELECT
COUNT(name) AS total_users,
AVG(age) AS average_age,
MAX(age) AS max_age
FROM users;
| total_users | average_age | max_age | |-------------|-------------|---------| | 6 | 27.17 | 30 |
4. NoSQL - 데이터베이스
4-1. NoSQL
RDBMS의 한계를 극복하고, 대규모 데이터 처리, 유연한 데이터 모델링, 높은 가용성/확장성 요구에 부응하기 위해 등장
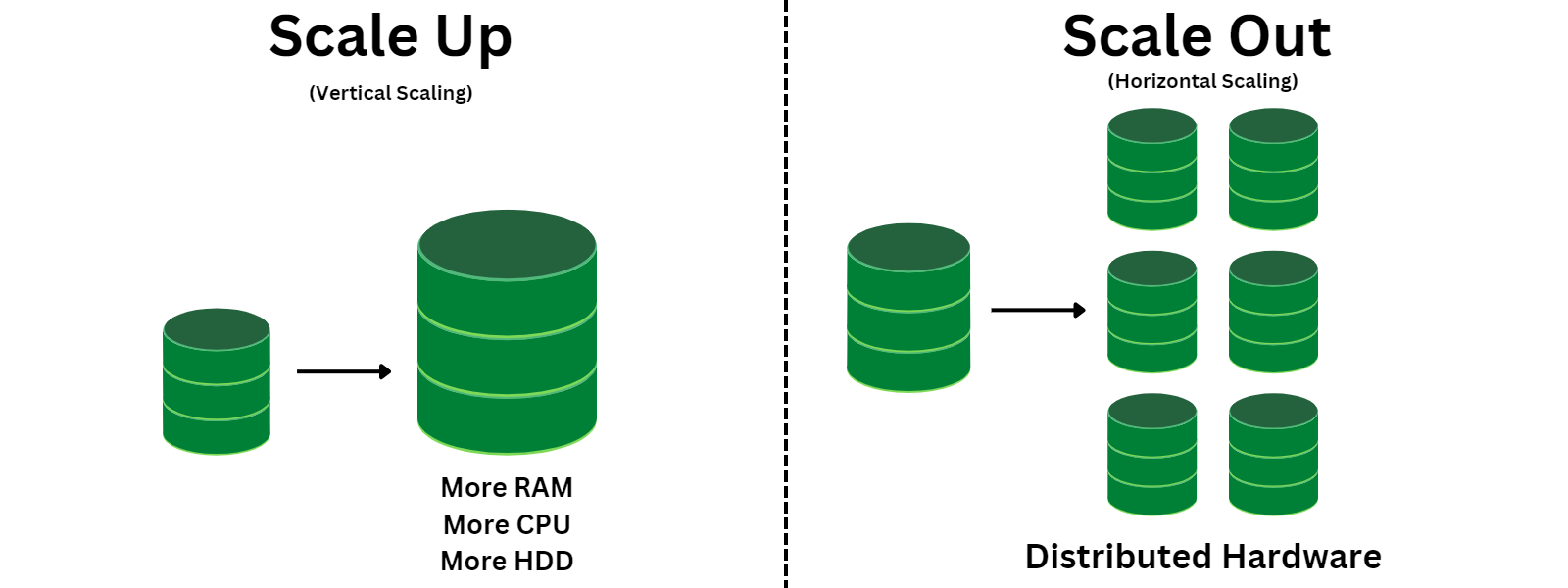
RDBMS의 한계
- 스키마 변경 어려움: 데이터 구조를 바꾸려면 ALTER, TABLE 등 복잡한 작업 필요. 변화 잦은 서비스에는 부담
- 수평적 확장의 어려움: 사용자/데이터 폭증 시 여러 서버로 분산하기가 상대적으로 복잡
- 비정형/반정형 데이터: 로그, 소셜 미디어 글, 센서 데이터 등 형태가 일정하지 않은 데이터 저장/관리에 부적합
NoSQL (Not Only SQL)
SQL만 사용하는 것이 아니다라는 의미. (일부는 SQL 유사 언어 사용)- 반정형/비정형/정형 모두 사용 가능
- DB별 API 또는 고유 쿼리 언어, 스키마 구조 변경이 유연함
4-2. MongoDB
MongoDB는 대표적인 NoSQL 데이터베이스로, 문서 지향(Document-oriented) 저장 방식을 사용
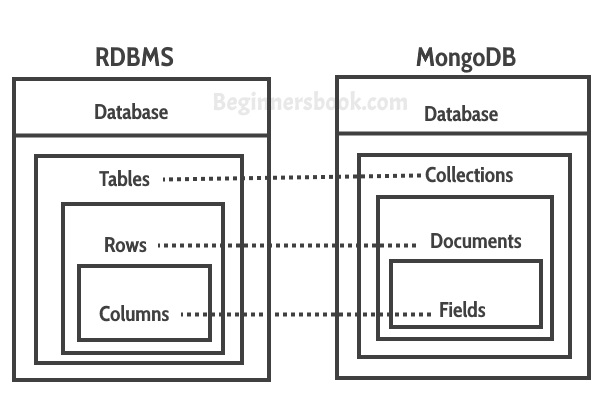
- 관계형 DB처럼 테이블 구조를 강제하지 않음
- SQL 대신 MongoDB 자체 쿼리 언어 사용
- 대용량의 비정형/반정형 데이터 처리에 적합
- 수평적 확장 (Scale-out) 을 통해 고성능 분산 처리 가능
| MongoDB 용어 | RDBMS 용어 (유사 개념) | 설명 |
|---|---|---|
| Database | Database | 데이터베이스. Collection들의 그룹. |
