[Upstage AI Lab] 10주차 - Workflow
[Upstage AI Lab] 10주차 - MLOps Workflow Tools(Airflow, Kubeflow) 학습 내용
[Upstage AI Lab] 10주차 - Workflow
들어가며
이번 글에서는 MLOps Workflow를 구성하는 핵심 도구들을 소개한다.
대표적인 Airflow와 Kubeflow를 중심으로, ML 파이프라인 자동화 개념과 실습 예제를 함께 다룬다.
Airflow
1. Airflow 란?
Airflow는 머신러닝 파이프라인을 구성하고 실행하는 Workflow Management도구다.
DAG 구조로 각 작업을 정의하며, 시간 또는 이벤트 기반으로 자동 실행할 수 있다.
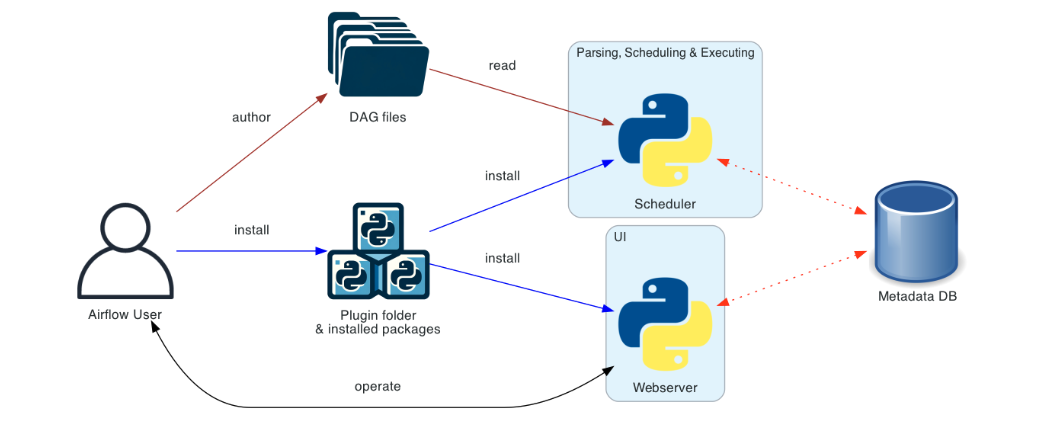
2. Workflow Management 란?
- 비즈니스나 기술 프로세스의 설계, 실행, 모니터링 및 최적화를 포함하는 전체적인 접근 방식
- 💡 MLOps에서 Workflow Management는 ML 파이프라인의 단계를 자동화하고 체계적으로 관리하는 방식
3. 구성 요소
- DAG (Directed Acyclic Graph): 워크플로우의 구조, 실행 순서를 정의
- Scheduler: DAG을 파싱하고 실행 시점에 따라 Task 실행 요청
- Webserver: UI를 통해 DAG 실행 현황을 실시간 확인
- Metadata DB: 실행 기록, Task 상태 등을 저장
- Executor (Worker): 실제 Task를 실행하는 실행자
4. Airflow의 DAG
DAG 정의
- DAG Airflow에서 워크플로우를 정의하는 주요 구성 요소
- 방향성을 가지는 비순환 그래프이며 여러 Task들과 의존성을 나타냄
DAG 구성 요소
- Operator: Airflow에서 작업을 수행하는 객체, 다양한 유형의 Operator가 있으며, 각 각 특정 작업을 수행
- Task: Operator의 인스턴스로, DAG 내에서 하나의 작업을 의미
- Task Instance: 특정 시점에 실행되는 Task의 인스턴스
- Workflow: 전체 파이프라인 흐름을 의미하며, 여러 DAG로 구성될 수 있음
DAG 주의 사항
- 의존성 순한: DAG에서는 의존성을 가질 수 없음. 어떤 작업도 직접/간접적으로 자기 자신에게 의존할 수 없음
- (즉 DAG는 한 방향으로만 흐르는 작업 흐름 을 정의해야 하며, 작업이 되돌아오는 구조는 허용 ❌)
- 스케줄링:
start_date와schedule_interval을 적절히 설정하여 작업이 예상대로 실행되도록 해야한다. - 오류 처리: 각 Task는 실패할 수 있으므로, Error처리 로직 고려
5. 실습 예제
아래 코드는 Docker 환경에서 Airflow를 실행해 ML 파이프라인을 자동화하는 예제다.
각 작업은PythonOperator로 구성되며, DAG 구조를 통해 순차 실행된다.
