[Deep Learning] 기본 용어
[Deep Learning] 기본 용어 이해하기
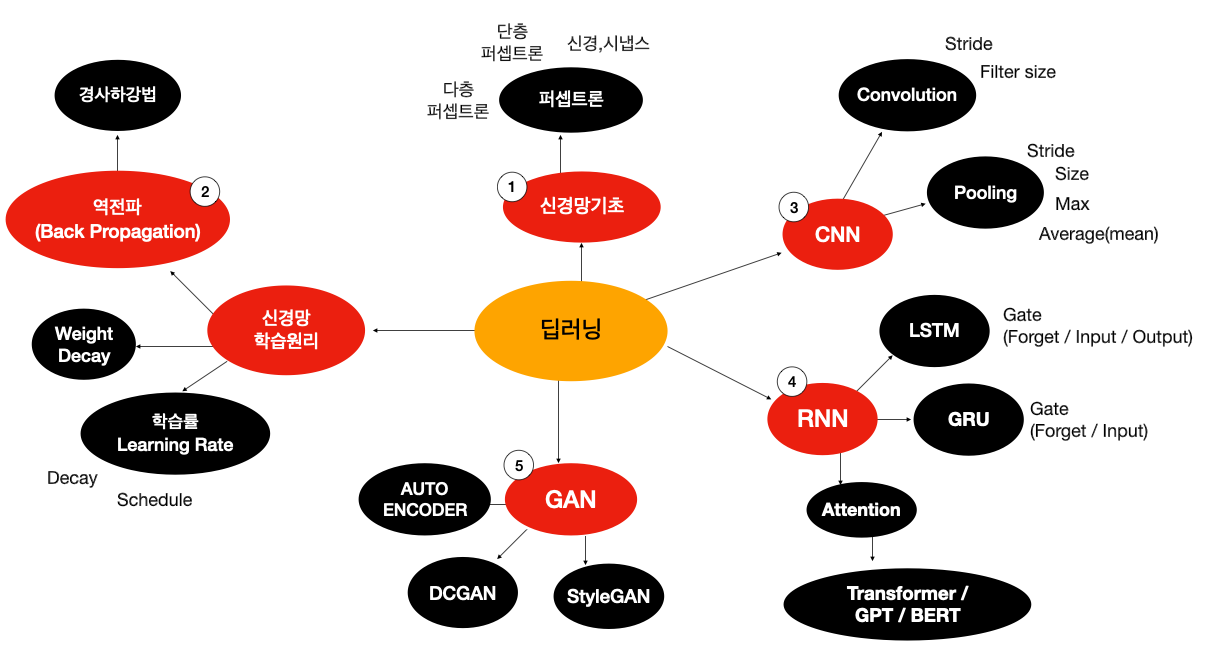
[Deep Learning] 기본 용어
들어가며
이번 포스팅은 딥러닝을 공부하기 전에 반드시 알아야 할 핵심 용어들과 개념들을 소개합니다.
기초가 되는 주요 용어들의 의미와 역할을 설명하고, 딥러닝 모델에서 어떻게 활용되는지 정리했습니다.