| Collection | Table | 문서(Document) 들의 그룹. 테이블과 유사. |
| Document | Row (행) | MongoDB에서 데이터 저장의 기본 단위. JSON/BSON 형태. 행과 유사하지만 스키마 유연 |
| Field | Column (열) | 문서 내의 Key-Value 쌍에서 Key 부분. 열과 유사. |
| Index | Index | 특정 필드 기반으로 조회 성능 향상. (RDBMS와 유사) |
_id (Field) | Primary Key | 각 Document를 고유하게 식별하는 값. 자동 생성 가능 |
03. 컴퓨터 시스템
1. 컴퓨터 시스템 기본 구성 요소
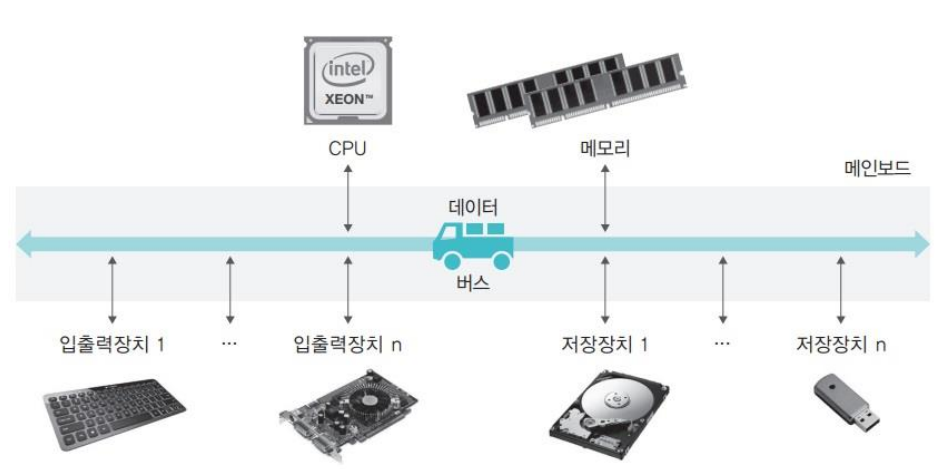 컴퓨터 시스템 기본 구성 요소
컴퓨터 시스템 기본 구성 요소
1-1. CPU
컴퓨터의 두뇌, 프로그램의 명령어를 해석하고 실행하며, 모든 장치를 제어하는 핵심 장치
- ALU: 덧셈, 뺄셈 등 산술 연산과 AND, OR 등 논리 연산을 수행
- 제어 장치: 명령어 해석, 데이터 흐름 제어, 다른 장치들에 작업 지시
- 레지스터: CPU 내부의 매우 빠른 임시 저장 공간. 현재 처리 중인 명령어, 데이터 등을 저장
1-2. 메모리
CPU가 당장 처리해야 할 데이터나 프로그램을 잠시 올려두는 임시 저장 공간
- CPU가 빠르게 접근할 수 있도록 데이터 임시 보관
- 실행 중인 프로그램과 데이터 저장
- CPU보다는 느리지만, 저장장치보다는 훨씬 빠름. 전원이 꺼지면 내용이 사라짐 (휘발성)
1-3. 저장장치
데이터와 프로그램을 영구적으로 보관하는 공간
- 운영체제(OS), 응용 프로그램, 사용자 파일 등 저장
- 전원이 꺼져도 데이터 유지 (비휘발성)
- 메모리보다 속도는 느림, 하지만 용량이 훨씬 크며, HDD(하드 디스크)보다 SSD가 훨씬 빠름
1-4. 폰 노이만 아키텍처 (Von Neumann Architecture)
현대 컴퓨터 구조의 기반이 되는 모델. 수학자 존 폰 노이만이 제안
- 프로그램(명령어) 과 데이터가 동일한 메모리 공간에 저장
