[빅분기] 필기 Chapter 04. 데이터 전처리
[빅데이터분석기사] 필기 'Chapter 04. 데이터 전처리' 내용을 정리했습니다.

[빅분기] 필기 Chapter 04. 데이터 전처리
들어가며
빅데이터분석기사 필기 시험을 준비하며 공부한 내용을 Chapter 별 핵심 내용 기준으로 정리한 내용입니다.
교재는 이기적-빅데이터분석기사 필기-2024로 공부했습니다.
01. 데이터 정제
1. 데이터에 내재된 변수의 이해
빅데이터 분석이나 전통적 통계분석을 통해 원하는 결과를 얻기 위해서는 모든 근간이 되는 자료의 이해가 필수다. 여기서는 자료에 대한 엄밀한 정의와 관련된 내용에 대해 다룬다.
1-1) 데이터 관련 정의
- 데이터: 이론을 세우는 기초가 되는 사실 또는 자료를 지칭
- 단위: 관찰되는 항목 또는 대상을 지칭
- 관측값: 각 조사 단위별 기록정보 또는 특성을 말한다.
- 변수: 각 단위에서 측정된 특성 결과
- 원자료: 표본에서 조사된 최초의 자료를 이야기한다.
1-2) 데이터의 종류
- 단변량자료: 자료의 특성을 대표하는 특성 변수가 하나인 자료
- 다변량자료: 자료의 특성을 대표하는 특성 변수가 두 가지 이상인 자료
- 직적자료: 정성적 또는 범주형 자료라고도 하며, 자료를 범주의 형태로 분류
- 수치자료: 정량적 또는 연속형 자료라고도 한다. 숫자의 크기에 의미를 부여할 수 있는 자료를 나타내며 구간자료, 비율자료가 여기에 속한다.
- 시계열자료: 일정한 시간간격 동안에 수집된, 시간개념ㄴ이 포함되어 있는 자료
- 횡적자료: 횡단면자료라고도 하며 특정 단일 시점에서 여러 대상으로부터 수집된 자료이다.
- 종적자료: 시계열자료와 횡적자료의 결합으로 여러 개체를 여러 시점에서 수집한 자료
1-3) 데이터의 정제
- 집계
- 데이터를 요약하거나 그룹화하여 통계적 정보를 얻는 과정
- 합계, 평균, 중앙값, 최빈값, 최소/최대값, 분산과 표준편차 등을 이용하여 데이터의 특성을 파악
- 일반화
- 데이터 변환 과정에서 일반적인 특성이나 패턴을 추출하는 작업
- 복잡성을 감소시키고 중요한 특징을 강조
- 일관된 분석 및 예측을 가능하게함
- 정규화
- 일정한 범위로 조정하여 상대적인 크기 차이를 제거하고 표준화하는 작업
- 일반적으로 수치형 데이터에 적용하며, 분석과 모델링에 적용하기 쉽게 한다.
- Min-Max 정규화, Z-score 정규화 등과 같은 방법을 사용
- 평활화
- 데이터의 변동을 줄이고 노이즈를 제거하여 데이터의 추세나 패턴을 부드럽게 만드는 기술
- 시계열 분석, 데이터 시각화, 데이터 예측 등 다양한 분야에서 사용
- 이동평균법, 지수평활법, Savitzky-Golay 필터법 등이 있다.
2. 데이터 결측값 처리
데이터 결측값 처리
- 결측치를 임의로 제거 시: 분석 데이터의 직접손실로 분석에 필요한 유의수준 데이터 수집에 실패할 가능성 발생
- 결측치를 임의로 대체 시: 데이터의 편향이 발생하여 분석 결과의 신뢰성 저하 가능성이 있다.
결측 데이터의 종류
- 완전 무작위 결측
- 어떤 변수상에서 결측 데이터가 관측된 혹은 관측되지 않는 다른 변수와 아무런 연관이 없는 경우
- 무작위 결측
- 변수상의 결측데이터가 관측된 다른 변수와 연관되어 있지만 그 자체가 비관측값들과는 연관되지 않은 경우
- 비 무작위 결측
- 변수의 결측 데이터가 완전 무작위 결측 또는 무작위 결측이 아닌 결측데이터로 정의하는 즉 결측변수값이 결측여부와 관련이 있는 경우
- ex: 지역 가구소득 조사 시 소득이 적은 가구에 대한 소득값 결측이 쉽다.