Neural Network
1. 신경망의 기본 구성 요소
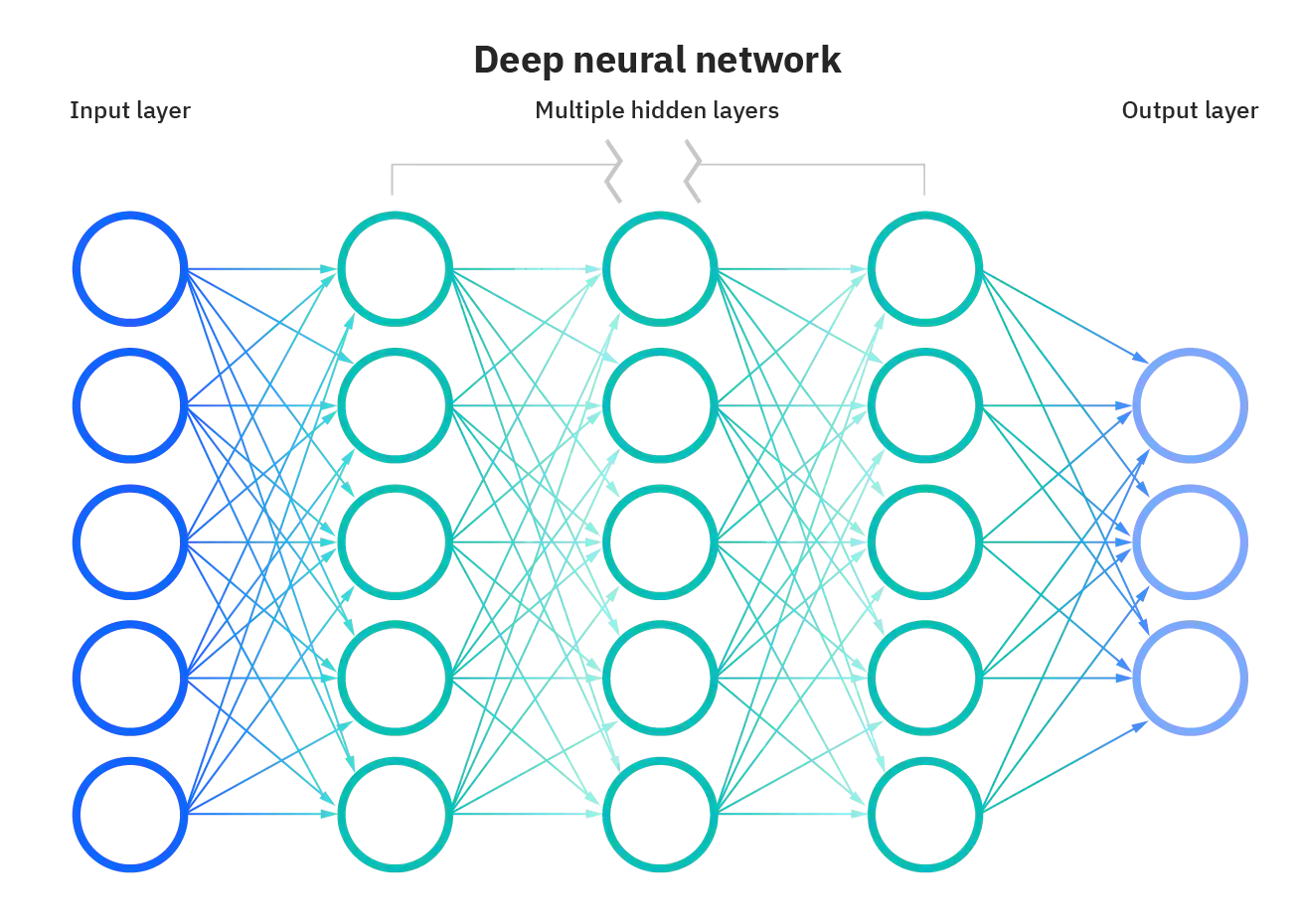
딥러닝의 기본 모델인 Neural Network는 여러 Layer가 차례로 연결된 다층 구조다.
각 Layer는 다수의 뉴런으로 구성되며, 뉴런 간 연결 강도를 조절하는 Weight와 Bias를 포함한다.
기본 구성 요소는 아래와 같다.