- CPU는 메모리에서 명령어를 하나씩 순차적으로 가져와(Fetch) 해석하고(Decode) 실행(Execute)
- 장점: 구조가 간단하고 프로그램 변경이 용이 (메모리 내용만 바꾸면 됨). 범용 컴퓨터 구현 가능
- 단점(폰 노이만 병목 현상)
- CPU가 명령어와 데이터에 접근하기 위해 동일한 버스(통로) 를 사용
- CPU 속도에 비해 메모리 접근 속도가 느려서, CPU가 메모리를 기다리는 시간이 발생하여 전체 성능이 제한될 수 있다.
1-5. CPU vs GPU 와 AI 연산
CPU (Central Processing Unit)
- 구조: 소수의 고성능 코어로 구성. 복잡한 명령어 처리, 빠른 순차 처리, 제어 흐름 처리에 최적화.
- 특징: 직렬 작업, 다양하고 복잡한 작업 처리에 강함. 코어 당 성능 우수.
GPU (Graphics Processing Unit)
- 구조: 수많은 단순한 코어로 구성. 동일한 연산을 대규모 데이터에 대해 병렬로 처리하는 데 최적화.
- 특징: 병렬 처리 능력 탁월. 단순 반복 계산(특히 행렬/벡터 연산)에 매우 효율적.
AI 연산과 GPU
- 딥러닝 학습/추론 과정은 매우 많은 행렬 곱셈 및 벡터 연산을 포함.
- GPU의 수많은 코어는 이러한 연산을 병렬로 동시에 처리하여 CPU보다 수십~수백 배 빠른 속도를 낼 수 있다.
- 예: 이미지 처리 시 각 픽셀에 동일한 필터 연산 적용, 신경망 가중치 업데이트 등.
1-6. 양자화 - 모델 최적화
AI 모델(특히 딥러닝 모델)의 가중치 나 활성화값 을 표현하는 숫자의 정밀도를 낮추는 기술
- 목적
- 모델 크기 감소: 낮은 정밀도 숫자는 더 적은 메모리 공간 차지 → 모델 저장 공간 감소
- 메모리 사용량 감소: 모델 로딩 및 실행 시 필요한 RAM/GPU 메모리 감소
- 추론 속도 향상: 낮은 정밀도 연산은 일반적으로 더 빠르고, 하드웨어 가속 지원 활용 가능
- Trade-off
- 정확도 감소 가능성: 정밀도를 낮추면서 정보 손실이 발생하여 모델 예측 정확도가 약간 떨어질 수 있다.