5-1. 환경 구축
- 1. Dockerfile 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# language identifier: Dockerfile
FROM python:3.8-slim
ENV AIRFLOW_HOME=/usr/local/airflow
RUN apt-get update && \
apt-get install -y gcc libc-dev vim && \
rm -rf /var/lib/apt/lists/*
RUN pip install apache-airflow
RUN mkdir -p $AIRFLOW_HOME
WORKDIR $AIRFLOW_HOME
RUN airflow db init
EXPOSE 8080
CMD airflow webserver -p 8080 & airflow scheduler
- 2. Dag.py 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 기본적인 구조
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'airflow',
'start_date': datetime(2021, 1, 1),
# 기타 필요한 기본 인자들...
}
dag = DAG(
'example_dag',
default_args=default_args,
description='An example DAG',
schedule_interval=timedelta(days=1),
)
# Task에서 수행할 작업
def example_task():
pass
# Task 정의
def task1_function():
pass
def task2_function():
pass
task1 = PythonOperator(
task_id='task1',
python_callable=task1_function,
dag=dag,
)
task2 = PythonOperator(
task_id='task2',
python_callable=task2_function,
dag=dag,
)
# task1이 task2보다 먼저 실행되도록 설정
task1 >> task2
- 3. Docker image build
1
docker build -t my_airflow_image .
- 4. Docker 컨테이너 실행 및 확인
1
2
3
4
5
6
# 로컬의 dags 폴더를 컨테이너와 연동하여 Airflow 컨테이너 실행
docker run --name airflow_container \