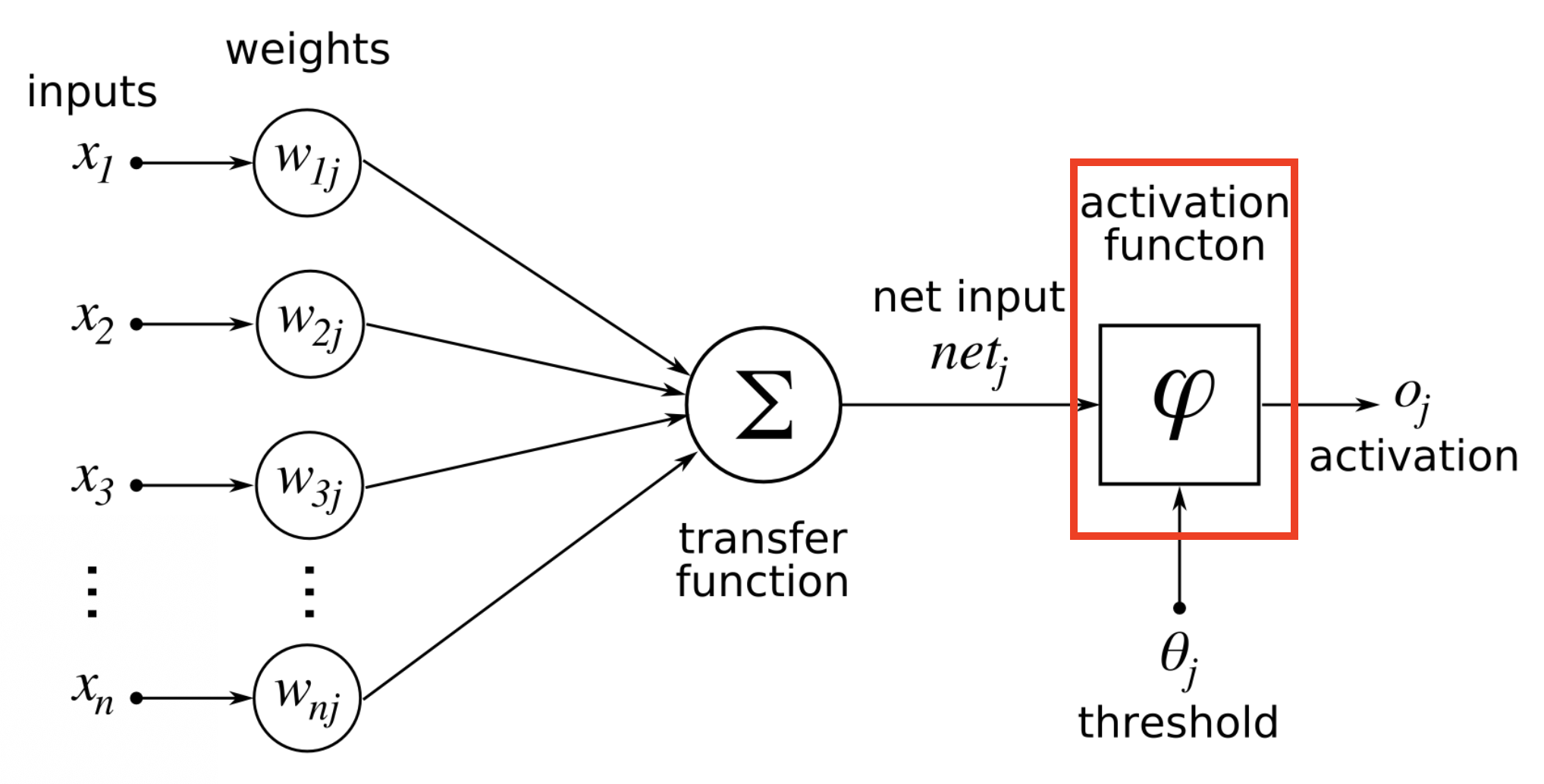
- Neuron(뉴런): 입력값에 가중치를 곱하고 편향을 더한 뒤 활성화 함수를 통과시켜 출력값을 생성
- Weight(가중치): 입력값의 중요도를 조절하는 파라미터, 학습을 통해 값이 조정됨
- Bias(편향): 뉴런의 활성화 기준을 이동시키는 값, 학습을 통해 조정됨
- Activation Function(활성화 함수): 뉴런의 출력을 비선형적으로 변환하여 복잡한 패턴을 학습 가능
- Layer(층): 같은 역할을 수행하는 뉴런들의 집합
- Input Layer(입력층): 외부 데이터가 신경망에 처음 입력되는 층. 입력 데이터의 특성 수만큼 뉴런이 존재
- Hidden Layer(은닉층): 입력층과 출력층 사이에 위치, 입력 데이터를 처리하고 새로운 특징을 추출하는 층
- Output Layer(출력층): 신경망의 최종 결과를 출력하는 층. 문제 유형에 따라 뉴런 수가 결정됨
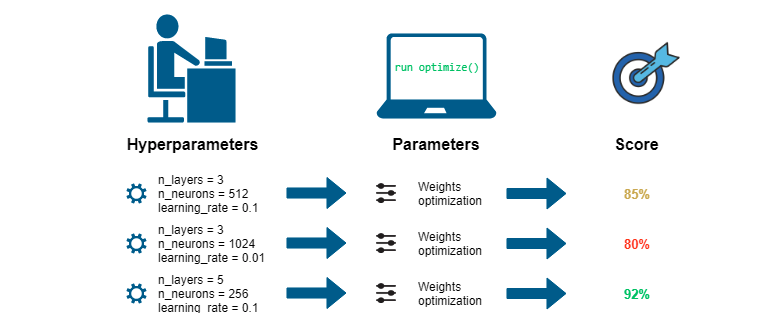
2. Hyperparameter (하이퍼파라미터)
사용자가 직접 설정하는 값으로 Learning Rate, Batch Size, Epochs, Regularization 등이 있으며
모델 구조·학습 과정을 제어하는 주요 변수들이다.
- Learning Rate(학습률): 가중치 업데이트 크기