2. 운영체제(OS)
컴퓨터 하드웨어와 사용자(또는 애플리케이션 소프트웨어) 사이에 위치하여, 컴퓨터 시스템의 자원을 효율적으로 관리하고 사용자에게 편리한 인터페이스를 제공하는 핵심 시스템 소프트웨어
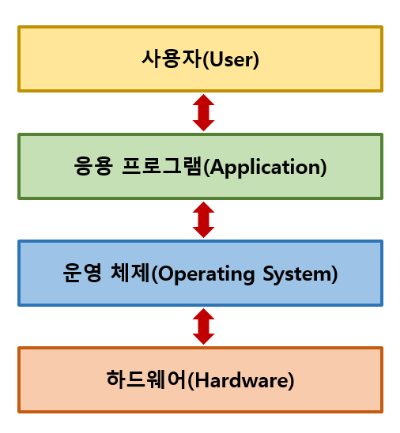
- 역할
- 컴퓨터 시스템의 관리자이자 중재자
- 하드웨어의 복잡성을 숨기고 사용자가 컴퓨터를 쉽게 사용할 수 있도록 도와줌
- 핵심 기능
- 프로세스 관리 (Process Management): 프로그램의 생성, 실행, 종료, 스케줄링, 동기화 등 관리
- 메모리 관리(Memory Management): 프로그램 실행에 필요한 메모리 공간 할당 및 회수, 가상 메모리 관리
- 저장장치 관리: 디스크 공간 관리, 파일 생성/삭제/읽기/쓰기 등 파일 시스템 운영
- 입출력 장치 관리: 키보드, 마우스, 모니터, 프린터 등 주변 장치와의 데이터 입출력 제어
- 네트워킹 (Networking): 네트워크 통신 기능 제공 및 관리
- 보안 (Security): 시스템 접근 제어, 사용자 인증, 자원 보호 등
- 사용자 인터페이스 (User Interface): 사용자가 컴퓨터와 상호작용할 수 있는 환경 제공
2-1. Process & Thread
Process
- 정의: 실행 중인 프로그램, 디스크에 저장된 프로그램 코드가 메모리에 올라와 CPU에 의해 실행되는 동적인 상태
- 특징
- 각 프로세스는 자신만의 독립적인 주소 공간을 할당받음
- 다른 프로세스의 메모리 공간에 직접 접근 불가 (OS의 보호)
- 운영체제로부터 CPU 시간, 메모리, 파일 핸들 등 자원을 할당받는 단위
- 독립된 메모리 때문에, 프로세스끼리 데이터를 주고받으려면 별도의 IPC 메커니즘 필요
- 구성요소
- 코드(Code) 영역: 실행할 프로그램 명령어
- 데이터(Data) 영역: 전역 변수, 정적 변수 등 저장
