[Data Analyst] A/B Test
[A/B Test] Python을 활용한 A/B 테스트 실습 내용을 다룹니다.
들어가며
이번 포스팅에선 A/B Test(A/B 테스트)에 대해 다룰 예정이다.
저번 포스팅과 마찬가지로 Python을 사용하여 A/B Test를 실제로 해보면서, 인사이트를 도출하는 방법을 알아보려한다.
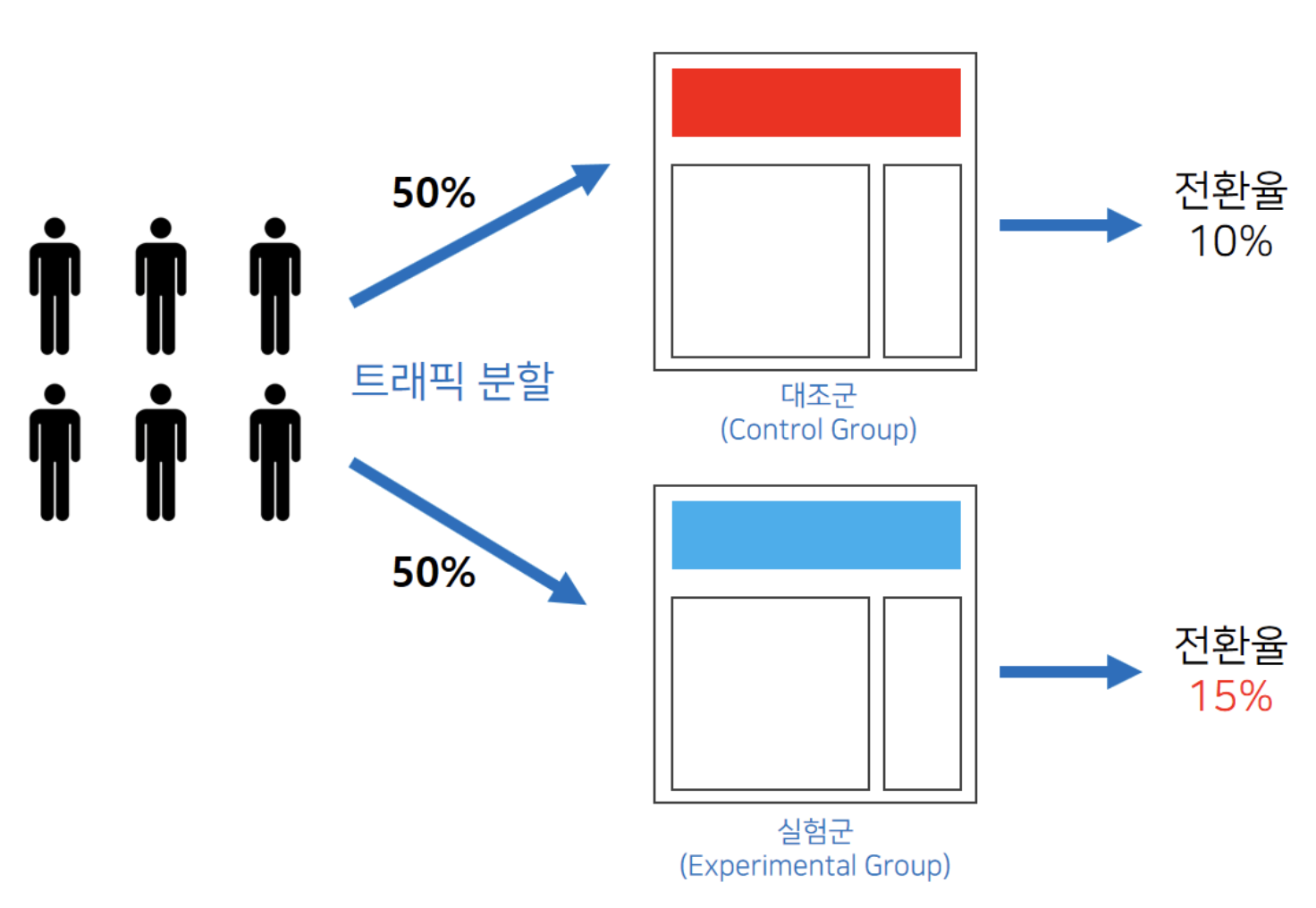
1. A/B Test란 ?
A/B Test는 두 가지 이상의 변형을 비교하여 어떤 것이 더 효과적인지를 결정하는 실험적인 방법이다.