-d \
-p 8080:8080 \
-v "$(pwd)/dags:/usr/local/airflow/dags" \
my_airflow_image:latest
- 5. 컨테이너 내부 접속
1
docker exec -it <CONTAINER_ID> bash # 예: docker exec -it <Docker ID>
- 6. 계정 생성
1
2
3
4
5
6
7
airflow users create \
--username <USERNAME> \
--firstname <FIRSTNAME> \
--lastname <LASTNAME> \
--role Admin \
--email <EMAIL_ADDRESS> \
--password <PASSWORD>
- 7.
http://localhost:8080/접속 및 로그인
 접속
접속
 로그인
로그인
5-2. 기본 DAG 구조
- Test DAG 생성
1
2
cd dags
vi dag_file_name.py # dag 파일 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
# DAG 기본 설정
default_args = {
'owner': 'ryan',
'depends_on_past': False,
'start_date': datetime(2025, 5, 29),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'hello_airflow_dag',
default_args=default_args,
description="our first time practice airflow",
schedule_interval=timedelta(days=1),
)
# 실행할 함수 정의
def print_word(word):
print(word) # test
# 동적 태스크 생성
sentence = "hello airflow dag. test task star"
prev_task = None
for i, word in enumerate(sentence.split()):
task = PythonOperator(
task_id=f'print_world_{i}',
python_callable=print_word,
op_kwargs={'word': word},
dag=dag,
)
if prev_task:
prev_task >> task
prev_task = task
5-3. ML Development DAG