- (소득이 적은 가구는 소득을 밝히기 싫어함을 가정)
3. 데이터의 이상값 처리
데이터의 이상값 처리
- 이상치란 데이터 전처리 과정에서 발생 가능한 문제로 정상의 범주에서 벗어난 값을 의미
- 이상치는 앞선 결측치와 마찬가지로 분석결과에 왜곡이 발생할 수 있으므로 처리하는 작업 필요
- 이상치의 종류
- 단변수 이상치: 하나의 데이터 분포에서 발생하는 이상치를 말함
- 다변수 이상치: 복수의 연결된 데이터 분포공간에서 발생하는 이상치를 의미
- 이상치 발생 원인
- 비자연적 이상치 발생
- 입력실수: 데이터 수집과정에서 발생하는 에러로 입력의 실수 등을 지칭
- 측정오류: 데이터의 측정 중에 발생하는 에러로 측정기 고장으로 발생되는 문제
- 실험오류: 실험과정 중 발생하는 에러로 실험환경에서 야기된 모든 문제점을 지칭
- 의도적 이상치: 자기 보고 측정에서 발생되는 이상치를 지칭
- 자료처리오류: 복수 개의 데이터셋에서 데이터를 추출, 조합하여 분석 시 분석 전의 전처리에서 발생
- 표본오류: 모집단에서 표본을 추출하는 과정에서 편향이 발생하는 경우를 지칭
- 자연적 이상치
- 상기 경우 이외에 발생하는 이상치들을 자연적 이상치라고 한다.
- 비자연적 이상치 발생
- 이상치의 문제점
- 기초 통계 분석결과의 신뢰도 저하: 평균, 분산 등에 영향을 준다. 단 중앙값은 영향이 적다.
