[빅분기] 필기 Chapter 05. 데이터 탐색
[빅데이터분석기사] 필기 'Chapter 05. 데이터 탐색' 내용을 정리했습니다.

들어가며
빅데이터분석기사 필기 시험을 준비하며 공부한 내용을 Chapter 별 핵심 내용 기준으로 정리한 내용입니다.
교재는 이기적-빅데이터분석기사 필기-2024로 공부했습니다.
01. 데이터 탐색의 기초
1. 데이터 탐색의 개요
1-1) 탐색적 데이터 분석(EDA)
수집한 데이터가 들어왔을 때, 다양한 방법을 통해서 자료를 관찰하고 이해하는 과정을 의미는 것
1-2) 탐색적 데이터 분석의 필요성
- 내재된 잠재적 문제에 대해 인식하고 해결안을 도출할 수 있다.
- 문제정의 단계에서 인지 못한 새로운 양상 패턴을 발견할 수 있다.
- 새로운 양상을 발견 시 초기설정 문제의 가설을 수정하거나 또는 새로운 가설을 설립할 수 있다.
1-3) 분석과정 및 절차
- 분석의 목적과 변수가 무엇인지, 개별변수의 이름이나 설명을 가지는지 확인
- 데이터의 결측치 유무, 이상치 유무 등을 확인하고 분포상의 이상 형태와 Head, Tail 부분을 확인
- 기초통계산출을 통한 확인과정을 거친다.
- 데이터 간의 상관관계 등을 확인
2. 상관관계 분석
2-1) 변수 간 상관성 분석
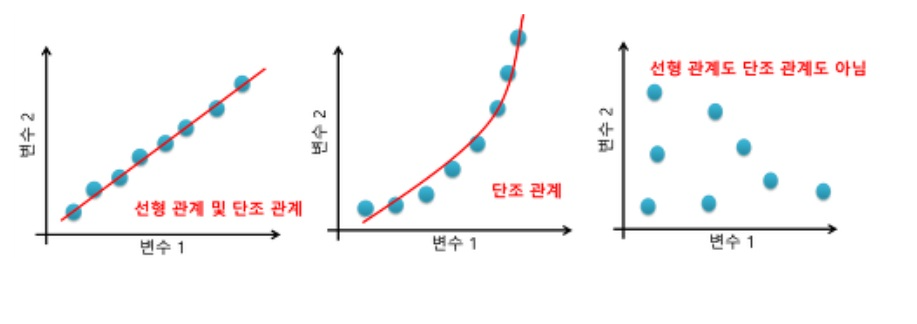
- 두 변수 간에 어떤 선형적 관계를 갖고 있는지를 분석하는 방법이다.
- 두 변수 간의 관계의 강도를 상관관계라 한다.
- 단순상관분석: 단순히 두 개의 변수가 어느 정도 강한 관계에 있는가를 측정한다.
- 다중상관분석: 3개 이상의 변수 간의 관계강도를 측정한다.
- 편상관관계분석: 다중상관분석에서 다른 변수와의 관계를 고정하고 두 변수의 관계강도를 측정하는 것
2-2) 상관분석의 기본가정
- 선형성
- X와 Y의 관계가 직선적인지를 알아보는 것으로 이 가정은 분포를 나타내는 산점도를 통해 확인할 수 있다.
- 등분산성(동변량성)
- X의 값에 관계없이 Y의 흩어진 정도가 같은 것을 의미
- 반의어는 이분산성이다.
- 정규분포성
- 두 변인의 측정치 분포가 모집단에서 모두 정규분포를 이루는 것
- 무선독립표본
- 모집단에서 표본을 뽑을 때 표본대상이 확률적으로 선정된다는 것
2-3) 상관분석 방법
피어슨 상관계수
- 두 변수 X와 Y 간의 선형 상관관계를 계량화한 수치이다.