- 1. ML 파이프라인 DAG 생성
1
2
# dags 경로안에서 작업
vi ml_development_dags.py # 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
# # Iris 데이터를 기반으로 RandomForest vs. GradientBoosting 모델의 성능을 비교하는 Airflow DAG
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import accuracy_score
from airflow.models import Variable
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2025, 5, 29),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'model_training_selection',
default_args=default_args,
description='A simple DAG for model training and selection',
schedule_interval=timedelta(days=1),
)
def feature_engineering(**kwargs):
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.Series(iris.target)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# XCom을 사용하여 데이터 저장
ti = kwargs['ti']
ti.xcom_push(key='X_train', value=X_train.to_json())
ti.xcom_push(key='X_test', value=X_test.to_json())
ti.xcom_push(key='y_train', value=y_train.to_json(orient='records'))
ti.xcom_push(key='y_test', value=y_test.to_json(orient='records'))
def train_model(model_name, **kwargs):
ti = kwargs['ti']
X_train = pd.read_json(ti.xcom_pull(key='X_train', task_ids='feature_engineering'))
X_test = pd.read_json(ti.xcom_pull(key='X_test', task_ids='feature_engineering'))
y_train = pd.read_json(ti.xcom_pull(key='y_train', task_ids='feature_engineering'), typ='series')
y_test = pd.read_json(ti.xcom_pull(key='y_test', task_ids='feature_engineering'), typ='series')
if model_name == 'RandomForest':
model = RandomForestClassifier()
elif model_name == 'GradientBoosting':
model = GradientBoostingClassifier()
else:
raise ValueError("Unsupported model: " + model_name)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
performance = accuracy_score(y_test, predictions)
ti.xcom_push(key=f'performance_{model_name}', value=performance)
def select_best_model(**kwargs):
ti = kwargs['ti']
rf_performance = ti.xcom_pull(key='performance_RandomForest', task_ids='train_rf')
gb_performance = ti.xcom_pull(key='performance_GradientBoosting', task_ids='train_gb')
best_model = 'RandomForest' if rf_performance > gb_performance else 'GradientBoosting'
print(f"Best model is {best_model} with performance {max(rf_performance, gb_performance)}")
return best_model
with dag:
t1 = PythonOperator(
task_id='feature_engineering',
python_callable=feature_engineering,
)
t2 = PythonOperator(
task_id='train_rf',
python_callable=train_model,
op_kwargs={'model_name': 'RandomForest'},