- 고급 통계분석의 신뢰성 저하: 검정, 추정 등의 분석, 회귀분석 등이 영향을 받는다.
- 이상치의 탐지
- 시각화를 통한 방법
- Box plot: 최솟값, 최댓값, 중앙값, 1사분위수(Q1), 3사분위수(Q3) 등을 표현
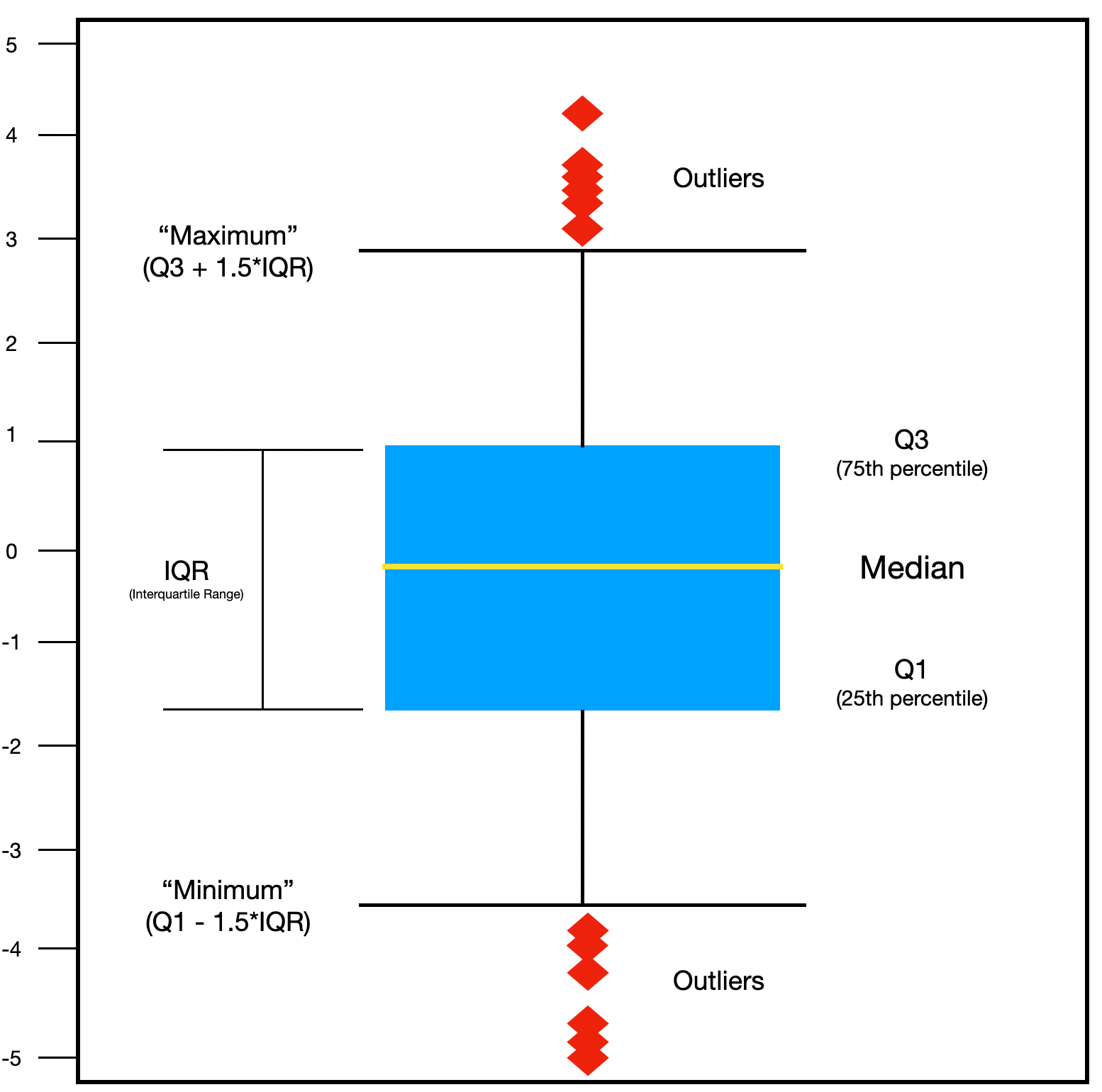
- Scatter plot: 두 변수로 이루어진 데이터를 2차원 평면 상에 점으로 표현하는 시각화 방법
- Box plot: 최솟값, 최댓값, 중앙값, 1사분위수(Q1), 3사분위수(Q3) 등을 표현
- Z-score 방법
- Z-score는 포인트가 평균으로부터 얼마나 떨어져 있는지를 표준편차의 단위로 나타내는 통계적 지표
- 탐지 방법
- 평균이 0이고 표준편차가 1인 표준정규분포로 변환
- 이를 위해 각 데이터에서 평균을 뺴고, 표준편차로 나누어 줌
- 정규화된 데이터 포인트의(x)의 Z-score를 계산
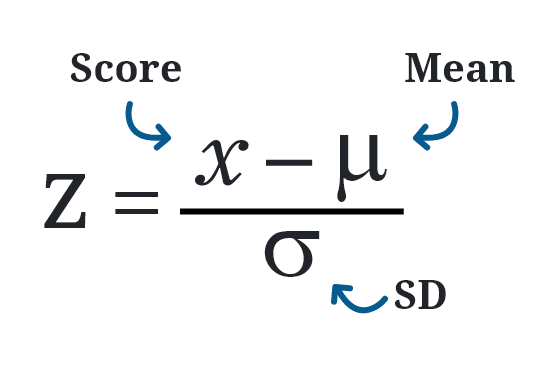
- 정규분포를 따른다고 가정할때 효과적으로 작동
- 비정규분포를 따르는 경우 잘못된 결과를 도출할 수 있어 주의 필요
- 시각화를 통한 방법
02. 분석 변수 처리
1. 변수 선택
통계적 분석 결과의 신뢰성을 위해 기본적으로 데이터와 이를 특정 짓는 변수는 많으면 좋다.
하지만 분석모형을 구성하고 사용하는데 지속적으로 필요 이상의 많은 데이터를 요구할 수 있다.
