[Upstage AI Lab] 8주차 - ML-경진대회
[Upstage AI Lab] ML-경진대회 회고

House Price Prediction
Upstage AI Lab 의 ML 경진대회에 대한 주요 내용과 회고록 내용
1. 개요
House Price Prediction 경진대회는 서울시 아파트 실거래가를 예측하는 모델을 개발하는 대회다.
Project Overview
- Project Duration: 2025.05.01 ~ 2025.05.15
- Team: 5명
- Submission: 9,272개의 input에 대한 예상 아파트 거래금액
- Evaluation Metric: RMSE(Root Mean Squared Error)
2. 주요 역할
본 대회는 팀 프로젝트로 진행되었으며, 이 글에서는 내가 맡았던 주요 작업과 전략적 접근에 대해 기술한다.
- Data PreProcessing
- 행정구역별 공공데이터 수집, 주소 기반 위경도 변환 (카카오 API 활용)
- 아파트 단지와 시설물 간의 거리 계산
- 결측치를 RandomForest 모델로 예측 보간
- 전처리 코드 및 데이터를 팀원들에게 공유
- EDA
- 수치형 변수들의 정규성 확인
- 주요 변수 분포 및 이상치 확인
- 범주형 변수별 평균 거래가 분석
- Feature Engineering
- 지하철, 버스, 마트 등 주변 인프라 밀집도 파생 변수 생성
건축년도 및 거래 시점을 기반으로 경과 연도, 분기 등 파생 날짜 변수 생성
변수 선택 단계에서, Spearman 상관계수와 Mutual Information Score를 활용하여
타겟과의 비선형 상관성 및 순위 기반 관계를 분석인코딩 전 단계에서 범주형 변수와 타겟 변수 간의 통계적 독립성을 검정하기 위해
Kruskal-Wallis H-test를 적용 타겟 분포에 유의미한 차이를 유발하는 변수만 선별하여 인코딩에 반영- 선별된 범주형 변수에 대해 Label Encoding 및 Frequency Encoding(출현 비율 기반)을 혼합 적용하여 트리 계열 모델에 적합하도록 수치형 변수로 변환
- Modeling
- Tree-based 모델 5종 성능 비교 (LightGBM, XGBoost, CatBoost 등)
- K-Fold 교차검증 및 베이지안 최적화 기반 하이퍼파라미터 튜닝
- 최종 제출 전략
- 성능이 우수한 TOP3 모델들에 대해 Soft Voting Ensemble을 적용하여 최종 결과 제출
3. Data Set
4개의 Data Set이 제공되며, 외부 데이터 수집도 가능하여 별도로 수집해서 진행했다.
제공 받은 데이터
| Data Set | 설명 | Rows | Columns |
|---|---|---|---|
| Train.csv | - 아파트 거래 데이터 (Target Feature 포함) | 1,118,822 | 52 |
| Test.csv | - 위와 동일 (Target Feature 제외) | 9,272 | 51 |
| Subway_feature.csv | - 서울시 지하철 승강장의 주소, 위도, 경도 데이터 | 768 | 5 |
| Bus_feature.csv | - 서울시 버스 승강장의 주소, 위도, 경도 데이터 | 12,584 | 6 |
외부 수집 데이터
- 아래 표에서 볼드 처리된 데이터들은 주소가 있지만 좌표값이 없기에 카카오 API를 사용해 위도, 경도 수집
| Data set | 설명 | Rows | Columns |
|---|---|---|---|
| Address_xy.csv | - 번지 주소 기준 위도, 경도 데이터 (결측값 포함) | 44,118 | 23 |
| 예금취급기관_가계대출.csv | - 예금 데이터 | 218 | 9 |
| 지가지수.csv | - 지가지수 데이터 | 52,771 | 8 |
| Crime_pop_money.csv | - 서울시 구별 5대 범죄율, 인구수, 평균 소득 데이터 | 25 | 22 |
| Garden.csv | - 서울시 구별 공원명, 공원 주소 (한강 포함) | 141 | 4 |
| School.csv | - 서울시 구별 초·중·고·대학교 위치 데이터 | 1,320 | 6 |
| Hospital.csv | - 서울시 구별 병원 위치 데이터 | 21,485 | 6 |
| Movie.csv | - 서울시 구별 영화관 위치 데이터 | 93 | 5 |
| Mart.csv | - 서울시 대규모 점포(대형마트, 백화점 등) 데이터 | 1,012 | 6 |
| Price.csv | - 서울시 구별 주택가격지수, 지가변동률, 금리, 기대인플레이션 등 | 5,025 | 10 |
| GDP.csv | - 취득, 재산, 지방소득 데이터 | 1,187 | 6 |
4. 최종 결과
Public Score 에선 8위를 했지만 Private Score 에서는 4위로 마무리했다.