provide_context=True,
)
t3 = PythonOperator(
task_id='train_gb',
python_callable=train_model,
op_kwargs={'model_name': 'GradientBoosting'},
provide_context=True,
)
t4 = PythonOperator(
task_id='select_best_model',
python_callable=select_best_model,
provide_context=True,
)
t1 >> [t2, t3] >> t4
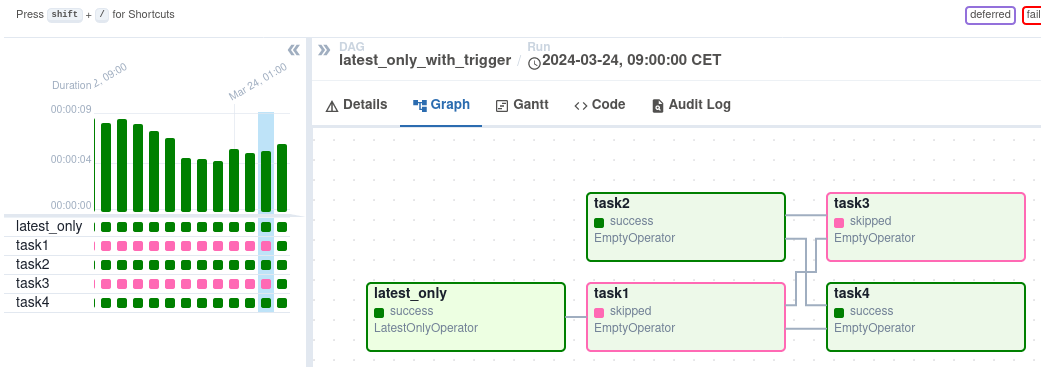
- 2. 결과 확인
아래는 실제로 Airflow에서 DAG를 실행한 결과이다.
DAG는 순차적으로 실행되며, 초록색 블록들은 각 Task의 실행 성공(success)을 의미한다.
전체 소스 코드는 GitHub에서 확인할 수 있다.
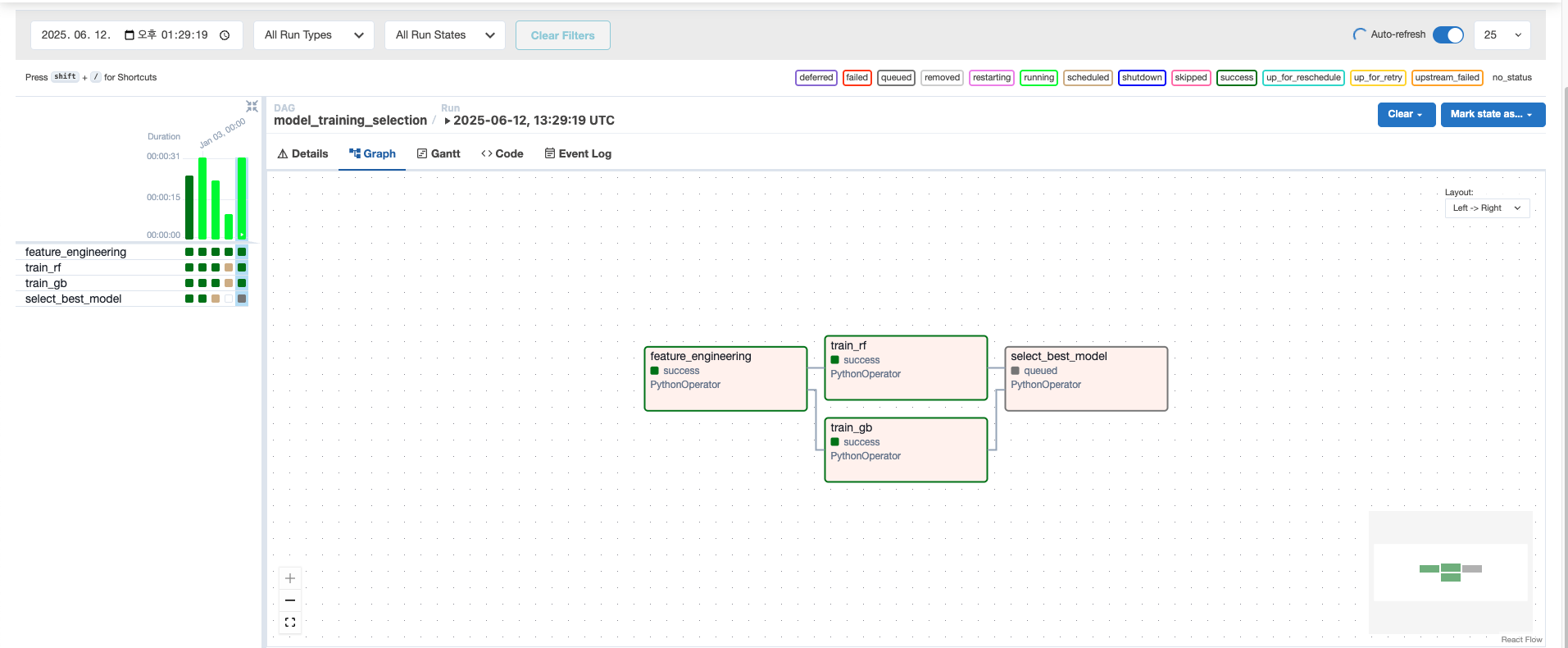 결과 확인
결과 확인
- 3. 모델 성능 로그 확인
 모델 성능 확인
모델 성능 확인
Kubeflow
1. Kubeflow 란?
Kubeflow는 쿠버네티스 기반으로 머신러닝 워크플로우를 관리하고 배포하기 위한 오픈 소스 플랫폼
MLOps의 한 부분으로 Kubeflow는 머신러닝 모델 개발과 배포를 위한 end-to-end 솔루션을 제공
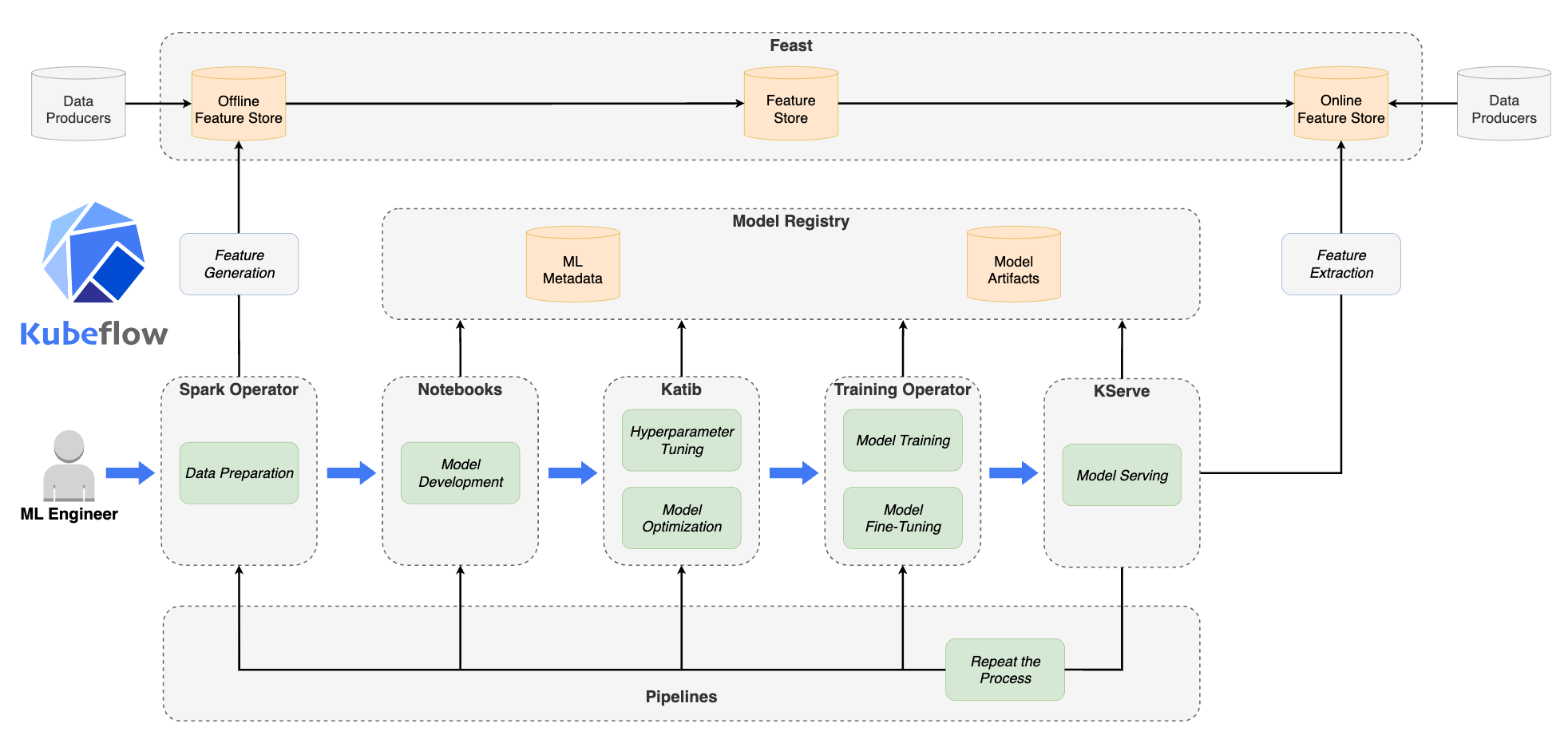
2. 구성 요소
- Distributed Training: 다양한 ML 프레임워크를 지원하며, 분산 학습을 통해 대규모 데이터 처리가 가능
- Pipeline: 머신러닝 워크플로우의 각 단계를 pipeline으로 정의하여, 각 단계를 자동화 제공
- Model Serving: 모델 배포 및 서빙을 위한 기능을 제공, 모델의 확장성/안정성/빠른 응답 속도를 보장
- Model Management: 모델 버전 관리, 모델 성능 모니터링, 모델 성능 비교를 제공
주요 기능들
- Kubeflow pipeline
- Kubeflow serving
- Katib
- Metadata store
- Jupyter notebooks intergration
3. Kubeflow pipeline
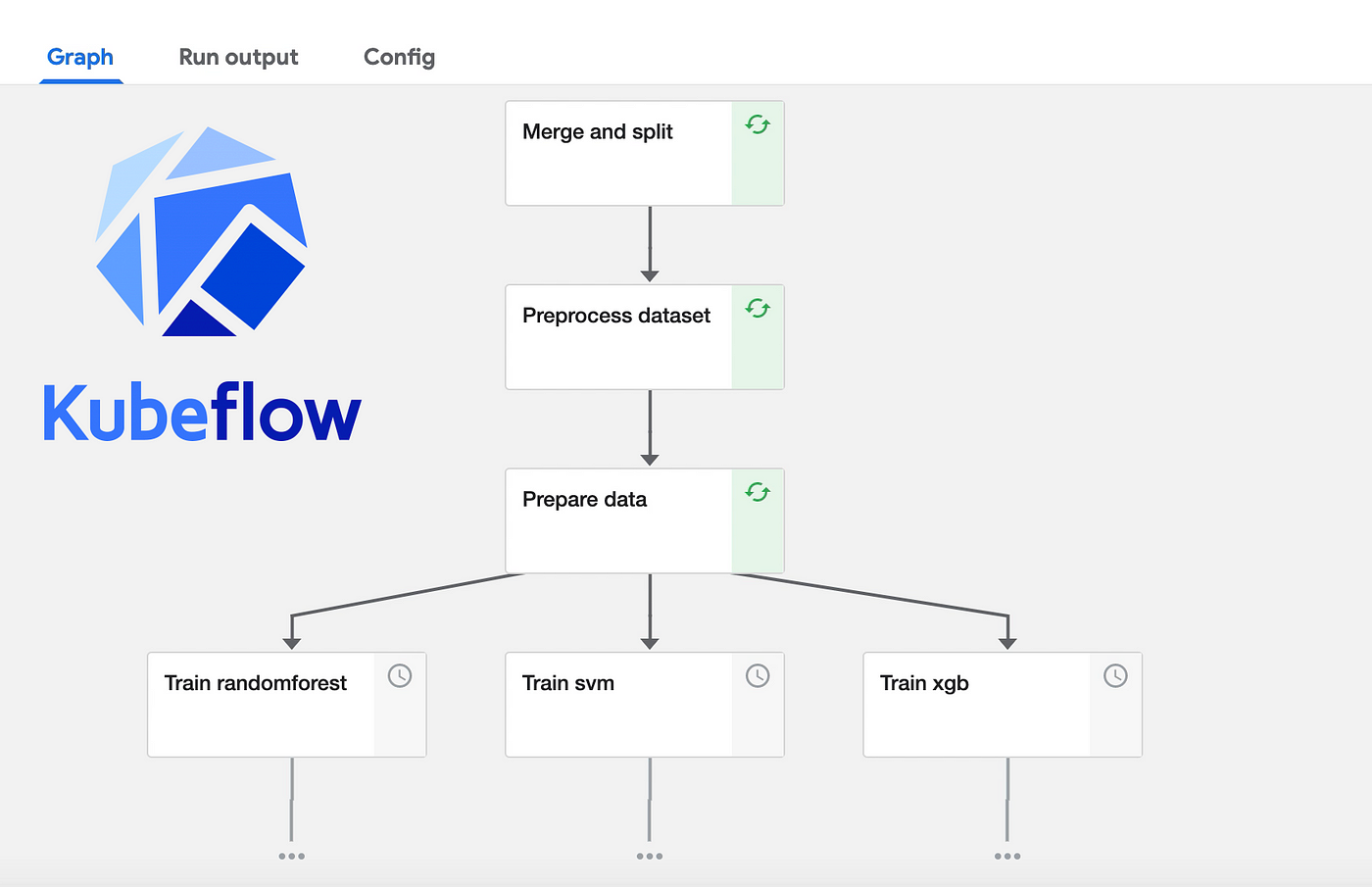
- 💡 Kubeflow pipeline: 기계학습 워크플로우를 효율적으로 관리하고 자동화하기 위한 도구