- 회귀(Regression): 변수 x와 y의 관계를 함수식으로 설명하는 통계적 방법
- 상관계수: 두 변수 간 연관성, 상관관계의 정도를 나타내는 수치
1-1) 변수별 모형의 분류
- 전체 모형: 모든 독립변수를 사용한 모형으로 정의
- 축소 모형: 전체 모형에서 사용된 변수의 개수를 줄여서 얻은 모형
- 영 모형: 독립변수가 하나도 없는 모형을 의미
1-2) 변수의 선택 방법
- 전진 선택법
- 영 모형에서 시작, 모든 독립변수 중 종속변수와 단순상관계수의 절댓값이 가장 큰 변수를 분석모형에 포함시키는 것을 말한다.
- 한번 추가된 변수는 제거하지 않는 것이 원칙
- 후진 선택법, 후진 소거법
- 전체모델에서 시작, 모든 독립변수 중 종속변수와 단순상관계수의 절댓값이 가장 작은 변수를 분석 모형에서 제외시킨다.
- 한번 제거된 변수는 추가하지 않는다.
- 단계적 선택법
- 전진 선택법과 후진 선택법의 보완방법이다.
- 제거된 변수는 다시 모형에 포함하지 않으며 유의한 설명변수가 존재하지 않을 때까지 과정을 반복
2. 차원 축소
- 자료의 차원: 분석하는 데이터의 종류의 수를 의미
- 차원의 축소: 차원의 축소는 어떤 목적에 따라서 변수의 양을 줄이는 것이다.
2-1) 차원 축소의 필요성
- 복잡도의 축소
- 동일한 품질을 나타낼 수 있다면 효율성 측면에서 데이터 종류의 수를 줄여야 한다.
- ✅ ex: 설명 분산 비율
- 과적합(Overfit) 방지
- 차원증가는 분석모델 파라미터의 증가 및 파라미터 간의 복잡한 관계의 증가로 과적합 발생의 가능성이 커진다.
- 해석력 확보
- 차원이 작은 간단한 모델일수록 재부구조 이해가 용이하고 해석이 쉬워진다.
- 해석이 쉬워지면 결과 도출에 많은 도움을 줄 수 있다.
- 차원의 저주
- 분석 및 알고리즘을 통한 학습을 위해 차원이 증가하면서 학습데이터의 수가 차원의 수보다 적어져 성능이 저하되는 현상
- 해결을 위해 차원을 줄이거나 데이터 수를 늘리는 방법을 이용해야 한다.
2-2) 차원 축소의 방법
요인 분석
- 요인 분석
- 다수의 변수들 간의 상관관계를 분석하여 공통차원을 축약하는 통계분석 과정
- 요인 분석의 목적
- 변수 축소: 정보손실을 억제하면서 소수의 요인으로 축약하는 것을 말한다.
- 변수 제거: 요인에 대한 중요도 파악이다.
- 변수특성 파악: 관련된 변수들이 군집으로써 요인 간의 상호 독립성 파악이 용이
- 타당성 평가: 묶여지지 않는 변수의 독립성 여부를 판단한다.
- 파생변수: 요인점수를 이용한 새로운 변수를 생성한다
- 요인 분석의 특징
- 독립변수, 종속변수 개념이 없다. 주로 기술 통계에 의한 방법을 이용
- 요인 분석의 종류
- 주성분 분석, 공통요인 분석, 특이값 분해(SVD) 행렬, 음수미포함 행렬분해(NMF) 등이 있다.
주성분 분석(PCA)
- PCA: 분포된 데이터들의 특성을 설명할 수 있는 하나 또는 복수 개의 특징(주성분)을 찾는 것을 의미
- PCA의 특징
- 차원 축소에 폭넓게 사용된다. 어떠한 사전적 분포 가정의 요구가 없다.
- 본래의 변수들의 선형결합으로만 고려한다.
- 차원의 축소는 변수들이 서로 상관이 있을 때만 가능
- 스케일에 대한 영향이 크다. 즉 PCA수행을 위해 변수들 간의 스케일링이 필수
특이값 분해(SVD)
- SVD의 차원 축소 원리
- 수학적 원리: SVD 방법은 주어진 행렬 M을 여러 개의 행렬 M과 동일한 크기를 갖는 행렬로 분해할 수 있으며 각 행렬의 원소값의 크기는 Diagonal Matrix에서 대각성분의 크기에 의해 결정된다.
