[빅분기] 필기 Chapter 07. 분석 모형 설계
[빅데이터분석기사] 필기 'Chapter 07. 분석 모형 설계' 내용을 정리했습니다.

[빅분기] 필기 Chapter 07. 분석 모형 설계
들어가며
빅데이터분석기사 필기 시험을 준비하며 공부한 내용을 Chapter 별 핵심 내용 기준으로 정리한 내용입니다.
교재는 이기적-빅데이터분석기사 필기-2024로 공부했습니다.
01. 분석 절차 수립
1. 분석 모형 정의
분석 기법 또는 분석 알고리즘을 적용하기 전에 분석 모형에 대한 선정이 필요
1-1) 분석 모형 정의와 분류
분석 모형은 분석 목표에 따라 데이터 특성을 도출하고, 가설 수립에 따라 전체적인 분석 방향을 정의하는 모형으로
예측, 진단, 최적화 모형 등으로 구분
1. 예측 분석 모형
- 어떤 일들이 발생할 것인가?
- 적조, 예측, 주가, 범죄/위험 등 예측
- 과거, 현재까지의 데이터와 상황에 따른 가설을 기반하여 미래에 대한 현상을 사전에 분류하고 예측
2. 현황 분석 모형
- 과거에 어떠한 상황이 왜 어떻게 일어났는가? / 현재 어떠한 상태인가?
- 과거 데이터를 통해 현재 상황을 객관적으로 진단하는 모형
- 미래 예측이 아닌 현재를 이해함에 활용
3. 최적화 분석 모형
- 어떻게 하면 원하는 결과가 일어날 수 있을까?
- 제한된 자원, 환경 내에서 최대의 효용성, 이익과 같은 결과를 생성하기 위해
- 최적화하는 데에 중점을 둔다.
1-2) 분석 모형 정의를 위한 사전 고려사항
분석 모형을 정의하기 전에 분석이 실제 추진될 수 있을지 가능성을 타진하는 것이 중요
| 기준 | 판단 근거 |
|---|---|
| 필요성 | 개인이나 기관 관점에서 분석 과제가 필요한지 판단 |
| 파급효과 | 정성적, 정량적 기대효과의 정도 판단 |
| 추진 시급성 | 당장 해소되어야 할 사회현안 여부 판단, 장기과제 성격 분리 |
| 구현 가능성 | 과제를 구현함에 있어서 어려움이 없는지 현실성 판단 |
| 데이터 수집 가능성 | 공공기관 협조나 데이터 확보, 데이터 구매 등 제약사항 판단 |
| 모델 확장성 | 과제가 시범과제로 끝나지 않고 전체 데이터 모델로 확장 가능한지 판단 |
2. 분석 모형 구축 절차
2-1) 분석 모형 설계
1. 분석 모형 설계 시 사전 확인 사항
- 필요한 데이터 항목이 정해졌는가?
- 표준화 방법을 정하였는가?
- 단계별로 모델이 설계되었는가?
- 분석 검증 통계 기법을 선정하였는가?
2. 분석 모델링 설계와 검정
- 분석 목적에 기반한 가설검정 방법을 수림
- 추정방법에 대한 기술을 검토
- 분석 모델링 설계와 검정 방법을 수립
3. 분석 모델링에 적합한 알고리즘 설계
- 비지도학습: 군집분석, 연관성 분석, 오토인코더 등
- 지도학습: 의사결정트리, 랜덤포레스트, SVD, 회귀분석 등
- 준지도학습: 셀프 트레이닝, 적대적 생성 모델 등
- 강화학습: Q-Learning, 정챙경사 등
4. 분석 모형 개발 및 테스트
- 모듈 기능을 정의
- 모듈 설계
- 모듈 개발 결과물과 모델 설계 일치를 확인
2-2) 분석 모델링 설계와 검정
가설검정은 다음과 같은 총 5단계의 절차를 거치게 된다.
- 귀무가설과 대립가설 설정
- 영가설이라고도 하며 대립가설에 상반되는 가설로서 기각되는 것이 예상되어 세워진 가설
- 검정통계량의 설정
- 가설을 검정하기 위한 기준으로 사용하는 값
- 확률분포 상에 어디에 위치하는지에 따라 귀무가설을 기각하거나 기각하지 않는다.
- 기각역의 설정
- 기각역은 확률분포에서 귀무가설을 기각하는 영역을 말함
- 기각역에 검정통계량이 위치하면 귀무가설을 기각
- 검정통계량 계산
- 검정통계량의 계산식은 다음과 같다.
- 신뢰수준: 가설을 검정할 때 어느 정도로 검정할 것인지에 대한 수준
- 유의수준: 가설을 검정할 때 일정 수준을 벗어나면 귀무가설이 오류라고 판단
- 통계적인 의사결정 (가설검정)
가설검정에서의 검정 방법은 양측검정과 단측검정 두 가지가 있다.