- Batch Size(배치 크기): 한 번에 처리할 샘플 수
- Epochs(에폭 수): 전체 데이터셋을 반복 학습하는 횟수
- Optimizer(최적화 알고리즘): 가중치 갱신 방식을 결정 (예: SGD, Adam)
- Momentum(모멘텀): SGD의 관성 항 비율, 진동 완화 및 수렴 가속
- Regularization(정규화 강도): L1/L2 페널티 계수 등, 과적합 방지 정도
- Dropout Rate(드롭아웃 비율): 학습 중 무작위로 뉴런을 제외할 확률
- Early Stopping Patience: 검증 성능 개선 없을 때 학습 중단을 위한 대기 에폭 수
3. Activation Function (활성화 함수)
활성화 함수는 뉴런의 출력을 비선형으로 변환하여, 신경망이 복잡한 패턴을 학습할 수 있도록 돕는 요소다.
- Step Function(계단 함수): 입력값이 임계값을 넘으면 1, 아니면 0을 출력. 정보 손실이 많음
- Sigmoid(시그모이드): 입력값을 0~1 사이로 압축하는 비선형 함수. 이진 분류에 적합
- Tanh(하이퍼볼릭 탄젠트): 입력값을 -1~1 사이로 압축. Sigmoid보다 강한 기울기
- ReLU(렐루): 입력값이 0보다 크면 그대로 출력, 0보다 작으면 0을 출력. 은닉층에서 주로 사용
- Leaky ReLU(리키 렐루): 입력값이 0보다 작아도 작은 기울기를 갖도록 함.