- 힙(Heap) 영역: 프로그램 실행 중 동적으로 할당되는 메모리 공간 (예: 객체 생성)
- 스택(Stack) 영역: 함수 호출 시 지역 변수, 매개변수, 복귀 주소 등 저장
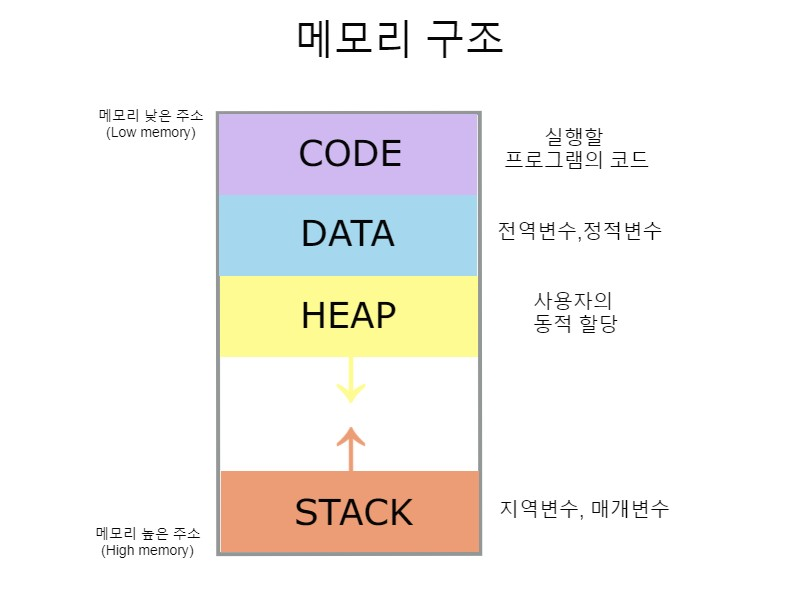
Thread
- 정의: 프로세스 내에서 실행되는 실행 흐름의 가장 작은 단위. “경량 프로세스“라고도 불림
- 특징
- 프로세스 자원 공유: 스레드는 자신이 속한 프로세스의 코드, 데이터, 힙 영역 메모리를 다른 스레드들과 공유
- 독립적인 실행 흐름: 각 스레드는 자신만의 독립적인 스택(Stack) 영역과 레지스터 값을 가짐
- 스레드 간 통신: 같은 프로세스 내 스레드들은 메모리를 공유하므로, 데이터를 직접 주고받기 쉬움
- 생성/관리 오버헤드 적음: 프로세스 생성보다 스레드 생성이 훨씬 가볍고 빠름
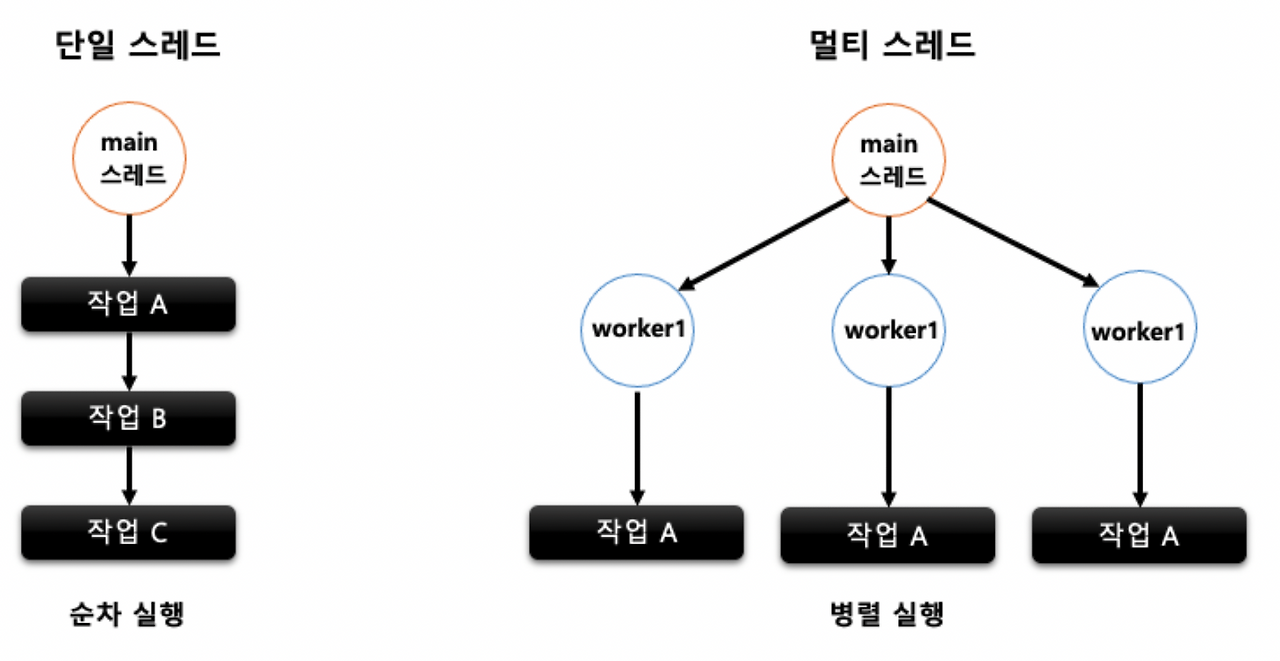
프로세스 vs 스레드 요약
| 구분 | 프로세스 (Process) | 스레드 (Thread) |
|---|---|---|
| 정의 | 실행 중인 프로그램 | 프로세스 내 실행 흐름 단위 |
| 메모리 | 독립적 공간 할당 | 프로세스 자원 공유 (스택/레지스터는 독립) |
| 자원 공유 | 어려움 (IPC 필요) | 쉬움 (메모리 공유) |
| 생성/관리 | 오버헤드 큼 | 오버헤드 작음 |
| 안정성 | 한 프로세스 오류가 다른 프로세스에 영향 적음 | 한 스레드 오류가 프로세스 전체에 영향 가능 |
| 활용 | 독립적 작업, 병렬 처리 (멀티코어) | 동시성 작업, 자원 공유 작업, 응답성 향상 |
2-2. Pyhon GIL
GIL이란 CPython의 잠금 한 번에 딱 한 스레드만 파이썬 코드를 실행하게 하는 것
메모리 관리(참조 카운팅)를 쉽게 스레드로부터 보호하기 위함으로 사용
- 핵심 영향 (threading 사용 시):