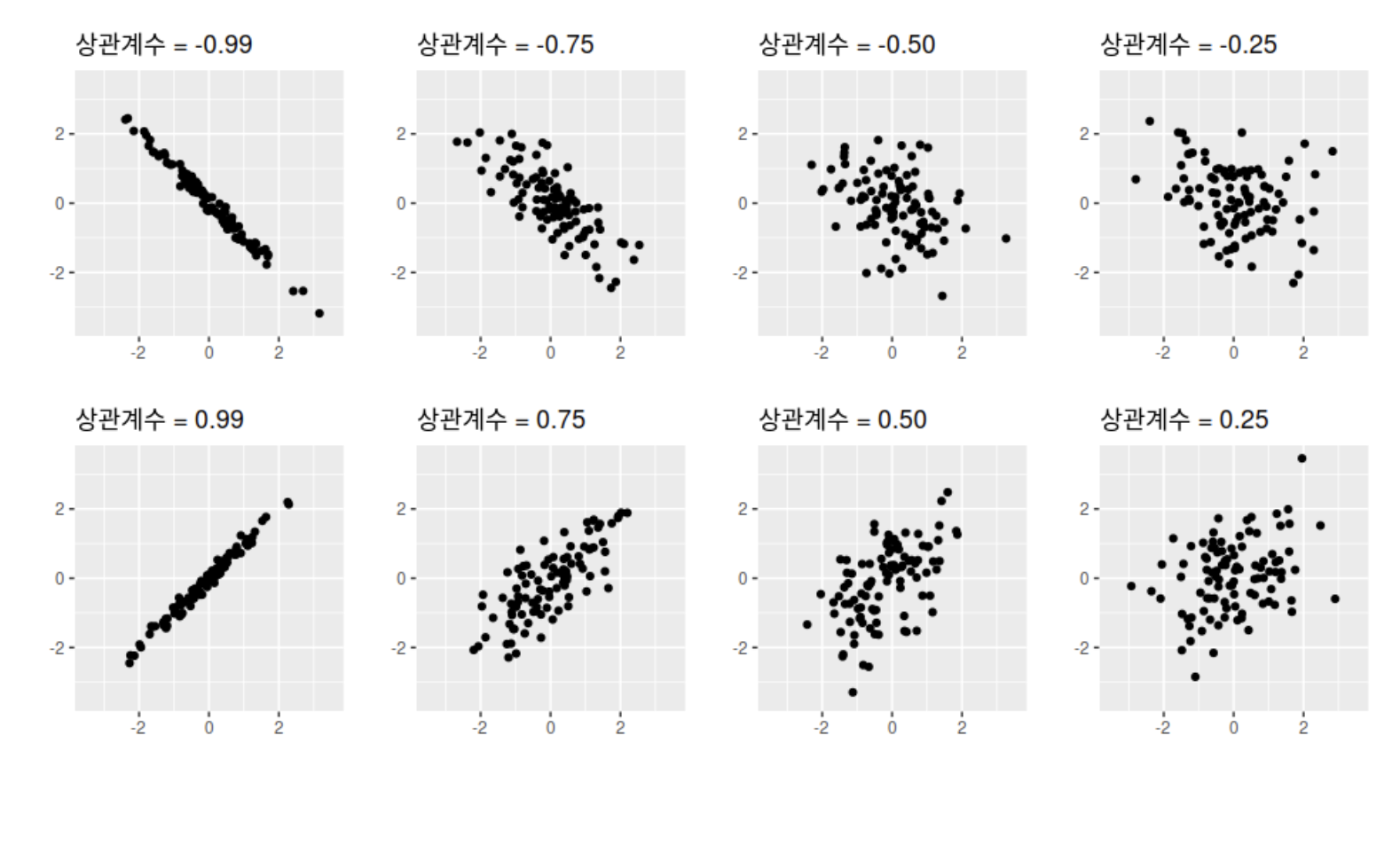
- 피어슨 상관계수는 +1과 -1 사이의 값을 가지며 다음과 같다.