이를 통해 사용자의 행동을 분석하고, 최적의 변형을 찾아내는데 활용된다.
A/B Test의 주요 목적
- 변형 간의 성능 비교
- 최적의 변형 식별
- 사용자 행동 인사이트 도출
- 마케팅 및 제품 전략 수립
A/B Test의 주요 단계
- 목표 설정: 실험의 목적과 기대 결과 설정
- 변형 설정: A 그룹과 B 그룹 등의 변형 설정
- 데이터 수집: 사용자 행동 데이터 추출 및 정제
- 분석: 변형 간의 성능 비교 및 최적의 변형 식별
- 결과 해석: 실험 결과를 해석하고, 다음 단계에 대한 개선 전략 수립
2. A/B 테스트 시작하기
이번 분석은 이미 수행된 A/B 테스트의 결과 데이터를 기반으로
두 그룹의 전환율 차이가 통계적으로 유의미한지를 분석하는 ’사후 분석’에 해당한다.
실제 A/B 테스트는 실험 설계 → 무작위 배정 → 데이터 수집 → 분석의 전 과정을 포함하지만
이번에는 데이터 분석 및 해석 과정에 초점을 맞추며 진행할 예정이다.
이제 A/B 테스트의 개념을 이해했으니, 실제로 Python을 사용해 A/B 테스트를 시작해 보겠다.
데이터는 캐글에 A/B Testing를 사용하여 진행했다.
아래는 A/B 테스트를 수행하는 방법을 간단히 단계별로 설명한 내용이다.
Library
1
2
3
4
5
6
7
8
9
10
11
import kagglehub
import os
import pandas as pd
import numpy as np
import warnings
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import set_matplotlib_hangul # 한글 폰트 변환
import Analysis_plot as ap # 시각화 함수
import scipy.stats as stats
Hangul OK in your MAC!
1
2
3
4
5
warnings.filterwarnings('ignore', category=FutureWarning)
# Download latest version
path = kagglehub.dataset_download("zhangluyuan/ab-testing")
print(os.listdir(path)) # 다운로드된 파일 목록 확인
Warning: Looks like you're using an outdated `kagglehub` version, please consider updating (latest version: 0.3.10) ['ab_data.csv']
1
2
3
df = pd.read_csv(os.path.join(path, 'ab_data.csv'))
# df.to_csv("../data/AB-Test.csv")
df
| user_id | timestamp | group | landing_page | converted | |
|---|---|---|---|---|---|
| 0 | 851104 | 2017-01-21 22:11:48.556739 | control | old_page | 0 |
| 1 | 804228 | 2017-01-12 08:01:45.159739 | control | old_page | 0 |
| 2 | 661590 | 2017-01-11 16:55:06.154213 | treatment | new_page | 0 |
| 3 | 853541 | 2017-01-08 18:28:03.143765 | treatment | new_page | 0 |
| 4 | 864975 | 2017-01-21 01:52:26.210827 | control | old_page | 1 |
| ... | ... | ... | ... | ... | ... |
| 294473 | 751197 | 2017-01-03 22:28:38.630509 | control | old_page | 0 |
| 294474 | 945152 | 2017-01-12 00:51:57.078372 | control | old_page | 0 |
| 294475 | 734608 | 2017-01-22 11:45:03.439544 | control | old_page | 0 |
| 294476 | 697314 | 2017-01-15 01:20:28.957438 | control | old_page | 0 |
| 294477 | 715931 | 2017-01-16 12:40:24.467417 | treatment | new_page | 0 |
294478 rows × 5 columns
Step 1: 데이터 전처리
이 데이터는 실제 A/B 테스트 결과가 담긴 데이터로서 웹사이트 개편을 두고
새로운 페이지를 일부 사용자에게 보여주고, 기존 페이지를 나머지 사용자에게 보여준 후 전환 여부를 기록한 데이터이다.