- I/O 작업 (대기 많음): 스레드가 대기할 때 다른 스레드가 일할 수 있어 성능 향상 (동시성)
- CPU 작업 (계산 많음): 여러 스레드도 결국 순서대로 실행되어 병렬 처리 효과 거의 없음
- CPU 병렬 처리 해결책:
- ✅ 표준/안정적: multiprocessing 사용. 각 프로세스가 독립된 GIL을 가져 진짜 병렬 처리 가능
- 실험적 (Python 3.13+): Free-threaded 모드. GIL을 끄는 옵션으로 threading 병렬 가능성 제시
- ⚠️ 중요 (Free-threaded):
- 아직 매우 실험적인 기능 (버그, 성능 저하, 호환성 문제 가능)
- 기본 파이썬은 여전히 GIL이 활성화되어 있음
- 실제 개발 환경에서는 딥러닝/백엔드 프레임워크는 멀티프로세싱/멀티스레딩 기능들을 내장하고 있다.
04. Network
네트워크란 두 대 이상의 컴퓨터 또는 장치들이 서로 연결되어 정보(데이터)를 주고받을 수 있는 상태
- 컴퓨터: 데스크톱, 노트북, 스마트폰, 서버 등
- 장치: 프린터, 스캐너, 스마트 TV, IoT 기기 등
구성요소
| 구성요소 | 역할 |
|---|---|
| 🔌 기기(Host) | 컴퓨터, 스마트폰, 프린터 등 |
| 📡 통신 장비 | 공유기, 스위치, 라우터 등 데이터가 올바른 목적지로 가도록 안내 |
| 🔁 전송 매체 | 유선(케이블), 무선(Wi-Fi, Bluetooth 등) |
| 📬 프로토콜 | 서로 “어떻게 대화할지” 약속한 규칙 (ex. TCP/IP) |
1. IP 주소

- 네트워크에 연결된 각 장치를 식별하기 위한 논리적인 주소. 숫자로 구성
- 인터넷 세상의 집 주소와 같음. 데이터가 정확한 목적지를 찾아가도록 함
- 특징
- 고유성: 일반적으로 특정 네트워크 내에서는 중복되지 않음 (하지만 상황에 따라 변할 수 있음 - 유동 IP)
- 변경 가능: 네트워크 환경이 바뀌거나, ISP(인터넷 서비스 제공자)가 변경하면 IP 주소도 바뀔 수 있다.