- +1은 완벽한 양의 선형 상관관계
- 0은 선형 상관관계 없음
- -1은 완벽한 음의 선형 상관관계
스피어만 상관계수
- 데이터가 서열자료인 경우, 즉 자료의 값 대신 순위를 이용하는 경우의 상관계수로서, 데이터를 작은 것부터 차례로 순위를 매겨 서열 순서로 바꾼 뒤 순위를 이용해 상관계수를 구한다.
- 두 변수 간의 연관 관계가 있는지 없는지를 밝혀 주며 자료에 이상점이 있거나 표본크기가 작을 때 유용하다.
- 크기 순으로 정한 두 변수의 차이가 클수록 스피어만 상관계수의 값은 커진다.
- 스피어만 상관계수가 1에 가까울수록 두 변수는 단조적 상관성을 가지는 것이고
- 0에 가까우면 상관성이 없는 것으로 판단할 수 있다.
3. 기초통계량의 추출 및 이해
자료를 수집하여 요약, 정리하는 기초통계는 자료의 특성을 정량적인 수치에 의해서 나타내는 방법이다.
중심과경향, 퍼짐 정도, 자료의 분포형태 등의 수치적 결과로 나타낼 수 있다.
3-1) 중심화 경향 기초통계량
산술평균(Arithmetic Mean)
- 모든 자료들을 합한 후 전체 자료수로 나누어 계산하는 일반적인 평균을 의미
- 모평균: 모집단 전체 자료의 산술평균
기하평균(Geometric Mean)
- N개의 자료에 대해서 관측치를 곱한 후 n 제곱근으로 표현
- 다기간의 수익률에 대한 평균 수익률, 평균물가상승률 등을 구할 때 사용한다.
- 즉 비율을 성격을 가질 때 사용
조화평균(Harmonic Mean)
- 각 요소의 역수의 산술평균을 구한 후 다시 역수를 취하는 형태로 표현
중앙값(Median)
- 중앙값은 자료를 크기 순으로 나열할 때 가운데에 위치한 값
최빈값(Mode)
- 가장 노출 빈도가 높은 자료를 최빈값이라 한다.
분위수(Quantile)
- 자료의 위치를 표현하는 수치
3-2) 산포도(분산도, Degree Dispersion)
자료의 퍼짐 정도를 나타내는 기초 통계량이다.
중심 경향도 수치에서 자료가 얼마나 떨어져 있는지를 측정하는 척도로 필요하다.
- 분산(Variance)
- 분산은 평균을 중심으로 밀집되거나 퍼짐 정도를 나타내는 척도
- 자료값의 단위를 제곱한 단위를 사용
- 특이점에 매우 큰 영향을 받는다.
- 표준편차(Standard Deviation)
- 표준편차는 분산의 제곱근으로 표현
- 분산으로 얻은 수치를 해석하기가 곤란하다는 단점을 보완하기 위해 제곱근을 취한 척도가 표준편차이다.
- 범위(range)
- 데이터 간의 최댓값과 최솟값의 차이를 나타내는 것으로 동일한 범위를 갖더라도 자료의 분포모양은 다를 수가 있음을 유의해야 한다.
- 평균 절대 편차(평균 편차, 절대 편차, MAD: Mean Absolute Deviation)
- 각 자료값과 표본평균과의 편차의 절댓값에 대한 산술평균을 의미한다.
- 편차는 유클리안 거리개념이며 특정 대푯값으로 떨어진 거리를 의미한다.
- 절대 편차는 미분 불가능점이 존재
- 평균 절대 편차보다는 중앙값 절대 편차를 사용할 때 유용할 수 있다.
- 사분위범위 (Interquartile Range, IQR)
- 자료의 크기를 *크기 순으로 배열 후 1/4에 해당하는 1사분위수(Q1)을 구하고
- 3/4에 해당하는 3사분위수(Q3)를 구한다.
- 사분위범위는 Q3 - Q1 으로 정의되며 자료의 50% 범위 내에 위치하게 된다.