1
2
# 데이터 타입 확인
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 294478 entries, 0 to 294477 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 user_id 294478 non-null int64 1 timestamp 294478 non-null object 2 group 294478 non-null object 3 landing_page 294478 non-null object 4 converted 294478 non-null int64 dtypes: int64(2), object(3) memory usage: 11.2+ MB
1
2
# 결측치 확인
df.isna().sum()
user_id 0 timestamp 0 group 0 landing_page 0 converted 0 dtype: int64
1
2
df['timestamp'] = pd.to_datetime(df['timestamp']) # 시계열 변환
df['group'].value_counts() # 그룹별 분포
group treatment 147276 control 147202 Name: count, dtype: int64
Step 2: EDA
이제 본격적으로 A/B 테스트를 진행하기 전에, 데이터의 전반적인 특성과 핵심 지표인 ‘전환율’을 먼저 살펴보려 한다.
각 그룹별 전환율을 확인하면, 기존 페이지와 신규 페이지 간의 성과 차이를 직관적으로 파악할 수 있다.
여기서 전환율이란, 전체 방문자 중 실제 전환(구매, 회원가입)으로 이어진 비율을 의미한다.
이를 통해 두 그룹 간 기본적인 차이를 시각적으로 확인하고, 이후 통계적 검정을 위한 기초 분석 자료로 활용할 수 있다.
A/B Test에서는 이러한 EDA과정이 사전 진단 역할을 한다는 점에서 매우 중요하다.
1
2
3
4
5
6
7
8
9
10
11
12
# 그룹별 수
group_count = df['group'].value_counts().reset_index()
group_count.columns = ['group', 'count']
treatment_count = group_count[group_count['group'] == 'treatment']['count'].values[0]
control_count = group_count[group_count['group'] == 'control']['count'].values[0]
print(f"treatment 그룹 수: {treatment_count}")
print(f"control 그룹 수: {control_count}")
# 시각화
ap.bar_plot(group_count, x_col='group', y_col='count', figsize=(8, 6), title='그룹별 사용자 수', palette=['skyblue', 'salmon'])
treatment 그룹 수: 147276 control 그룹 수: 147202

- new_page인 사용자와 old_page인 사용자의 수
1
2
3
4
5
6
7
8
9
10
11
landing_page = df['landing_page'].value_counts().reset_index()
landing_page.columns = ['landing_page', 'count']
new_page = landing_page[landing_page['landing_page'] == 'new_page']['count'].values[0]
old_page = landing_page[landing_page['landing_page'] == 'old_page']['count'].values[0]
print(f"new_page 그룹 수: {new_page}")
print(f"old_page 그룹 수: {old_page}")
# 시각화
ap.bar_plot(landing_page, x_col='landing_page', y_col='count', figsize=(8, 6), title='new_page VS old_page', palette=['skyblue', 'salmon'])
new_page 그룹 수: 147239 old_page 그룹 수: 147239

- 그룹별 전환 여부
1
2
3
4
5
6
# 그룹별 전환 여부(count)
conversion_counts = df['converted'].value_counts().reset_index()
conversion_counts.columns = ['converted', 'count']
# 시각화
ap.bar_plot(conversion_counts, x_col='converted', y_col='count', figsize=(8, 6), title='전환 여부별 사용자 수', palette=['skyblue', 'salmon'])

- 날짜별 전환율 추이
1
2
3
4
5
df['date'] = df['timestamp'].dt.date
daily_conversion = df.groupby(['date', 'group'])['converted'].mean().reset_index()
# 시각화
ap.line_plot(daily_conversion, x_col='date', y_col='converted', hue='group', figsize=(10, 6), title='날짜별 전환율 추이')

- 위 EDA 결과 전체 사용자 중 전환하지 않은 사용자(0)의 비율이 절대적으로 높다는 점이 확인되었다.
- 이는, 흔히 관찰되는 현상으로, 대부분의 사용자는 단순 방문에 그치고, 실제 전환까지 이어지는 경우는 제한적이라는 패턴을 보여준다.
- 두 그룹 모두 전환율 패턴은 유사하지만, 새로운 페이지가 실제 전환율 개선에 효과적인지 검증이 필요하다.
- 결국, 그룹 간 전환율 차이가 통계적으로 유의미한지 여부가 이번 A/B 테스트의 핵심이다.