- 종류
- 공인 IP (Public IP): 전 세계에서 유일한 IP 주소. 인터넷 상에서 나를 식별. (ISP가 제공)
- 사설 IP (Private IP): 특정 내부 네트워크(집, 회사) 안에서만 사용되는 IP 주소
- 외부 인터넷에서는 직접 접근 불가
1-1. DNS
- 정의: 도메인 이름을 IP 주소로 변환해주는 것이 DNS
- ex: 172.217.160.142 -> www.google.com
- DNS 없이는 IP 주소를 직접 외워야 하므로 인터넷 사용이 매우 불편
1-2. Mac 주소
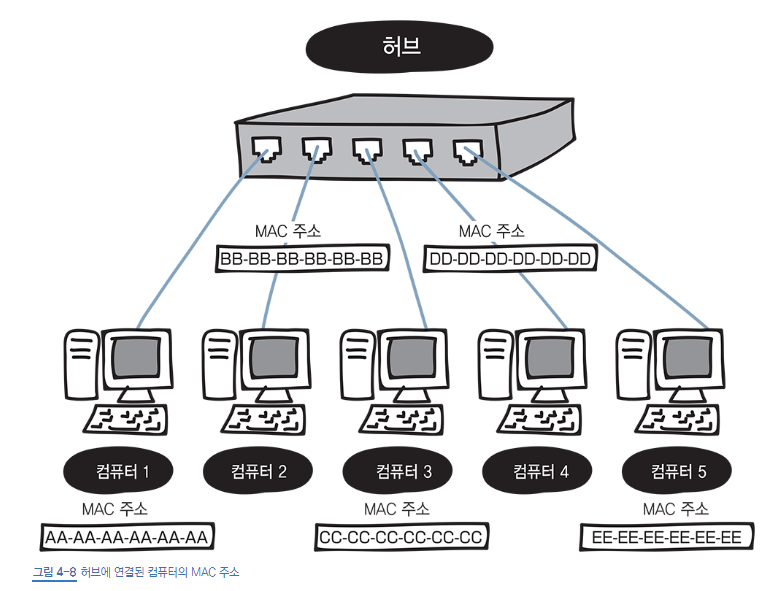
- 정의: 네트워크 인터페이스 카드(NIC, 랜카드)에 부여된 물리적인 고유 식별 번호. 하드웨어 자체의 주소
- 특징
- 전 세계적으로 고유: 제조사에서 할당하며, 이론적으로는 중복되지 않음
- 불변성: 해당 하드웨어가 바뀌지 않는 한 변하지 않음
- 콜론(:)이나 하이폰(-)으로 구분된 6개의 16진수 덩어리
- IP 주소와의 관계
- IP 주소: 최종 목적지 (집 주소) - 네트워크 상에서 장치를 찾을 때 사용
- MAC 주소: 실제 배달 대상 (집 안의 특정 사람) - 같은 네트워크 내에서 특정 하드웨어를 찾을 때 사용
- 비유: 아파트 101동 501호 (IP 주소)에 사는 홍길동 (MAC 주소) 에게 편지 전달
2. 클라이언트-서버 TCP/IP 및 HTTP
2-1. OSI 7계층 vs TCP/IP 4계층
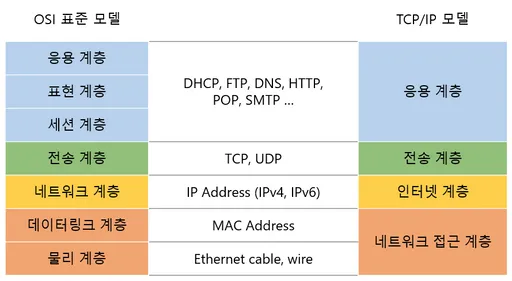
OSI 7계층 모델
- 국제표준화기구(ISO)에서 개발한 참조 모델
- 네트워크 통신 과정을 7개의 상세한 단계로 나뉨 (물리, 데이터 링크, 네트워크, 전송, 세션, 표현, 응용)
- 실제 구현에서는 너무 복잡하고 비효율적인 면이 있어 널리 사용되지는 않는다.