- 데이터의 응용: 큰 몇개의 특이값을 가지고도 충분히 유용한 정보를 유지할 수 있는 차원을 생성해 낼 수 있다.
음수 미포함 행렬분해(NMF)
- NMF는 음수를 포함하지 않은 행렬 V를 음수를 포함하지 않은 두 행렬의 곱으로 분해하는 알고리즘이다.
- NMF의 차원 축소: 행렬 곱셈에서 곱해지는 행렬은 결과행렬보다 훨씬 적은 차원을 가지기 때문에 NMF가 차원을 축소할 수 있다.
3. 파생변수의 생성
파생변수
- 기존의 변수를 조합하여 새로운 변수를 만들어 내는 것을 의미
- 세분화 고객행동예측, 캠페인반응예측 등에 활용할 수 있다.
- 특정상황에만 유의미하지 않게 대표성을 나타나게 할 필요가 있다.
요약변수
- 수집된 정보를 분석에 맞게 종합한 변수
- 데이터 마트에서 가장 기본적인 변수다.
- 많은 분석 모델에서 공통으로 사용될 수 있어 재활용성이 높다.
요약변수 VS 파생변수
- 요약변수 처리시의 유의점
- 처리 방법에 따라 결측치의 처리 및 이상값 처리에 유의
- 파생변수 생성 및 처리의 유의점
- 특정 상황에만 의미성 부여가 아닌 보편적이고 전 데이터구간에 대표성을 가지는 파생변수 생성을 위해서 노력
- 파생변수의 생성방법
- 한 값으로부터 특징을 추출
- 한 레코드내의 값들을 결합
- 다른 테이블의 부가적 정보를 결합
- 다수의 필드내에서 시간 종속적인 데이터를 선택
- 레코드 또는 중요 필드를 요약
4. 변수 변환
데이터를 분석하기 좋은 형태로 바꾸는 작업을 말한다. 데이터 전처리 과정 중 하나로 간주
변수 변환의 방법
- 정규화
- 연속형 데이터 값을 바로 사용하기 보다는 정규화를 이용하는 경우가 타당
- 상대적 특성이 반영된 데이터로 변환하는 것이 필요
- 일반 정규화
- 수치로 된 값들을 여러 개 사용할 때 각 수치의 범위가 다르면 이를 같은 범위로 변환해서 사용하는 것을 일반 정규화라고 한다.
- Min-Max-Normalization
- 데이터를 정규화 하는 가장 일반적인 방법
- 모든 feafure에 최소값 0, 최대값 1로, 다른 값들은 0과 1 사이의 값으로 변환
- 이상치 영향을 많이 받는 점에 유의
- 로그변환
- 어떤 수치 값을 그대로 사용하지 않고 여기에 로그를 취한 값을 사용
- 데이터 분포의 형태가 좌측으로 치우진 경우 정규분포화를 위해 로그변환을 사용
- 역수변환
- 어떤 변수를 그대로 사용하지 않고 역수를 사용하면 오히려 선형적인 특성을 가지게 되어 의미를 해석하기가 쉬워지는 경우
- 데이터분포의 형태로 보면 극단적인 좌측으로 치우친 경우 정규분포화를 위해 역수변환 사용
- 지수변환
- 어떤 변수를 그대로 사용하지 않고 지수를 사용하면 오히려 선형적인 특성을 가지게 되어 의미를 해석하기가 쉬워지는 경우
- 분포 형태가 우측으로 치우친 경우 정규분포화를 위해 지수변환을 사용
- 제곱근변환
- 어떤 변수를 그대로 사용하지 않고 제곱근을 사용하면 오히려 선형적인 특성을 가지게 되어 의미를 해석하기가 쉬워지는 경우
- 분포 형태가 좌측으로 치우친 경우 정규분포화를 위해 제곱근변환을 사용
- Box-Cox
- Box-Cox는 데이터의 변환을 통해 정규분포에 가깝게 만들어 통계 분석 및 모델링을 용이하게 하는 통계적 방법
- 양수 데이터가 비대칭 분포를 가지고 있을 때 사용된다.