- Softmax(소프트맥스): 여러 클래스 중 하나를 선택하는 다중 분류 문제에 사용. 출력값의 합이 1이 되도록 변환
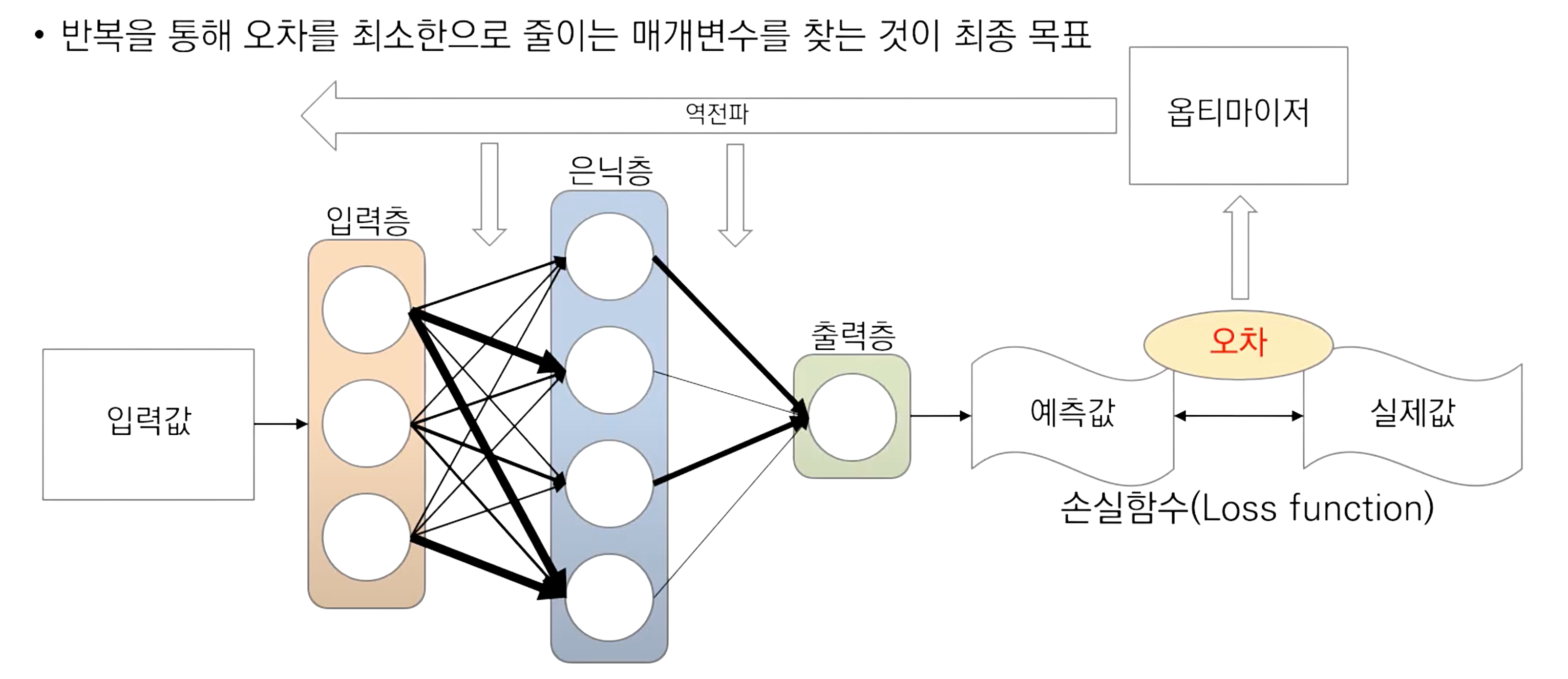
4. Loss Function (손실 함수)
모델 학습 시 예측값과 실제값의 차이(오차)를 수치화하여 가중치 갱신에 활용하는 함수
손실함수의 함수값이 최소화 되도록 하는 가중치(weight)와 편향(bias)을 찾는 것이 목표
값이 낮을수록 학습이 잘 된 것, 정답과 알고리즘 출력을 비교하는 데 사용
- Mean Squared Error (MSE): 회귀 문제에서 오차 제곱의 평균을 사용하며, 큰 오차에 더 민감
- Activation: Linear 출력층
- Mean Absolute Error (MAE): 회귀 문제에서 오차 절댓값의 평균을 사용하며, 이상치에 덜 민감
- Activation: Linear 출력층
- Huber Loss (Smooth L1): 작은 오차에는 제곱 손실, 큰 오차에는 절댓값 손실을 적용해 이상치에 강건
- Activation: Linear 출력층
- Binary Cross-Entropy (BCE): 이진 분류에서 예측 확률과 실제 레이블 간 차이를 계산
- Activation: Sigmoid
- Categorical Cross-Entropy (CCE): 다중 클래스(one-hot) 분류에서 클래스 확률 분포 간 차이를 계산
- Activation: Softmax
- Sparse Categorical Cross-Entropy: 정수 레이블을 직접 사용해 CCE를 계산하며, 메모리·계산 효율이 높음
- Activation: Softmax
Convolutional Neural Network
1. CNN 기본 구성 요소
CNN은 2D/1D 데이터(이미지·시계열 등)를 처리하기 위해 합성곱·풀링 연산을 활용하는 신경망 구조
기본 구성 요소는 아래와 같다.