- Q1 = 하위 25%
- Q3 = 상위 75%
- 변동계수 (Coefficient of Variation, CV)
- 평균을 중심으로 한 상대적인 산포의 척도를 나타내는 수치
- 측정 단위가 동일하지만 평균이 큰 차이를 보이는 두 자료집단 또는 측정 단위가 서로 다른 두 자료집단에 대한 산포의 척도를 비교할 때 많이 사용된다.
- 변동계수가 클수록 상대적으로 넓게 분포를 이룬다.
3-3) 자료의 분포형태
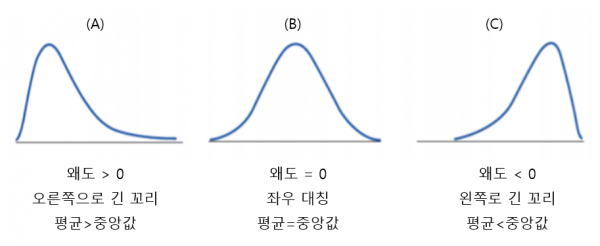
왜도(Skewness)
- 왜도는 분포의 비대칭 정도를 나타내는 통계적 측도이다.
- 분포가 대칭이면 왜도는 0이다. 왼쪽으로 치우친 경우 왜도는 양수
- 오른쪽으로 치우친 경우 왜도는 음수이다.
- 왜도는 분포의 모양 뿐 아니라 이상치의 존재 여부를 파악하는 데에도 도움을 줄 수 있다.
피어슨 비대칭 계수
- 피어슨 비대칭 계수는 칼 피어슨이 비대칭도 측정을 위해 제안한 간단한 계산법으로
- 일반적으로 왜도와 비슷하게 분포가 좌우로 얼마나 대칭적인지를 나타내는 통계값이다.
- 피어슨 비대칭 계수는 다음과 같이 정의된다.
- (평균 - 최빈값) / 표준편차
- 3*(평균 - 최빈값) / 표준편차
- 3*(평균 - 중앙값) / 표준편차
- 일반적으로 계수 값 = 3x(평균 - 중앙값) / 표준편차로 구할 수 있다.
| 조건 | Cs 값 | 치우침 | 특징 요약 |
|---|---|---|---|
| 평균 = 중앙값 = 최빈값 | Cs = 0 | 정규분포 | 대칭 분포 |
| 평균 > 중앙값 | Cs > 0 | 왼쪽으로 치우침 | 오른쪽 꼬리가 길다 (Right-skewed) |
| 평균 < 중앙값 | Cs < 0 | 오른쪽으로 치우침 | 왼쪽 꼬리가 길다 (Left-skewed) |
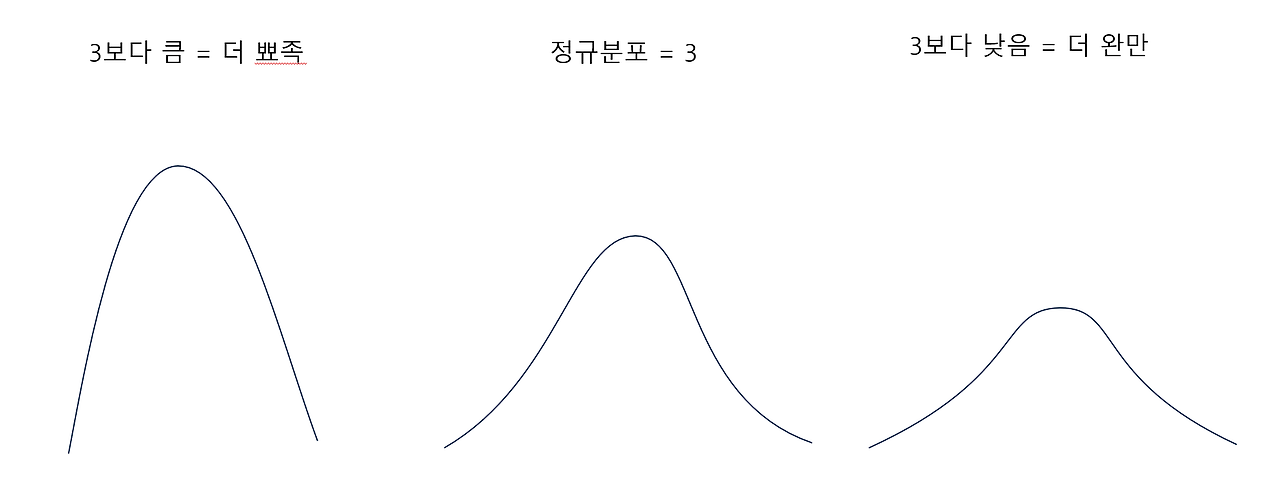
첨도(Kurtosis)
- 분포의 뾰족한 정도를 나타내는 통계적 척도이다.