5. 불균형 데이터 처리
어떤 데이터에서 각 클래스가 갖고 있는 데이터의 양에 차이가 큰 경우, 클래스 불균형이 있다고 말한다.
5-1) 불균형 데이터의 문제점
- 데이터 클래스 비율이 너무 차이가 나면 단순히 우세한 클래스를 택하는 모형의 정확도가 높아지므로 모델의 성능판별이 어려워진다.
- 즉 정확도가 높아도 재현율이 급격히 낮아지는 현상이 발생할 수 있다.
5-2) 불균형 데이터의 처리 방법
- 가중치 균형 방법
- 손실(loss)을 계산할 때 특정 클래스의 데이터에 더 큰 loss 값을 갖도록 하는 방법
- 고정 비율 이용
- 클래스의 비율에 따라 가중치를 두는 방법
- ex: 클래스의 비율이 1:5 라면 가중치를 5:1로 줌으로 전체 손실에 동일하게 기여하도록 할 수 있다.
- 최적 비율 이동
- 분야와 최종 성능을 고려해 가중치 비율의 최적 세팅을 찾으면서 가중치를 찾아가는 방법
- 언더샘플링 과 오버샘플링
- 언더샘플링
- 일부만을 선택하고 소수클래스는 최대한 많은 데이터를 사용하는 방법
- 대표클래스 데이터가 원본 데이터와 비교해 대표성이 있어야 한다.
- 오버샘플링
- 소수클래스의 복사본을 만들어 대표클래스의 수만큼 데이터를 만들어 주는 것
- 똑같은 데이터를 그대로 복사기 떄문에 새로운 데이터는 기존 데이터와 같은 성질을 갖게 된다.
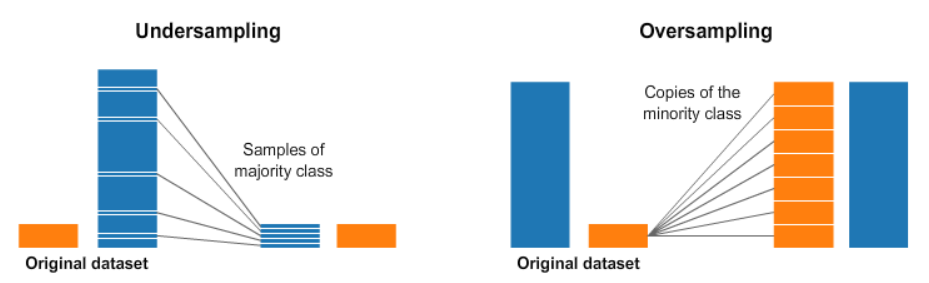
- 언더샘플링
6. 인코딩
범주형 데이터를 수치형 데이터로 변환하여 머신러닝 모델에 적용 가능하게 하는 기법
- 레이블 인코딩(label Encoding)
- 순차적인 정수 레이블을 할당하여 데이터를 변환하며 주로 순서나 크기에 의미가 없는 범주형 데이터를 변환할 때 사용
- ex: 옷의 크기를 표현하는 ‘S’, ‘M’, ‘L’ 과 같은 데이터를 레이블 인코딩으로 변환할 수 있다.
- 순서나 계층 구조가 있는 데이터에는 다른 인코딩 기법을 고려해야 한다.
- 원-핫 인코딩(One-Hot Encoding)
- 원-핫 인코딩은 각 범주에 대해 해당하는 인덱스만 1이고 나머지는 0인 이진 벡터로 변환
- ex: ‘사과’, ‘바나나’, ‘딸기’와 같은 과일 종류를 원-핫 인코딩으로 변환하면 다음과 같이 변환된다.
- 사과: [1, 0, 0]
- 바나나: [0, 1, 0]
- 딸기: [0, 0, 1]
- 타킷 인코딩(Target Encoding)
- 타깃 인코딩은 주로 분류 문제에서 사용된다.
- 각 범주에 대한 종속 변수(타깃)의 평균 값을 인코딩으로 사용하는 방식
- 과적합의 가능성이 있으며, 훈련 데이터에만 적용되어야 한다.
- 따라서 교차검증 등을 통해 적절한 평균 값을 계산하고 적용하는 과정이 필요
This post is licensed under CC BY 4.0 by the author.