- 비유: 아주 상세하게 모든 부품과 조립 순서가 적힌 이론적인 설계도
TCP/IP 4계층 모델
- 현재 인터넷 표준 모델로, 실제 인터넷 통신에서 사용
- OSI 모델을 더 실용적으로 그룹화하여 4개의 계층으로 단순화 (네트워크 인터페이스, 인터넷, 전송, 응용)
- 비유: 실제 건물을 지을 때 사용하는 실용적인 건축 도면
비교
| 특징 | OSI 7계층 | TCP/IP 4계층 |
|---|---|---|
| 목적 | 참조 모델, 개념 학습 | 실제 구현, 인터넷 표준 |
| 계층 수 | 7개 (세분화) | 4개 (실용적 그룹화) |
| 사용 현황 | 이론적, 교육용 | 실제 인터넷 표준 |
| 개발 주체 | ISO (국제표준화기구) | 미국 국방부 (ARPANET) |
| 주요 초점 | 각 계층의 명확한 역할 정의 | 프로토콜 기반의 실제 동작 |
2-2. 포트(Port)
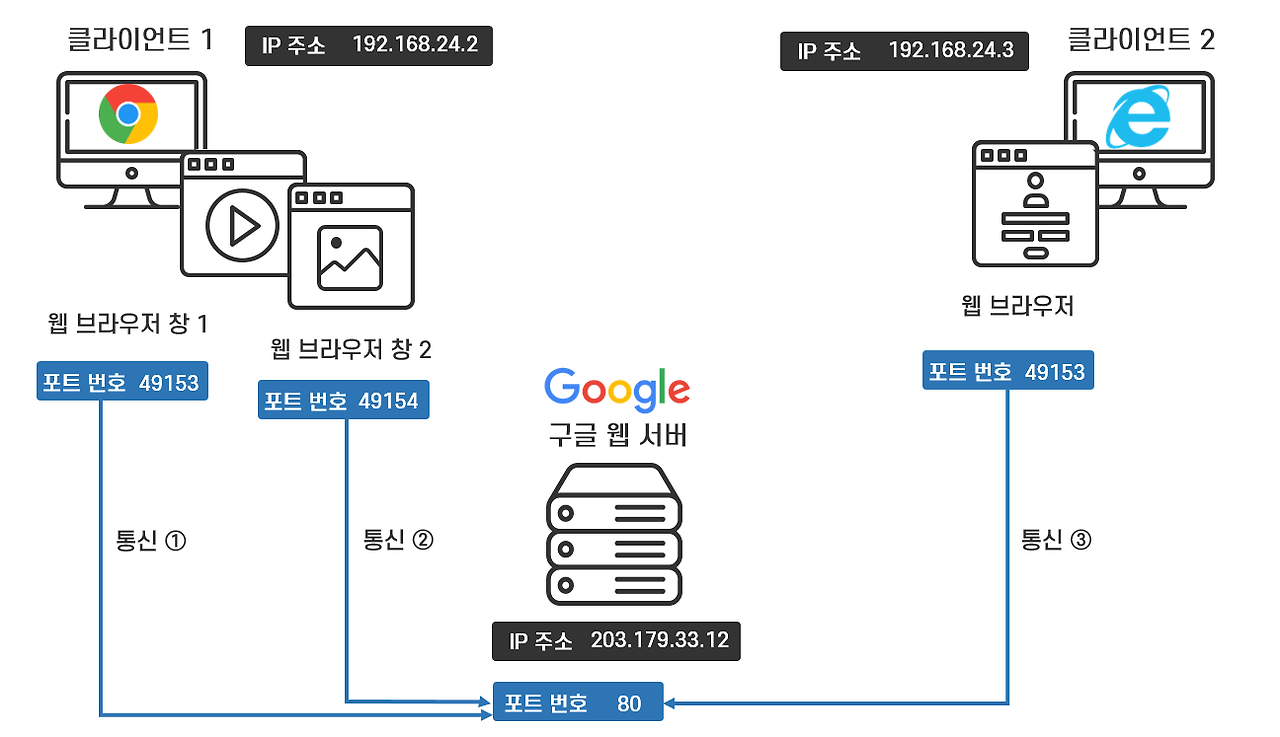
- 역할
- 하나의 IP 주소 안에서 여러 프로세스(프로그램)를 구분해주는 논리적인 문
- 네트워크 통신에서 ‘문’ 역할: 어떤 프로세스와 연결할지 정해줌
- 예: 같은 컴퓨터에서 웹 서버(80번)와 메일 서버(25번)를 동시에 운영 가능
특징
- 컴퓨터에서 프로세스는 네트워크 서비스를 제공할 때 특정 포트를 사용
- 한 포트는 동시에 하나의 프로세스만 사용 가능
- 예: 80번 포트는 웹 서버(Apache, Nginx 등)가 사용 중이라면, 다른 앱은 사용 불가