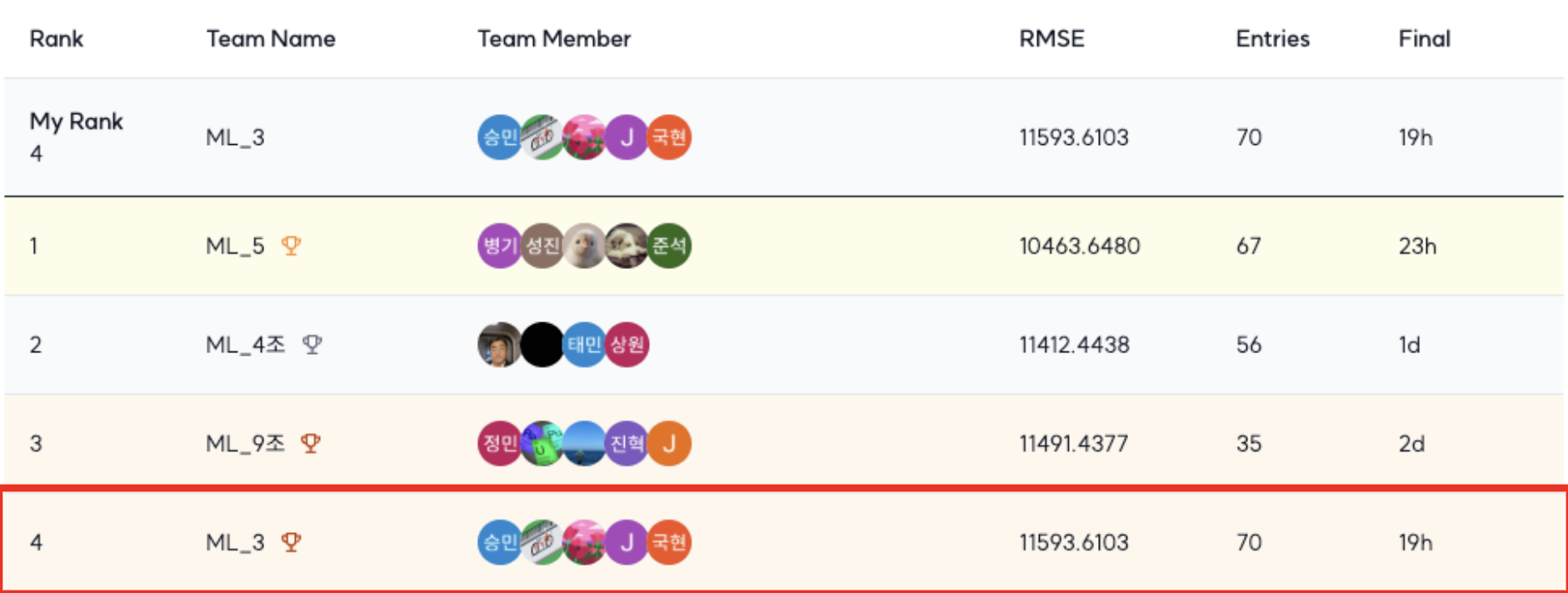
- Public Score: 16681.1584
- Private Score: 11593.6103
회고
이 섹션은 Upstage AI Lab ML 경진대회를 통해 경험한 문제와 해결과정에 대한 회고를 담았다.
문제 & 해결 과정
문제
대회 초반 Hold-Out 기준으로 모델을 검증했을 때 RMSE가 5,000 ~ 7,000 수준으로 나왔지만 실제 제출 결과는
약 3~4배 안 좋게 나왔다. 과적합인줄 알아서 K-Fold 교차검증을 통해 확인해 봐도 과적합 문제는 아니였다.
해결 과정
Train/Test를 살펴보니 아래와 같이 구성 돼 있었다.
- Train Data: 2007년 ~ 2023년 6월
- Test Data: 2023년 7월 ~ 9월
즉, 완전히 분리된 시계열 구조였으나 이를 고려하지 않고 임의의 Hold-Out만으로 모델을 검증한 것이 문제였다.
해서 Time-based split 기준으로 검증셋을 2023.05 ~ 2023.06 설정하고 학습 및 평가를 한 결과
성능 차이가 대폭 감소하였다.
인사이트
아쉬웠던 점
모델링 초기엔 당연하다는 듯이
train_test_split함수를 사용하여 단순 Hold-Out 방식으로 검증을 시작했다.
이로 인해 랜덤 분할된 검증셋을 쓴 결과 점수는 좋았지만, 제출 점수는 훨씬 더 안 좋게 나오는 현상이 반복되었다.
처음에는 이를 과적합 문제로 오판하고 K-Fold 교차검증에 많은 시간을 쏟았지만, 뒤늦게 검증 방식이 시계열 단절을 고려하지 않은 것이 문제임을 깨닫고, 변수 선택, 파라미터 튜닝 등 다양한 실험을 시도하지 못한 점이 아쉬웠다.
알게 된 점
단순히 점수가 높은 검증 방식을 찾는 것이 중요한 것이 아니라, 데이터의 구조와 분포 특히 시계열 문제에서는 시간 흐름의 연속성을 이해하고 그에 맞는 검증 전략을 설계해야 신뢰할 만한 평가 지표를 얻을 수 있다는 것을 배웠다.
올바른 검증 방식 없이는 하이퍼파라미터 튜닝, 피처 선택 등 전체 모델링 과정이 왜곡될 수 있다는 점도 실감했다.