- 양측검정
- 귀무가설을 기각하는 영역이 양쪽에 있는 검정을 말함
- 대립가설이 ~가 아니다 (크거나 작다) 라면 양측검정을 사용
- 단측검정
- 귀무가설을 기각하는 영역이 한쪽 끝에 있는 검정을 말함
- 대립가설이 ~보다 작다 혹은 크다인 경우 단측검정을 사용
02. 분석 환경 구축
1. 분석 도구 선정
1-1) R
R은 통계분석과 자료의 시각화를 위해 개발한 오픈소스 분석용 프로그래밍 언어로 다음과 같은 특징이 있다.
- 객체지향 언어
- 데이터, 함수, 차트 등 모든 데이터가 객체 형태로 관리되어 효율적인 조작과 저장 방법을 제공
- 고속 메모리 처리
- 모든 객체는 메모리로 로딩되어 고속으로 처리되고 재사용 가능
- 다양한 자료 구조
- 벡터, 배열, 행렬, 데이터프레임, 리스트 등 다양한 자료구조와 연산 기능을 제공
- 최신 패키지 제공
- 최신의 알고리즘과 방법론 제공
- 시각화
- 데이터 분석과 표현을 위한 다양한 그래픽 도구를 제공
R의 장,단점
| 장점 | - 지속적으로 업데이트되는 다양한 패키지 - 그래프 및 도표, 시각화 기능에 특화 |
| 단점 | - 대용량 메모리 처리가 어려우며 보안 기능이 취약 - 별도의 모듈 연동이 아니면 웹 브라우저에서 사용 불가 |
1-2) Python
귀도 반 로섬이 발표한 오픈소스 분석용 프로그래밍 언어로, 인터프리터식, 객체지향적 대화형 언어
- 배우기 쉬운 대화 기능
- 간결하고 쉬운 문법으로 컴파일, 실행, 테스트가 용이
- 동적인 데이터타입 결정 지원
- 동적으로 데이터타입을 결정하므로 데이터타입에 무관하게 코드 작성이 가능
- 독립적 언어
- 운영체제에 독립적으로 컴파일 없이 동작 실행
- 자료형과 자동 메모리 관리
- list, tuple 등 유연한 내장 객체 자료형을 지원
- 메모리 자동 할당 후 종료 시 자동 해지하는 메모리 청소 기능을 제공
Python의 장,단점
| 장점 | - 영어 문장 형식으로 구현된 빠른 개발 속도 - 재사용 가능한 모듈 제공 - C언어를 포함한 다른 언어 프로그램들과 연동성 높음 |
| 단점 | - 컴파일 없이 인터프리터가 한 줄 씩 실행하는 방식으로 실행속도 느림 |
2. 데이터 분할
2-1) 데이터 분할 정의
분석용 데이터로 모형을 구축하여 평가 및 검증하기 위해서 전체 데이터를 학습 데이터, 평가 데이터, 검증 데이터로 분할
- Train Data
- 데이터를 학습하여 분석 모형을 만드는 데에 사용하는 데이터
- Validation Data
- 모델이 과대/과소적합인지 성능을 평가하는 데이터
- Test Data
- 최종적으로 일반화된 분석 모형을 검증하는 테스트를 위한 데이터
- 보통 7:3 또는 8:2 비율로 분리
- 전체적인 학습, 평가, 검증 비율은 일반적으로 4:3:3, 5:3:2로 정한다.
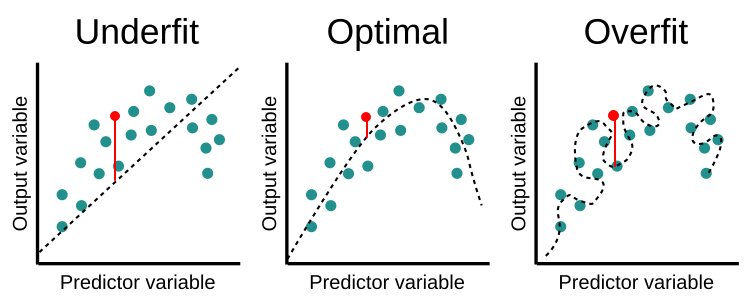
2-2) 과대적합/과소적합
- 과적합(Overfitting)
- 학습 데이터에 대해서는 높은 정확도를 나타내지만 테스트 데이터나 새로운 데이터에 대해서는 예측을 잘 하지 못하는 것을 과적합, 과대적합이라고 한다.
- 과적합 방지를 위해 K-fold 교차검증, 정규화 등의 방법이 있다.
- 과소적합(Underfitting)
- 모형이 단순하여 데이터 내부의 패턴 또는 규칙을 잘 학습하지 못하는 현상이다.
- 학습 데이터에서도 정확한 결과를 도출하지 못한다.
- 일반화
- 학습 데이터를 통해 생성된 모델이 평가 데이터를 통한 성능 평가 외에도
- 검증용 테스트 데이터를 통해 정확하게 예측하는 모델을 일반화된 모형이라고 한다.
This post is licensed under CC BY 4.0 by the author.