- 첨도의 값이 3 미만인 경우는 평평한 분포이고
- 3이면 정규분포를 나타낸다.
- 3이 넘는 경우는 뾰족한 분포의 형태를 가지는 것으로 판단할 수 있다.
02. 고급 데이터 탐색
1. 다변량 데이터 탐색
다변량 데이터 탐색은 기본적으로 변수들 간 인과관계의 규명과 분석을 하는 것이다.
변수들 간의 상관관계를 이용하여 변수를 축약하거나 개체들을 분류하고 관련된 분석방법 등을 동원하여 데이터 분석을 하는 것이다.
1-1) 종속변수와 독립변수 사이의 인과 관계
1. 다중회귀(Multiple Regression)
- 독립변수가 2개 이상인 회귀모형을 지칭하며 각 독립변수는 종속변수와 선형관계에 있음을 가정한다.
- 장점
- 변수를 추가하여 분석내용의 질적 향상을 도모할 수 있다.
- 편이를 제거할 수 있다.
- 일반형식
- 종속변수 Y에 대해서 $ X_1, X_2, \cdots, X_k $의 독립변수 k개가 존재하여 종속변수를 설명
- 기본 가정
- 회귀모형은 모수에 대해 선형인 모형이다.
- 오차항의 평균은 0이다.
- 오차항의 분산은 모든 관찰치에 대해 일정한 분산을 갖는다.
2. 로지스틱 회귀(Logistic Regression)
- 선형 결합을 이용하여 사건의 발생 가능성을 예측하는 데 사용하는 통계 기법이다.
- 종속변수가 이항형 문제를 지칭할 때 사용
- 특징
- 종속변수와 독립변수 사이의 관계에서 선형 모델과 차이점을 지니고 있다.
- 첫 번째 이항형인 데이터에 적용했을 때 종속변수 y의 결과가 [0, 1]로 제한된다.
- 두 번째 종속변수가 이진적이기 떄문에 조건부 확률의 분포가 정규분포 대신 이항 분포를 따른다는 점이다.
3. 분산분석(ANOVA-분석)
3개 이상의 표본들의 차이를 표본평균 간의 분산과 표본 내의 관측치간 분산을 비교하여 가설을 검정하는 것이다.
- 일원분산분석(One-Way ANOVA): 단하나의 인자에 근거하여 여러 수준으로 나누어지는 분석
- 일원분산분석 특징
- 종속변수에 대한 평균치의 차이를 검정하는 데 이용한다.
- 종속변수와 정수값을 갖는 요인변수가 각 하나여야하고 요인변수가 정의되어야 한다.
- ex: A, B, C 반 간 성적의 평균 차이가 존재할 것이다.
4. 다변량 분산분석(Multi Variate ANOVA)
측정형 변수, 종속변수가 2개 이상인 분산분석이다.
- 이원분산분석(Two-Way-ANOVA): 두 개 이상의 인자에 근거하여 여러 수준으로 나누어지는 분석
- 이원분산분석 특징
- 이원분산분석은 일원분산분석과는 달리 독립변수인의 수가 둘이다.