- 전체 ML 워크플로우를 파이프라인으로 구축하여 반복적이고 일관된 ML 실험을 가능하게함
주요 기능
- 파이프라인 구축: 여러 ML 작업을 연결하여 복잡한 워크플로우를 생성
- 재사용 가능한 컴포넌트: 공통적인 ML 작업을 위한 컴포넌트를 재사용할 수 있어 개발 시간을 단축
- 실험 추적 및 관리: 실험의 결과와 메트릭을 추적하고 버전 관리를 통해 실험을 체계적으로 관리
- 자동화 및 스케줄링: 모델 훈련과 평가를 자동화하고, 정해진 스케줄에 따라 파이프라인을 실행
세부 사항
- 컨테이너 기반 실행: 각 단계는 독립적인 컨테이너로 실행되며, 이를 통해 환경의 일관성과 격리를 보장
- 확장성: 쿠버네티스 기반으로, 큰 규모의 데이터셋과 복잡한 모델에 대해서도 확장 가능
- 그래픽 인터페이스: 파이프라인의 구성과 실행을 시각적으로 모니터링할 수 있는 웹 기반 인터페이스를 제공
4. Kubeflow serving
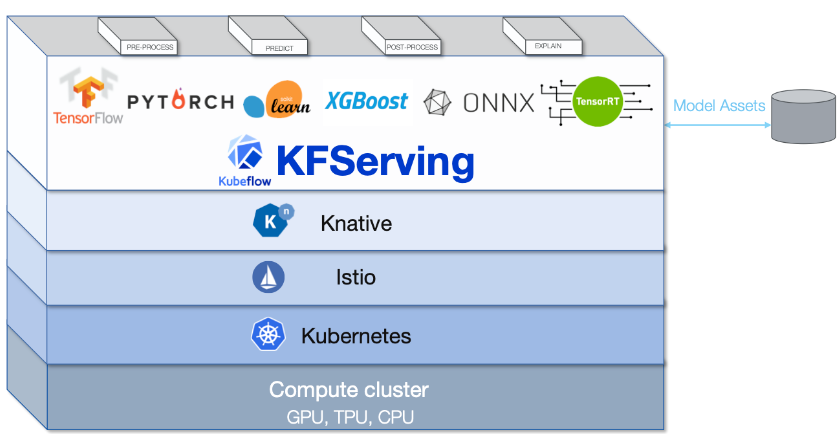
- 💡 Kubeflow serving: 훈련된 머신 러닝 모델을 쉽고 효율적으로 배포할 수 있도록 설계된 서비스
- 모델을 프로덕션 환경에서 사용할 수 있게 하며, 실시간 추론을 위한 환경을 제공
주요 기능
- 다양한 프레임워크 지원: TensorFlow, PyTorch, XGBoost, Scikit-Learn 등 다양한 ML 프레임워크와 호환
- 확장성 있는 모델 서빙: 대규모 트래픽과 데이터에 대응할 수 있는 확장성 있는 아키텍처를 제공
- 버전 관리 및 A/B 테스트: 여러 버전의 모델을 동시에 배포하고, A/B 테스트를 통해 최적의 모델을 선택할 수 있음
- 자동 스케일링: 트래픽의 변화에 따라 자동으로 스케일링하여 리소스를 효율적으로 관리
세부 사항
- 쿠버네티스 기반: 쿠버네티스의 장점을 활용하여 높은 가용성과 안정성을 보장
- REST 및 gRPC 지원: 다양한 클라이언트 요구에 맞춘 인터페이스를 제공
5. Katib
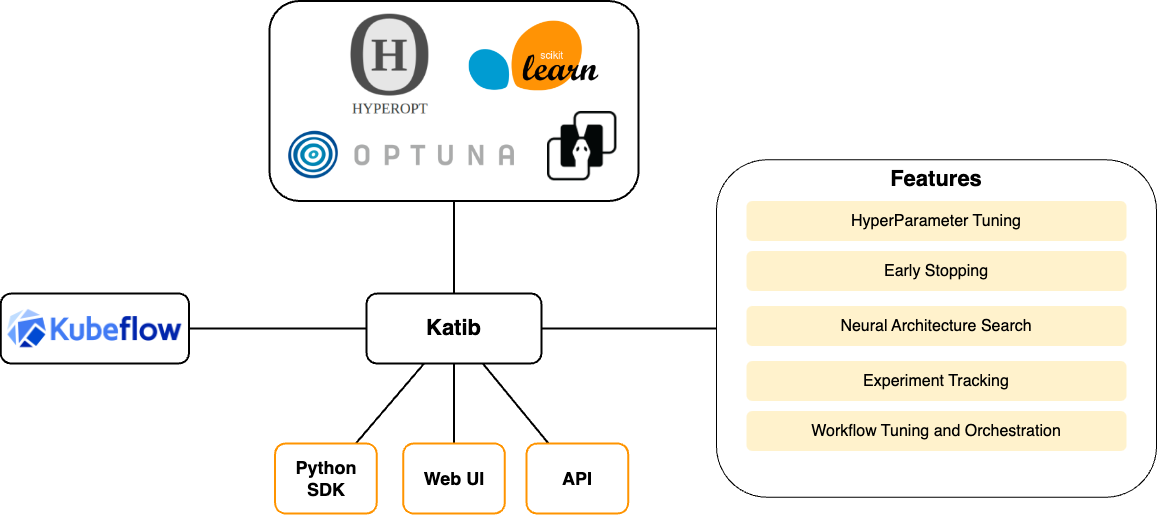
- 💡 Katib: 핵심 구성 요소로, 자동화된 머신 러닝 하이퍼파라미터 튜닝과 신경망 아키텍처 최적화를 제공
- 다양한 알고리즘을 사용하여 ML 모델의 성능을 최적화하는 데 필요한 파라미터를 찾는 데 중점을 둠
주요 기능
- 다양한 튜닝 알고리즘: 그리드 서치, 랜덤 서치, 베이지안 최적화 등과 같은 여러 튜닝 알고리즘을 지원