1
df.head()
| user_id | timestamp | group | landing_page | converted | date | |
|---|---|---|---|---|---|---|
| 0 | 851104 | 2017-01-21 22:11:48.556739 | control | old_page | 0 | 2017-01-21 |
| 1 | 804228 | 2017-01-12 08:01:45.159739 | control | old_page | 0 | 2017-01-12 |
| 2 | 661590 | 2017-01-11 16:55:06.154213 | treatment | new_page | 0 | 2017-01-11 |
| 3 | 853541 | 2017-01-08 18:28:03.143765 | treatment | new_page | 0 | 2017-01-08 |
| 4 | 864975 | 2017-01-21 01:52:26.210827 | control | old_page | 1 | 2017-01-21 |
Step 3: 통계적 유의성 검정
A/B 테스트의 핵심은 단순 수치 비교가 아니라, 그 차이가 우연이 아닌 통계적으로 유의미한 차이인지를 검증하는 데 있다.
연속형 지표 비교 (매출, 체류시간 등): 정규성 검정 → t-test 또는 U-test
범주형 지표 비교 (전환 여부, 클릭 여부 등): 빈도표 생성 → 카이제곱 검정 or Z-test
현재 데이터는 ‘전환 여부’가 핵심이므로 카이제곱 검정으로 진행하는 게 정석이다.
또한 위 EDA 결과 아래와 같이 가설을 세울 수 있다.
- 1.control 그룹의 전환율보다 treatment 그룹의 전환율이 더 높을 것이다.
- 2.old_page 그룹의 전환율보다 new_page 그룹의 전환율이 더 높을 것이다.
1
2
3
4
5
6
7
8
9
10
11
# 카이제곱 검정
def chi_square_test(df, group_col, target_col):
cross_table = pd.crosstab(df[group_col], df[target_col]) # 교차 table 생성
stat, p, _, _ = stats.chi2_contingency(cross_table) # 카이제곱 검증
print(f"카이제곱 통계량: {stat:.4f}, p-value: {p:.4f}")
if p < 0.05:
print("귀무가설 기각: 두 그룹 간 유의미한 차이가 있다.")
else:
print("귀무가설 기각 불가: 두 그룹 간 유의미한 차이가 없다.")
- 가설 1
1
2
3
4
group = df.groupby(['group', 'converted']).size().reset_index(name='count')
chi_square_test(df, 'group', 'converted')
ap.bar_plot(group, x_col='group', y_col='count', hue='converted', figsize=(10, 6), title='그룹 별 전환율 비교')
카이제곱 통계량: 1.5160, p-value: 0.2182 귀무가설 기각 불가: 두 그룹 간 유의미한 차이가 없다.

- 가설 2
1
2
3
4
landing = df.groupby(['landing_page', 'converted']).size().reset_index(name='count')
chi_square_test(df, 'landing_page', 'converted')
ap.bar_plot(landing, x_col='landing_page', y_col='count', hue='converted', figsize=(10, 6), title='그룹 별 전환율 비교')
카이제곱 통계량: 1.8568, p-value: 0.1730 귀무가설 기각 불가: 두 그룹 간 유의미한 차이가 없다.

결론
위 검증 결과 p-value < 0.05 임으로 두 그룹 모두 유의미한 차이가 없다.
따라서, 기존 웹 페이지를 유지하거나, 새로운 웹 페이지를 만들어야한다고 볼 수 있다.
마무리
이번 분석은 이미 수행된 A/B 테스트의 결과 데이터를 기반으로 두 그룹의
전환율 차이가 통계적으로 유의미한지를 검증하는 사후 분석(Post-hoc Analysis)을 진행한 사례다.
A/B 테스트는 보통 실험 설계 → 무작위 배정 → 데이터 수집 → 데이터 분석 및 해석의 전체 과정을 포함하지만
이번에는 주어진 데이터를 활용한 분석 및 해석 과정에 집중했다.
이번 포스팅을 마지막으로, 데이터 분석에서 자주 활용되는 핵심 방법론들을 정리해보았다.
앞으로는 실전 비즈니스 데이터에 적용할 수 있는 고급 분석 기법과
분석 결과를 비즈니스 인사이트로 연결하는 과정을 주제로 더 깊이 있는 내용을 다룰 예정이다.