- ex: 성별변수와 연령변수에 따라 직무만족도가 어떻게 차이가 나는가?
1-2) 변수축약
1. 요인 분석(Factor Analysis)
다수의 변수들의 상관관계를 분석하여 공통차원들을 통해 축약해 나가는 방법
즉, 다수의 변수들 간 정보손실을 최소화하면서 소수의 요인으로 축약하는 것
- 요인 분석 특징
- 독립변수와 종속변수의 개념이 없다.
- 추론통계가 아닌 기술통계기법에 의해 수행할 수 있다.(상관분석 등)
- 요인 분석의 목적
- 변수 축소: 여러 개의 관련변수가 하나의 요인으로 묶인다.
- 변수 제거: 요인에 포함되지 않거나 포함되더라도 중요도가 낮은 변수를 찾을 수 있다.
- 변수 특성 파악: 관련된 변수들의 묶음으로 상호독립특성을 파악하기 용이해진다.
- 측정항목의 타당성 평가: 그룹이 되지 않은 변수의 특성을 구분할 수 있게 된다.
- 요인점수를 통한 변수 생성: 회귀분석, 군집분석, 판별분석 등에 적용 가능한 변수를 생성할 수 있다.
2. 정준상관분석(Canonical Analysis)
두 변수집단 간의 연관성을 각 변수집단에 속한 변수들의 선형결합의 상관계수를 이용하여 분석하는 방법
- 정준변수: 새로 만들어진 선형결합이다.
- 정준상관계수: 정준변수들 사이의 상관계수
- 정준분석과 회귀분석의 차이점
- 회귀분석의 경우 하나의 반응변수를 여러 개의 설명변수로 설명하고자 할 때
- 가장 설명력이 높은 변수들의 선형결합을 찾아 이들 사이의 인과관계를 생각하는 반면
- 정준분석에서는 이와 같은 인과성이 없다.
1-2) 개체유도
개체들의 특성을 측정한 변수들의 상관관계를 이용하여 유사한 개체를 분류하는 방법이다.
1. 군집분석(Cluster Analysis)
변수 또는 개체 들이 속한 모집단 또는 범주에 대한 사전정보가 없는 경우에 관측값들 사이의 거리(또는 유사성)를 이용하여 변수 또는 개체들을 자연스럽게 몇 개의 그룹 또는 군집(Cluster)으로 나누는 분석기법이다.
군집 간의 거리에 대한 정의가 가장 중요한 부분으로 거리의 정의에 따라서 유사성에 대한 척도가 형성
계층적 방법
- 가까운 개체끼리 차례로 묶거나 멀리 떨어진 개체를 차례로 분리해 가는 군집방법
- 한 번 병합된 개체는 다시 분리되지 않는 것이 특징이다.
- 비계층적 방법 또는 최적분화 방법
- 다변량 자료의 산포를 나타내는 여러가지 측도를 이용하여 이들 판정기준을 최적화시키는 방법
- 한 번 분리된 개체도 반복적으로 시행하는 과정에서 재분류될 수 있는 것이 특징
- 그래프를 이용하는 방법
- 다차원 자료들을 2차원 또는 3차원으로 축소할 수 있다면 시가적 차원에서 자연스러운 군집을 형성
2. 다차원 척도법(MDS)
- 차원의 축소와 개체들의 상대적 위치 등을 통해 개체들 사이의 관계를 쉽게 파악
- 공간적 배열에 대한 주관적인 해석에 중점을 두고 있다.
3. 판별 분석
2개 이상의 그룹으로 나누어진 개체에 대해 분류에 영향을 미칠 것 같은 특성을 측정하고 이를 이용하여 새로운 개체를 분류하는 방법이다.
- 로지스틱 판별분석: 분류하는 도구를 로지스틱 회귀분석을 이용하여 분류하는 방법이다.