- 실험 관리: 여러 튜닝 작업을 동시에 실행하고, 각 실험의 성능을 추적하고 비교
- 자동화된 최적화: 튜닝 프로세스를 완전히 자동화하여, 최적의 하이퍼파라미터를 쉽게 찾을 수 있도록 함
세부 사항
- 가시성 및 통제: 사용자는 실험의 진행 상황을 모니터링하고, 필요에 따라 튜닝 프로세스를 조정할 수 있음
- 확장성: 대규모 데이터셋과 복잡한 모델에 대해서도 효과적으로 튜닝을 수행할 수 있음
6. Metadata store
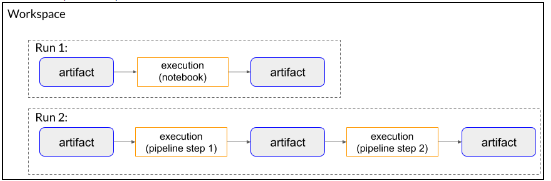
- 💡 Metadata store: Kubeflow에서 머신 러닝 워크플로우의 다양한 측면을 추적하고 저장하는 구성 요소
- 실험, 모델, 데이터셋 등의 메타데이터를 중앙화된 방식으로 관리하여, ML 프로젝트의 투명성과 재현성을 향상
주요 기능
- 메타데이터 저장: 실험 설정, 모델 매개변수, 학습 결과 등을 저장
- 추적 및 관리: 워크플로우의 각 단계를 추적하며, 결과와 과정을 시각적으로 파악할 수 있음
- 버전 관리: 모델의 다양한 버전을 기록하고 관리
- 데이터셋 추적: 사용된 데이터셋과 그 변형을 추적하여 데이터 관리를 강화
세부 사항
- 유연한 저장 구조: 다양한 유형의 메타데이터를 효율적으로 저장하고 관리할 수 있는 유연한 구조를 제공
- 시각화 도구 통합: 실험 결과와 모델 성능을 시각화 도구와 통합하여 직관적인 분석을 가능
7. Jupyter notebooks intergration
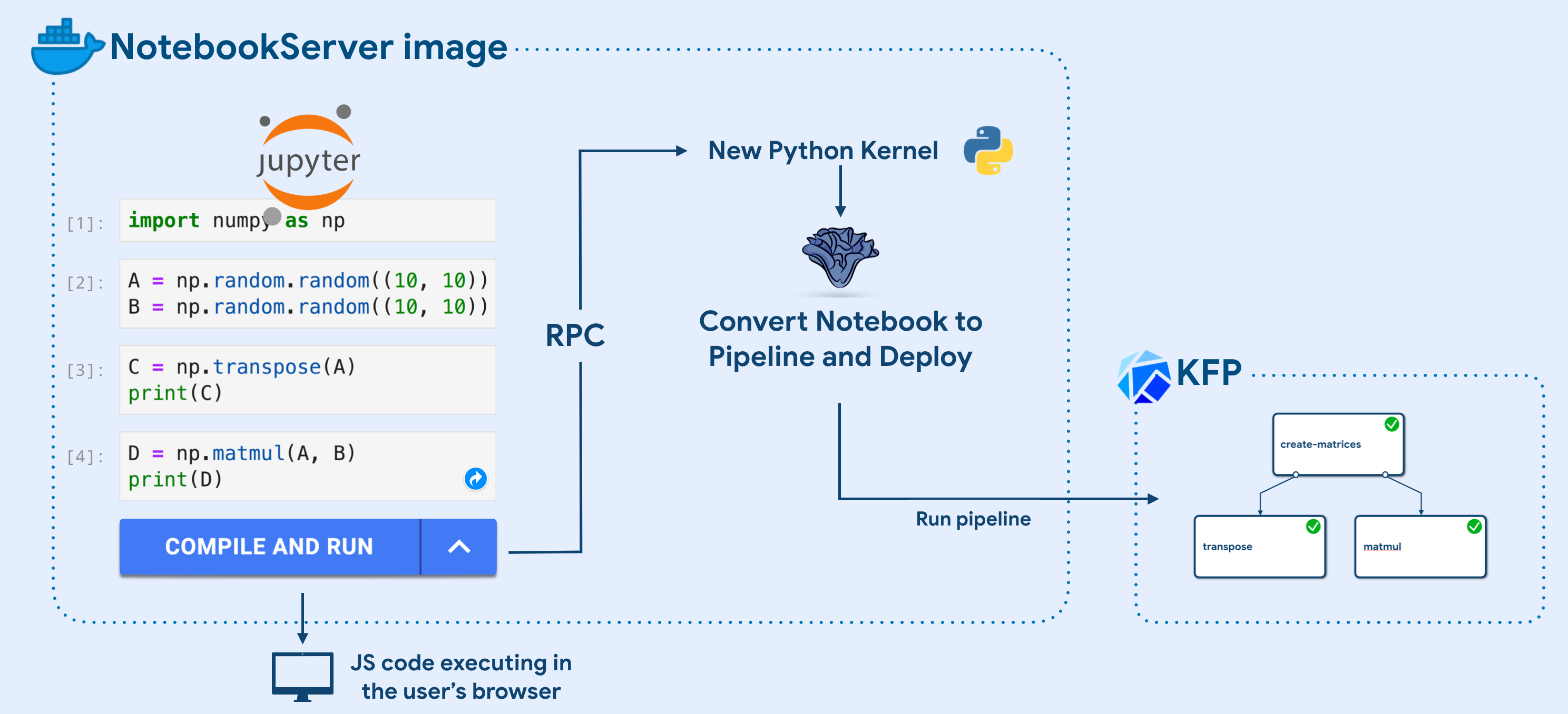
- 💡 Jupyter notebooks intergration: Jupyter 환경에서 ML 모델 개발·실험을 직접 수행할 수 있도록 지원
- Data scientists들이 손쉽게 코드를 작성, 실행하고 결과를 시각화할 수 있음
주요 기능
- 원활한 통합: Kubeflow 환경 내에서 Jupyter 노트북을 쉽게 생성하고 관리할 수 있음
- 코드 개발 및 실험: 데이터 전처리, 모델링, 시각화 등 다양한 작업을 노트북 내에서 직접 수행할 수 있음
- 리소스 확장성: 쿠버네티스 기반의 리소스 관리를 통해 노트북 환경을 필요에 따라 확장할 수 있음
세부 사항
- 다양한 커널 지원: Python, R 등 다양한 프로그래밍 언어를 지원
- 클라우드 연동: 클라우드 저장소와의 연동을 통해 대용량 데이터셋 작업이 가능
This post is licensed under CC BY 4.0 by the author.