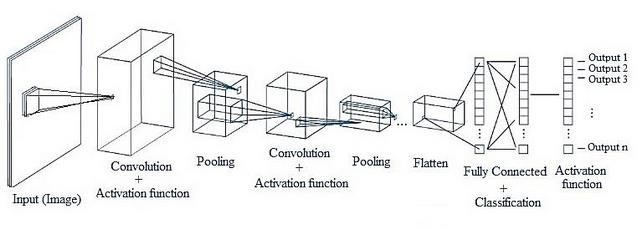
- Filter / Kernel(필터/커널): 특징을 추출하는 작은 가중치 행렬
- Convolution(합성곱): 필터를 입력에 적용해 Feature Map을 생성
- Feature Map(특징 맵): 합성곱 후 얻어지는 출력 채널, 입력의 지역 패턴 표현
- Pooling (풀링): 공간 크기 축소 및 중요한 특징 보존
- Max Pooling(최대 풀링)
- Mean Pooling(평균 풀링)
- Flatten(평탄화): 다차원 Feature Map을 1D 벡터로 변환
- Fully-Connected Layer(완전 연결층): 벡터를 입력받아 최종 분류/회귀 수행
- 💡모든 입력이 모든 출력 노드와 연결되어 있는 신경망의 최종 결정 계층
2. CNN Hyperparameter
CNN 학습 시 성능과 학습 속도에 큰 영향을 주는 설정 값들
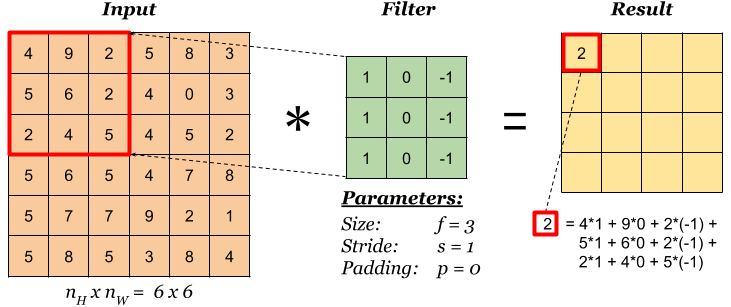
- Number of Filters: 각 합성곱 층에서 학습할 필터(채널) 수
- Kernel Size: 필터의 공간 크기 (예: 3×3, 5×5)
- Stride: 필터 이동 간격, 출력 크기 및 연산량 제어
- Padding: 입력 경계 처리 방식 (“same” vs “valid”)
- Pooling Size: 풀링 연산 영역 크기 (예: 2×2)
마무리
이번 포스트에서는 딥러닝의 핵심 용어를 정리해봤다. 추후에는 CNN의 더 자세한 내용도 다룰 예정이다.
This post is licensed under CC BY 4.0 by the author.